






文章目录
功能
本项目旨在实现一个文件管理工具,主要功能是删除磁盘中的重复文件。如何判定两个文件是否完全一致,采用计算文件指纹的方法,所谓的文件指纹即数字签名。
实现过程
(一) 计算文件指纹(了解MD5算法实现)
MD5是由Ron Rivest在1991设计的一种 信息摘要(message-digest ) 算法,当给定任意长度的信息,MD5会产生一个固定的128位 “指纹”或者叫信息摘要。从理论的角度,所有的信息产生的MD5值都不同,也无法通过给定的MD5值产生任何信息,即不可逆。MD5算法在RFC 1321(Request For Comments,征求修正意见书)做了详细描述。
MD5功能特点
1.输入任意长度的信息,经过处理,输出为128位的信息(数字指纹)
2.不同的输入得到的不同的结果(唯一性)。要使两个不同的信息产生相同的摘要,操作数量级在2^64次方。
3.根据128位的输出结果不可能反推出输入的信息。根据给定的摘要反推原始信息,它的操作数量级在2^128次。
MD5算法步骤
1. 添加填充位
信息的最尾部(不是每一块的尾部)要进行填充,使其最终的长度length(以bit为单位)满足length % 512 = 448,这一步始终要执行,即使信息的原始长度恰好符合上述要求。
填充规则:第一个bit填充位填 ‘1’ ,后续bit填充位都填 ‘0’ ,最终使消息的总体长度满足上述要求。总之,至少要填充 1 bit,至多填充 512 bit。
2.添加bit长度
在上一步之后,添加一个64bit大小的length,length表示原始消息(未填充之前)的bit长度,极端情况,如果消息长度超过2^64, 那么只使用前2^64bit消息。
这一步完成之后,消息的最终长度变为(length + 64) % 512 = 0,即length为512的整数倍。从这里再去看第一步,至少需要填充 8 bit,为什么?我们假设几种情况分析一下:
首先要明确一个字符占1byte(8bit, 中文字符的话占16bit),所以原始信息bit长度一定是8的倍数。
- 假设1:消息原始长度 % 512 = 448
这时候原始长度符合要求,但是根据填充规则,仍然要至少填1bit的 ‘1’,后面还剩63bit,不够添加长度,所以需要再加一块数据(512bit),这样后面63bit填0,新加的数据前448bit填0,最后64bit填数据原始长度,一定要记住长度值是放在最后一块数据的最后64bit。

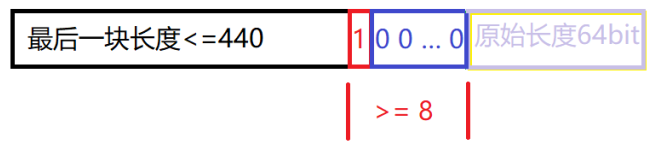
- 假设2:消息原始长度 % 512 < 448
此时最后一块数据长度不大于440bit,最后64bit填数据长度,需要填充的bit数不小于8。
- 假设3:消息原始长度 % 512 > 448
此时最后一块数据长度不小于456,最多504,剩余bit不够添加64位长度,和假设1相同,需要增加一块数据,最后64位添加长度,其余填充0。

3. 初始化MD buffer
用4-word buffer(A, B, C, D)计算摘要,这里A,B,C,D各为一个32bit的变量,这些变量初始化为下面的十六进制值,低字节在前。MD5算法根据文件数据来更新A,B,C,D的值,最终根据这4个值得出唯一的字符串。
/*
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
*/
// 初始化A,B,C,D
_A = 0x67452301;
_B = 0xefcdab89;
_C = 0x98badcfe;
_D = 0x10325476;
4. 按512位数据逐块处理输入信息
512bit数据为一个处理单位,暂且称为一个数据块chunk,每个chunk经过4个函数(F, G, H, I)处理,这四个函数输入为3个32位(4字节)的值,产生一个32位的输出。四个函数如下所示:
F(x,y,z) = (x & y) | ((~x) & z)
G(x,y,z) = (x & z) | ( y & (~z))
H(x,y,z) = x ^ y ^ z
I(x,y,z) = y ^ (x | (~z))
处理过程中要用一个含有64个元素的表K[1…64],表中的元素值由sin函数构建,K[i]等于2^(32) * abs(sin(i))的整数部分,即:
K[i] = floor(2^(32) * abs(sin(i + 1))) // 因为此处i从0开始,所以需要sin(i + 1)
for (int i = 0; i < 64; i++) {
_k[i] = (size_t)(abs(sin(i + 1)) * pow(2, 32));
}
512bit = 64byte * 8 = 16 * 4byte
在处理一个chunk(512bit)的数据时,会把这个chunk再细分成16组4字节数据,一个chunk经过4轮进行处理,每轮都会把chunk的所有数据处理一遍,每轮有16个相似的子操作,所以一个chunk的数据要进行64个子操作。
计算之前先保存MD buffer的当前值:
a = A, b = B, c = C, d = D
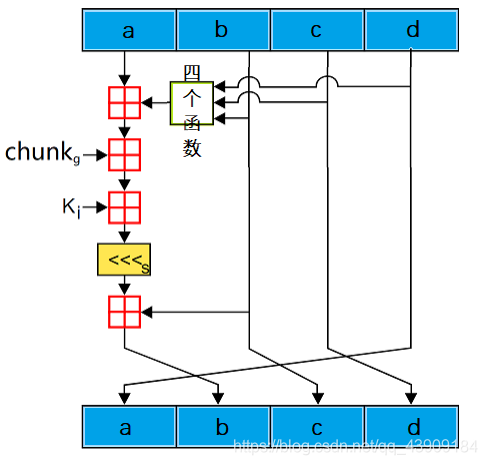
图中的<<<s表示循环左移操作。
根据上图得到四轮处理过程:
第一轮:F函数处理(0 <= i <= 15)
F = F(b, c, d)
d = c
c =b
b = b + shift((a + F + k[i] + chunk[g]), s[i])
a = d
第二轮:G函数处理 (16 <= i <= 31)
G = G(b, c, d)
d = c
c =b
b = b + shift((a + G + k[i] + chunk[g]), s[i])
a = d
第三轮:H函数处理(32 <= i <= 47)
H = H(b, c, d)
d = c
c =b
b = b + shift((a + H + k[i] + chunk[g]), s[i])
a = d
第四轮:I函数处理(48 <= i <= 63)
I = I(b, c, d)
d = c
c =b
b = b + shift((a + I + k[i] + chunk[g]), s[i])
a = d
上面式子里的s[] 和 g 满足按照下面所给计算:
size_t s[] = { 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7,
12, 17, 22, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 6, 10,
15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21 };
if (0 <= i < 16) g = i;
if (16 <= i < 32) g = (5 * i + 1) % 16;
if (32 <= i < 48) g = (3 * i + 5) % 16;
if(48 <= i < 63) g = (7 * i) % 16;
一个chunk数据处理完之后,更新MD buffer的值A, B, C, D
_A = a + _A;
_B = b + _B;
_C = c + _C;
_D = d + _D;
处理完一个chunk数据块,接着处理下一块
5. 文件指纹输出
这一步拼接4个buffer(_A,_B,_C,_D)中的摘要信息,以_A中的低位字节开始,_D的高位字节结束。最终的输出是128bit摘要信息的16进制表示,故最后输出一个32长度的摘要信息。
举例:比如一个数,它的16进制表示为: 0x23456789, 他所对应的8个摘要信息为从低位字节的89开始,高位字节的23结束,即: 89674523。
MD5算法核心接口
class MD5 {
public:
MD5();
void init();
string getStringMD5(const string& str);
string getFileMD5(const char* filePath);
private:
//从文件获取的512bit的数据块
char _chunk[64];
//最后要返回的4个整型值 _A _B _C _D
uint32_t _A, _B, _C, _D;
//循环左移位数
static size_t s[64];
//中间运算式的固定变量 _k[i] = (size_t)(abs(sin(i + 1)) * pow(2, 32))
uint32_t _k[64];
//最后一块数据的字节数
uint32_t _lastByte;
//总字节数
uint32_t _totalByte;
//num循环左移n位
uint32_t leftShift(uint32_t num, int n) {
return (num << n) | (num >> (32 - n));
}
uint32_t F(uint32_t x, uint32_t y, uint32_t z) {
return (x & y) | ((~x) & z);
}
uint32_t G(uint32_t x, uint32_t y, uint32_t z) {
return (x & z) | (y & (~z));
}
uint32_t H(uint32_t x, uint32_t y, uint32_t z) {
return x ^ y ^ z;
}
uint32_t I(uint32_t x, uint32_t y, uint32_t z) {
return y ^ (x | (~z));
}
//一个chunk的MD5运算
void calMD5(const uint32_t* Chunk);
//把一个整数数据转换为一个16进制字符串
string transHex(uint32_t n);
void calFinalMD5();
};
string MD5::getStringMD5(const string& str) {
if (str.empty()) {
return transHex(_A).append(transHex(_B)).append(transHex(_C)).append(transHex(_D));
}
_totalByte = str.size();
uint32_t chunkNum = _totalByte / 64;
const char* strPtr = str.c_str();
for (int i = 0; i < chunkNum; ++i) {
memcpy(_chunk, strPtr + i * 64, 64);
calMD5((uint32_t*)_chunk);
}
//计算最后一块数据:需要填充
_lastByte = _totalByte % 64;
memcpy(_chunk, strPtr + chunkNum * 64, _lastByte);
calFinalMD5();
return transHex(_A).append(transHex(_B)).append(transHex(_C)).append(transHex(_D));
}
string MD5::getFileMD5(const char* filePath) {
ifstream fin(filePath);
if (!fin.is_open()) {
cout << filePath << " ";
perror("file open error");
return "";
}
while (!fin.eof()) {
//每次只读取一块数据(64个字节)
fin.read(_chunk, 64);
//gcount返回上次读取的字节数
//如果不是64个字节,则是最后一块数据
if (fin.gcount() != 64) {
break;
}
_totalByte += 64;
calMD5((uint32_t*)_chunk);
}
_lastByte = fin.gcount();
_totalByte += _lastByte;
calFinalMD5();
return transHex(_A).append(transHex(_B)).append(transHex(_C)).append(transHex(_D));
}
(二) 扫描文件夹
参照文档:https://www.cnblogs.com/ranjiewen/p/5960976.html
用 _findfirst 和 _findnext 查找文件
- _findfirst函数:long _findfirst(const char *, struct _finddata_t *);
第一个参数为文件名,可以用"*.*“来查找所有文件,也可以用”*.cpp"来查找.cpp文件。第二个参数是_finddata_t结构体指针。若查找成功,返回文件句柄,若失败,返回-1。 - _findnext函数:int _findnext(long, struct _finddata_t *);
第一个参数为文件句柄,第二个参数同样为_finddata_t结构体指针。若查找成功,返回0,失败返回-1。 - _findclose()函数:int _findclose(long);
只有一个参数,文件句柄。若关闭成功返回0,失败返回-1。
struct _finddata_t {
unsigned attrib;
time_t time_create;
time_t time_access;
time_t time_write;
_fsize_t size;
char name[260];
};
//不遍历子目录
void transferDir(const string& folderPath, unordered_set<string>& fileString);
//递归遍历
void dfsFolder(const string& folderPath, unordered_set<string>& fileString) {
_finddata_t FileInfo;
string strfind = folderPath + "\\*";
long Handle = _findfirst(strfind.c_str(), &FileInfo);
if (Handle == -1L) {
cout << "can not match the folder path" << endl;
exit(-1);
}
do {
if (FileInfo.attrib & _A_SUBDIR) {
if ((strcmp(FileInfo.name, ".") != 0) && (strcmp(FileInfo.name, "..") != 0)) {
string newPath = folderPath + "\\" + FileInfo.name;
dfsFolder(newPath, fileString);
}
}
else {
fileString.insert(folderPath + "\\" + FileInfo.name);
//cout << folderPath.c_str() << "\\" << FileInfo.name << endl;
}
} while (_findnext(Handle, &FileInfo) == 0);
_findclose(Handle);
}
(三) 选择数据结构(STL容器)保存重复的文件来封装文件管理工具
- 选择unordered_set容器保存当前目录下的所有文件名称
选择原因:因为文件名称既包括该文件名又包含该文件的路径,所以不可能有重复的文件名,所以不选用multiset。又因为只保存名称不注重顺序,为了提高效率,选用了底层为哈希表的unordered_set。 - 选择unordered_map保存文件名称到MD5值的映射关系
选择原因:因为名称不会重复,所以不必要选择multimap,哈希表结构的unordered_map可以提高效率。 - 选择unordered_multimap保存MD5值到文件名称的映射关系
选择原因:因为MD5值可能重复,所以要使用multimap,又使用unordered_multimap提高效率。
下述代码只给出声明未给出定义,实现函数主要注意逻辑和对熟悉几种容器的接口
class FileManager {
public:
void init();
//扫描当前目录(包括子目录)的文件
void scanFolder(const string& filePath);
//显示选项 不包括子目录
void scanFileNoR(const string& filePath);
void showRepetitiveFile();
//通过文件名删除文件
void deleteFileByName(const string& filepath);
//通过MD5值删除文件
void deleteFileByMD5(const string& md5);
//删除所有保留一个文件
void deleteFileRemainOne(const string& md5, const string& filename);
//删除所有重复文件
void deleteAllRepetitive();
private:
unordered_set<string> _filename;
//filename ---> MD5
unordered_map<string, string> file_MD5;
//MD5 ---> filename
unordered_multimap<string, string> MD5_file;
MD5 _md5;
};
(四) 最后制作菜单选项并与管理工具接口关联
class menu {
public:
char init() {
cout << "******************************************************" << endl;
cout << "\t\t管理重复内容的文件工具" << endl;
cout << "\t\t 1. 扫描当前目录下文件" << endl;
cout << "\t\t 2. 递归扫描当前目录下所有文件" << endl;
cout << "******************************************************" << endl;
cout << "请选择:" << endl;
char c = getchar();
char tmp = getchar();
return c;
}
void press(const char& c) {
string dir;
if (c == '1') {
cout << "请输入要扫描的目录路径 : " << endl;
getline(cin, dir);
fmer.scanFileNoR(dir);
} else if(c == '2') {
cout << "请输入要扫描的目录路径 : " << endl;
getline(cin, dir);
fmer.scanFolder(dir);
} else {
cout << "违规操作, 请重新选择" << endl;
char ch = init();
press(ch);
}
}
char deletOptions() {
cout << endl << " 删除选项" << endl;
cout << "\t 1. 打印所有相同文件" << endl;
cout << "\t 2. 通过文件名删除文件" << endl;
cout << "\t 3. 通过MD5删除文件(随机保留一个文件)" << endl;
cout << "\t 4. 通过MD5删除文件(选择要保留的文件)" << endl;
cout << "\t 5. 删除所有重复文件" << endl;
cout << "\t 6. 返回上一级" << endl;
cout << "请选择:" << endl;
char c = getchar();
char tmp = getchar();
return c;
}
void deletPress(const char& c) {
string filename;
string md5;
char re;
switch (c) {
case '1' :
fmer.showRepetitiveFile();
re = deletOptions();
deletPress(re);
break;
case '2' :
cout << "请输入要删除的文件名:" << endl;
getline(cin, filename);
fmer.deleteFileByName(filename);
break;
case '3' :
cout << "请输入要删除的MD5值:" << endl;
getline(cin, md5);
fmer.deleteFileByMD5(md5);
break;
case '4' :
cout << "请输入要删除的MD5值:" << endl;
getline(cin, md5);
cout << "请输入要保留的文件名:" << endl;
getline(cin, filename);
/*debug
for (const auto& e : fmer.MD5_file) {
cout << e.first << "---" << e.second << endl;
}
*/
fmer.deleteFileRemainOne(md5, filename);
/*
for (const auto& e : fmer.MD5_file) {
cout << e.first << "---" << e.second << endl;
}
*/
break;
case '5' :
fmer.deleteAllRepetitive();
break;
case '6' :
break;
default:
cout << "输入违规, 请重新输入" << endl;
re = deletOptions();
deletPress(re);
break;
}
return;
}
private:
FileManager fmer;
};
int main() {
while (1) {
menu m;
char c = m.init();
m.press(c);
char ch = m.deletOptions();
m.deletPress(ch);
system("cls");
}
return 0;
}
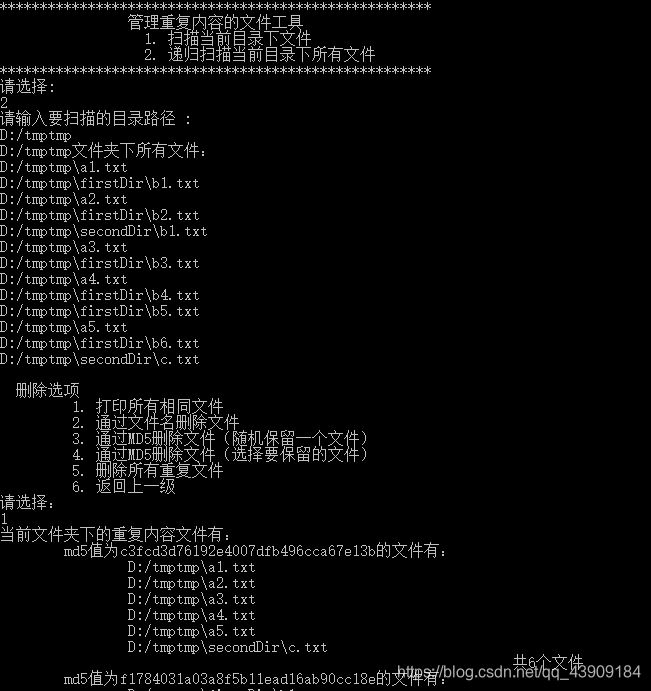
运行效果

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









