










最近在做文本分类。虽然bert已经过时了,但还是拿来用一用试试,由于是linux新手,在cuda上走了不少弯路(可以直接搭建虚拟环境安装cuda9.0,不用卸载11.x),现将完整过程写在这里:
1.卸载cuda11再安装
cuda11没有unistall文件,暴力卸载大法好。
sudo rm -rf /usr/local/cuda-11.4
sudo rm -rf /usr/local/cuda-11
sudo rm -rf /usr/local/cuda这里强烈建议大家去/usr/local/文件目录下看看自己的cuda是哪几个文件夹,在这里直接rm掉就完事了,接着往下走:
sudo vim ~/.bashrc如下图,把带有cuda的字样都注释掉:

“Esc”,“:wq”保存关闭。
安装cuda9.0:cuda_9.0.176_384.81_linux.run
但是在跑GPU的时候,出现错误:
ImportError:libcudnn.so.7:cannot open share object file: No such file or directory
原因是默认软链接的cudnn没有相应的libcudnn.so文件。
如果涉及到两个cuda版本的切换,参考链接:https://blog.csdn.net/sinat_33761963/article/details/98216292
如果不涉及两个cuda版本切换,请参考本博客第二部分搭建cudnn的过程配置cudnn就解决了。
2.centos7+cuda9.0+cudnn7安装
2.1在官网或链接下载相应驱动
用mkdir命令在你想放置下列安装包的文件夹下创建一个你自己的文件夹。然后cd进去
cuda9.0:cuda_9.0.176_384.81_linux.run
cudnn:
wget https://developer.nvidia.com/compute/machine-learning/cudnn/secure/7.6.5.32/Production/9.0_20191031/cudnn-9.0-linux-x64-v7.6.5.32.tgz绕过官网的注册登录过程下载cudnn可以在这篇链接里找:cudnn安装包
也可以跟我上面命令直接在命令行敲对应的下载安装包,友情提示:鼠标放置在下载的安装包上,网页左下角出现的就是下载链接。直接wget就完事了。
2.2屏蔽默认的nouvea
切换到root用户:
su root
#打开:/lib/modprobe.d/dist-blacklist.conf
vim /lib/modprobe.d/dist-blacklist.conf
#将nvidiafb注释掉:
#blacklist nvidiafb
#然后添加以下语句:
blacklist nouveau
options nouveau modeset=02.3重建initramfs image
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)2.4 修改运行级别为文本模式
systemctl set-default multi-user.target2.5 重新启动, 使用root用户登陆
reboot2.6查看nouveau是否已经禁用
ls mod | grep nouveau2.7Nvidia 驱动安装
找到驱动 NVIDIA-Linux-x86_64-470.50(你GPU对应的的驱动名称).run 路径
sh NVIDIA-Linux-x86_64-470.50.run --no-opengl-files2.8cuda9安装
#先根据系统实际情况下载对应的CUDA,这里我下载了CUDA 9.0 版本
#1.检查是否安装了GPU:
lspci | grep -i nvidia
#2.安装gcc、g++编译器
sudo yum install gcc
sudo yum install gcc-c++
#3.安装kernel-devel
sudo yum install kernel-devel
#4.安装Driver,Toolkit和Samples
sudo sh cuda_9.0.176_384.81_linux-run.run --no-opengl-libs
#直接按【Q】键,并输入【accept】回车后
#在这里我们是自己安装了匹配的驱动,所以第一项Driver出来的时候选择N 后面全是Y ,即可
#5.在用户根目录下的.bashrc文件中加入如下内容:
export PATH=$PATH:/usr/local/cuda-9.0/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-9.0/lib64
#保存退出,Esc :wq
source .bashrc (立即生效文件)
#如果是全环境变量(所用用户都能使用),需要在/etc/profile文件加入上面的几句话2.9cudnn安装
#找到 cudnn-9.0-linux-x64-v7.tgz 路径
#执行:
tar -xzvf cudnn-9.0-linux-x64-v7.tgz
#执行 (root 用户):
cp cuda/include/cudnn.h /usr/local/cuda/include
#执行 (root 用户):
cp cuda/lib64/libcudnn* /usr/local/cuda/lib642.10环境变量
#在~/.bashrc 的最后添加
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=/usr/local/cuda 2.11cudnn连接建立:
cd /usr/local/cuda/lib64
sudo rm -rf libcudnn.so libcudnn.so.7
#删除原有版本号,版本号在cudnn/lib64中查询
sudo ln -s libcudnn.so.7.6.4 libcudnn.so.7
#生成软连接,注意自己下载的版本号
sudo ln -s libcudnn.so.7 libcudnn.so
sudo ldconfig
#立即生效
3.Bert代码运行
代码下载:包含Bert在内的代码仓库
BERT模型来源于论文 :BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT模型是基于双向Transformer实现的语言模型,集预训练和下游任务于一个模型中, 因此在使用的时候我们不需要搭建自己的下游任务模型,直接用BERT模型即可,我们将谷歌开源的源码下载 下来放在bert文件夹中,在进行文本分类只需要修改run_classifier.py文件即可,另外我们需要将训练集 和验证集分割后保存在两个不同的文件中,放置在/BERT/data下。然后还需要下载谷歌预训练好的模型放置在 /BERT/modelParams文件夹下,还需要建一个/BERT/output文件夹用来放置训练后的模型文件
做完上面的步骤之后只要执行下面的脚本即可
export BERT_BASE_DIR=../modelParams/uncased_L-12_H-768_A-12(预训练的路径)
export MY_DATASET=../data/(分类数据集的路径)
python run_classifier.py
--data_dir=$MY_DATASET
--task_name=imdb
--vocab_file=$BERT_BASE_DIR/vocab.txt
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--output_dir=../output/
--do_train=true
--do_eval=true
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--max_seq_length=200
--train_batch_size=16
--learning_rate=5e-5
--num_train_epochs=3.0
做好上述准备之后,直接运行即可:
export BERT_BASE_DIR=/root/zzzworking/textClassifier/BERT/modelParams/uncased_L-12_H-768_A-12
export DATASET=/root/zzzworking/textClassifier/BERT/data/
python run_classifier.py --data_dir=$MY_DATASET --task_name=imdb --vocab_file=$BERT_BASE_DIR/vocab.txt --bert_config_file=$BERT_BASE_DIR/bert_config.json --output_dir=/root/zzzworking/textClassifier/BERT/output/ --do_train=true --do_eval=true --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --max_seq_length=200 --train_batch_size=16 --learning_rate=5e-5--num_train_epochs=2.04.Bert讲解
参考链接:bert实战
数据集
数据集为IMDB 电影影评,总共有三个数据文件,在/data/rawData目录下,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv。在进行文本分类时需要有标签的数据(labeledTrainData),预处理后的文件为/data/preprocess/labeledTrain.csv。
BERT预训练模型
BERT模型是谷歌提出的基于双向Transformer构建的语言模型。BERT模型和ELMo有大不同,在之前的预训练模型(包括word2vec,ELMo等)都会生成词向量,这种类别的预训练模型属于domain transfer。而近一两年提出的ULMFiT,GPT,BERT等都属于模型迁移。
BERT 模型是将预训练模型和下游任务模型结合在一起的,也就是说在做下游任务时仍然是用BERT模型,而且天然支持文本分类任务,在做文本分类任务时不需要对模型做修改。谷歌提供了下面七种预训练好的模型文件。

BERT模型在英文数据集上提供了两种大小的模型,Base和Large。Uncased是意味着输入的词都会转变成小写,cased是意味着输入的词会保存其大写(在命名实体识别等项目上需要)。Multilingual是支持多语言的,最后一个是中文预训练模型。
在这里我们选择BERT-Base,Uncased。下载下来之后是一个zip文件,解压后有ckpt文件,一个模型参数的json文件,一个词汇表txt文件。
在应用BERT模型之前,我们需要去github上下载开源代码,我们可以直接clone下来,在这里有一个run_classifier.py文件,在做文本分类项目时,我们需要修改这个文件,主要是添加我们的数据预处理类。clone下来的项目结构如下:
在run_classifier.py文件中有一个基类DataProcessor类,其代码如下:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines在这个基类中定义了一个读取文件的静态方法_read_tsv,四个分别获取训练集,验证集,测试集和标签的方法。接下来我们要定义自己的数据处理的类,我们将我们的类命名为IMDBProcessor
class IMDBProcessor(DataProcessor):
"""
IMDB data processor
"""
def _read_csv(self, data_dir, file_name):
with tf.gfile.Open(data_dir + file_name, "r") as f:
reader = csv.reader(f, delimiter=",", quotechar=None)
lines = []
for line in reader:
lines.append(line)
return lines
def get_train_examples(self, data_dir):
lines = self._read_csv(data_dir, "trainData.csv")
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "train-%d" % (i)
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, label=label))
return examples
def get_dev_examples(self, data_dir):
lines = self._read_csv(data_dir, "devData.csv")
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "dev-%d" % (i)
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, label=label))
return examples
def get_test_examples(self, data_dir):
lines = self._read_csv(data_dir, "testData.csv")
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "test-%d" % (i)
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, label=label))
return examples
def get_labels(self):
return ["0", "1"]在这里我们没有直接用基类中的静态方法_read_tsv,因为我们的csv文件是用逗号分隔的,因此就自己定义了一个_read_csv的方法,其余的方法就是读取训练集,验证集,测试集和标签。在这里标签就是一个列表,将我们的类别标签放入就行。训练集,验证集和测试集都是返回一个InputExample对象的列表。InputExample是run_classifier.py中定义的一个类,代码如下:
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label在这里定义了text_a和text_b,说明是支持句子对的输入的,不过我们这里做文本分类只有一个句子的输入,因此text_b可以不传参。
另外从上面我们自定义的数据处理类中可以看出,训练集和验证集是保存在不同文件中的,因此我们需要将我们之前预处理好的数据提前分割成训练集和验证集,并存放在同一个文件夹下面,文件的名称要和类中方法里的名称相同。
到这里之后我们已经准备好了我们的数据集,并定义好了数据处理类,此时我们需要将我们的数据处理类加入到run_classifier.py文件中的main函数下面的processors字典中,结果如下:

之后就可以直接执行run_classifier.py文件,执行脚本如下:
export BERT_BASE_DIR=/root/zzzworking/textClassifier/BERT/modelParams/uncased_L-12_H-768_A-12
export DATASET=/root/zzzworking/textClassifier/BERT/data/
python run_classifier.py --data_dir=$MY_DATASET --task_name=imdb --vocab_file=$BERT_BASE_DIR/vocab.txt --bert_config_file=$BERT_BASE_DIR/bert_config.json --output_dir=/root/zzzworking/textClassifier/BERT/output/ --do_train=true --do_eval=true --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --max_seq_length=200 --train_batch_size=16 --learning_rate=5e-5--num_train_epochs=2.0在这里的task_name就是我们定义的数据处理类的键,BERT模型较大,加载时需要较大的内存,如果出现内存溢出的问题,可以适当的降低batch_size的值。
目前迭代完之后的输出比较少,而且只有等迭代结束后才会有结果输出,不利于观察损失的变化,后续将修改输出。目前的输出结果:
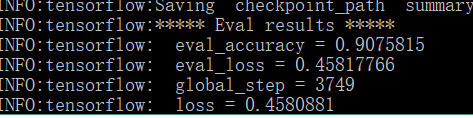
测试集上的准确率达到了90.7% ,这个结果比Bi-LSTM + Attention(87.7%)的结果要好。
















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











