









1、什么是Web自动化测试?
让程序代替人工自动验证web项目功能的过程(预期结果和实际结果的比较)
2、为什么要在做Web自动化测试?
- 在较少的时间内运行更多和测试用例
- 脚本可重复执行
- 减少人为的错误
- 克服手工测试的局限
3、在什么场景下适合做Web自动化测试?
我在这里总结了几点适合做Web自动化测试的经常:
(1)任务测试明确,不会频繁变动
(2)每日构建后的测试认证
(3)比较频繁的回归测试
(4)软件系统界面稳定,变动少
(5)需要在平台上运行的相同测试案例、组合遍历测试的测试,以及大量的重复任务
(6)软件维护周期长
(7)被测软件系统开发较为规范,能够保证系统的测试性
(8)具备大量自动化测试平台
(9)测试人员具备较强的编程能力
当然,并不是要满足上面9点的要求才能开展自动化测试,软件需求变动不频繁、项目周期长、自动阿虎脚本可以重复使用也可以展开自动化测试。
4、Web自动化测试需要具备哪些条件?
(1)编辑语言
编写自动化测试脚本可以使用Java、Python、Ruby、C#、JavaScript,因为Selenium针对每种编程语言都开发了相应的Selenium测试库,封装了很多类和方法。
(2)Selenium
Selenium提供了操作Web的类和方法,我们只需要使用这些方法即可操作Web页面上的元素上面的控件。
(3)单元测试框架
如何定义一条测试用例、如何组织和运行测试用例,以及如何统计测试用例的运行结果(总测试用例条数、成功测试用例条数、失败测试用例数等)都是由单元测试框架实现的,单元测试框架是编写自动化测试用例的基础。
5、Selenium的简介
Selenium是一个用于Web应用程序测试的工具,Selenium主要包括Webdriver、Selenium IDE、Grid的介绍。
Selenium支持Web浏览器的自动化,它主要有三个工具构成:WebDriver、IDE、Grid
WebDriver 使用浏览器提供的 API 来控制浏览器,就像用户在操作浏览器,不具有侵入性。
IDE 是 Chrome 和 FireFox 扩展插件,可以录制用户在浏览器中的操作。比较推荐使用FireFox来安装Selenium IDE插件,安装比较方便,Selenium IDE,它提供了比较完备的自动化功能,如脚本录制/回放、定时任务等;还可以将录制的脚本导程不同的编程语言的Selenium的测试脚本,这在很大程度上可以帮助新手编写测试用例。
Grid 用于 Selenium 分布式,你可以在多个浏览器和操作系统运行测试用例。
6、测试环境的搭建
(1)安装Python
下载Python:
Python下载地址:https://www.python.org/downloads/
根据自己电脑系统下载对应的Python安装包,如下图所示:

安装Python
将下载的Python.exe双击运行安装,需要在第一步勾选“Add Python 3.8.8 to PATH”,将Python的环境配置到PATH中,然后一直点击Next,指导点击“install”。

配置Python环境变量
将Python的安装路径添加在环境变量PATH中,如下图所示:


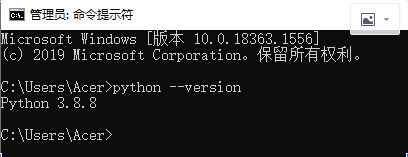
查看Python版本信息
在cmd输入python --version,效果如下图所示
7、Selenium工作原理
在客户端(client)完成 Selenium 脚本编写,将脚本传送给 Selenium 服务器,Selenium 服务器使用浏览器驱动(driver)与浏览器(browser)进行交互。

8、安装Selenium
第一种方式
Python 自带的 pip 工具安装:
#安装最新版本
pip install selenium
#指定版本进行安装
pip install selenium == 3.8.9
#查看Selenium相关信息
pip show selenium
第二种方式
Selenium 是 Python 的第三方库,可采用 PyCharm 自带方式安装。
菜单栏 File -> Settings 进入配置界面:

9、下载浏览器驱动
-
下载driver驱动
- 谷歌驱动:https://npm.taobao.org/mirrors/chromedriver(以chrome为例)
- 火狐驱动:https://github.com/mozilla/geckodriver/releases
-
将下载好的driver的压缩包进行解压,这个不需要安装,只要将环境变量配置到PATH中就好了,如下图所示
-
配置环境变量
-
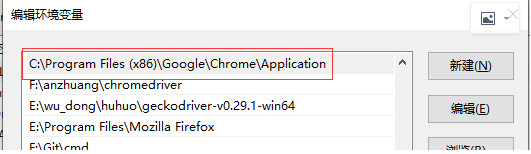
将谷歌浏览器的安装路径下配置变量path中,浏览器的安装路径应该怎么找呢?把鼠标光标放在谷歌浏览器,右键-点击属性-目标-选择到application,如下图所示:

-
将Chromedriver.exe放在谷歌浏览器的安装路径下
-
将Chromedriver.exe放在python的安装路径下(这一步是非必须,看个人的电脑,放进去也不影响)
-
验证chrome是否配置成功,在cmd输入chromedriver,显示版本信息则证明安装成功,如下图所示:


-
这时,测试环境已经搭建完成了,编写自动化测试脚本之前,我们应该先学习定位元素,有以下的几种定位方法:
#以部分百度前端代码为例
<span class="bg s_ipt_wr new-pmd quickdelete-wrap">
<span class="soutu-btn"></span>
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
<span class="soutu-hover-tip" style="display: none;">按图片搜索</span>
</span>
(1)id定位
id在HTML文档相对唯一,用法如下所示:
self.driver.find_element_by_id("kw")
(2)name定位
name用来定位元素的名称,用法如下所示:
self.driver.find_element_by_name("wd")
(3)class定位
class用来定位元素的类名,用法如下所示:
self.driver.find_element_by_class_name("s_ipt")
(4)link定位
link定位于与前面几种定位方式不同,它专门用来定位文本链接。用法如下所示:
点击百度首页右上角的“设置”
self.driver.find_element_by_link_text("设置")
(5)XPath定位
绝对定位方式:XPath有多种定位给策略,最简单直观的就是写出绝对定位,但是往往这种方式是最不稳定的,页面的元素发生改变时,定位也会方法改变。

self.driver.find_element_by_xpath("/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input")
(6)CSS定位
通过class定位
self.driver.find_element_by_css_selector(".s_ipt")
通过id定位
self.driver.find_element_by_css_selector("#kw")
通过标签名定位
self.driver.find_element_by_css_selector("input")
(7)通过标签层级关系定位
self.driver.find_element_by_xpath("span > input")
(8)用By定位
使用ID定位
self.driver.find_element(By.ID,"kw")
通过name定位
self.driver.find_element(By.NAME,"wd")
WebDriver中的定位方法
前面我们已经了解了定位元素的方法了,但定位只是第一步,定位之后还需要对这个元素进行操作,比如单击(按钮)或输入(输入框),下面我们就来认识WebDriver中常用的几个方法:
(1)clear():清除文本
(2)send_keys():模拟按键输入
(3)click():单击元素
click()可以单击任何可以点击的元素,例如按钮、复选框、单选框、下拉框文字链接和图片链接等。
(4)submit():提交表单
有些搜索框不提供搜素按钮,而是通过按键盘上到额回车键完成搜素内容的提交,这时就需要通过submit()进行提交。
(5)size():获取元素的大小
(6)text:获取元素的文本
(7)get_attribute():获取属性值
(8)is_displayed():设置该元素是否用户可见
设置元素等待
WebDriver提供了两种类型的元素等待:隐式等待和显示等待
(1)隐式等待
WebDriver提供implicitly_wait()方法可用来实现隐式等待,implicitly_wait()的参数是时间,单位为秒。当脚本执行某一个元素时,如果元素存在,则继续执行;如果定位不到元素,则它会以轮询的方式不断地判断元素是否存在。假设在第6s定位到了元素,则继续执行,若直到超过时间(10s)还没有定位到元素,则抛出异常。
(2)显示等待
显示等待是WebDriver等待某个条件成立则继续执行,否则在达到最大时长时抛出超时异常。
格式如下:
WebDriverWait(driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)
#driver:浏览器驱动
#timeout:最长超过时间,默认以秒为单位
#poll_frequency:检测的间隔(步长)时间,默认为0.5s
#ignored_exceptions:超时后的异常信息,默认情况下抛出异常。
(3)强制等待
设置等待时间为多少秒时,就会一直等待这个时间直到完成,例如,设置等待时间为2秒,就会在2秒之后才会执行下一条命令。
Selenium测试用例的编写
用例步骤:
1.访问百度网页
2.向输入框输入“霍格沃兹测试学院”
3.点击“百度一下”
def test_baidu(self):
# 创建driver驱动
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
#执行自动化步骤
self.driver.get("https://www.baidu.com/")
self.driver.find_element_by_id("kw").send_keys("霍格沃兹测试学院")
self.driver.find_element_by_id("su").click()
用例步骤:
1.访问测试人社区地址https://ceshiren.com/
2.点击“测试答疑”
3.点击第一条帖子
import time
from selenium import webdriver
class TestHogwarts:
def test_baidu(self):
# 创建driver驱动
self.driver = webdriver.Chrome()
# 浏览器最大化
self.driver.maximize_window()
# 设置隐式等待
self.driver.implicitly_wait(5)
self.driver.get("https://ceshiren.com/")
self.driver.find_element_by_link_text("测试答疑").click()
time.sleep(2)
'''使用xpath定位'''
self.driver.find_element_by_xpath("//*[@class='link-top-line']//a[1]").click()
'''使用css定位'''
# self.driver.find_element_by_css_selector(".link-top-line a:nth-child(2)").click()
'''使用xpath定位'''
# self.driver.find_element_by_link_text("Java环境准备贴-Windows").click()
根据这两条用例进行优化:
'''
导入依赖
- 创建driver
- 执行自动化步骤
- 断言
'''
import time
from selenium import webdriver
class TestHogwarts:
def setup(self):
#创建driver驱动
self.driver = webdriver.Chrome()
self.driver.set_window_size(800,1200)
#浏览器最大化
self.driver.maximize_window()
#设置隐式等待
self.driver.implicitly_wait(5)
def teardown(self):
# 关闭浏览器
self.driver.quit()
def test_baidu(self):
self.driver.get("https://www.baidu.com/")
self.driver.find_element_by_id("kw").send_keys("霍格沃兹测试学院")
self.driver.find_element_by_id("su").click()
time.sleep(5)
'''
1、访问测试人社区
2、点击“测试答疑”
3、点击第一条帖子
'''
def test_hogwarts(self):
self.driver.get("https://ceshiren.com/")
self.driver.find_element_by_link_text("测试答疑").click()
time.sleep(2)
'''使用xpath定位'''
self.driver.find_element_by_xpath("//*[@class='link-top-line']//a[1]").click()
'''使用css定位'''
# self.driver.find_element_by_css_selector(".link-top-line a:nth-child(2)").click()
'''使用xpath定位'''
# self.driver.find_element_by_link_text("Java环境准备贴-Windows").click()
测试完成之后要写一份测试总结,测试总结中会涉及到测试用例的执行情况,那就是测试报告,那么自动化测试应该怎么实现测试报告,那就需要引入allure。allure是一个轻量级,灵活的,支持多语言,提供详细的测试报告、测试步骤、log的测试报告工具。使用allure精美测试报告之前,需要把allure的环境安装好。
allure安装
(1)2.13.5版本的allure下载:https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/2.13.5/
(2)下载allure安装包
(3)解压
(4)把bin目录加入Path环境变量
(5)查看allure是否安装成功,在cmd输入
allure --version
(6)安装allure-pytest插件
pip install allure-pytest
#在测试执行期间收集结果,–alluredir这个选项用于指定存储测试结果的路径)
pytest test_selenium.py -s -q --alluredir=./result
查看测试报告
#方法一:从结果生成报告,这是一个启动tomcat的服务,需要两个步骤:生成报告,打开报告
#生成报告
allure generate ./result/ -o ./report/ --clean
#打开报告
allure open -h 127.0.0.1 -p 8884 ./report/
#方法二:测试完成后查看实际报告,在线看报告,会直接打开默认浏览器展示当前报告
allure serve ./result/
测试用例都是成功的测试报告:

测试用例有成功也有失败的测试报告:
测试用例总览图:

测试用例成功:

测试用例失败的原因:

















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











