







该文章代码配合我的上一篇文章:
优先队列的出队操作
优先队列的入队操作
堆排序第一版本
public static void main(String[] args) {
int[] arr={
1,3,7,5,4,-1,999,58,5,8,2
};
HeapSort(arr);
for (int a:
arr) {
System.out.println(a);
}
}
public static void HeapSort(int[]arr) {
MaxHeap p = new MaxHeap(arr.length+1);
for(int i:arr)
p.insert(i);
for(int i=arr.length-1;i>=0;i--)
{
arr[i]=p.poll();
}
}
这个版本的堆排序没有使用 Heapify的操作,而是根据给定的数组,创建一个堆,把数组的所有元素存入,大根堆会自动帮我们维护这个结构,大根堆的结构是 父亲大于儿子,也就是说每次从堆顶取出的元素一定是这个堆里面最大的 ,shiftUp 建堆,shiftDown调整
那么我们从尾到头把它拷贝到原数组的末尾,就算是排好序了
由于堆的insert和 poll操作都是 log(N) 级别的,进行了两次for循环 时间复杂度是O(N*logN) 级别的
堆排序第二版本 Heapify
但是事实上,我们可以使用一个叫做Heapify的方法,看代码:
public MaxHeap(int[] arr)
{
data = new int[arr.length+1];
capacity = arr.length;
for(int i=0;i<capacity;i++)
data[i+1]=arr[i];
count=capacity;
for(int i=count/2;i>=1;i--) {//Heapify的过程
shiftDown(i);
}
}
public static void HeapSort(int[]arr) {
MaxHeap p = new MaxHeap(arr);
for(int i=arr.length-1;i>=0;i--)
arr[i]=p.poll();
}
直接从大根堆里面取出来,这就是堆排序了
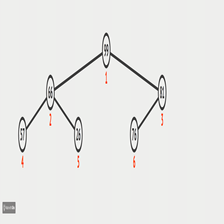
,怎么理解Heapify这个过程呢? 我们假设数组的长度是N
我们要找出最后一个非叶子节点
最后一个非叶子节点 是 N/2,这里我的下标是从1开始存储的

叶子节点就是没有孩子的节点,如图的 6,3,7元素,也就是最下面的一层
注意:对于一个叶子节点,它们本身就是一个大根堆
也就是说数组里面就只有它一个元素,那么这个数组也算大根堆

怎么理解这两个版本的堆排序呢
第一个版本的建堆过程 中将N个元素插入空堆时间复杂度是 (NlogN),使用Heapify的话,进行操作,这个时间复杂度是 O(N)级别的
也就是说两种方法的快慢在建堆的时候体现
一个建堆要 O(NlogN)
而使用过Heapify建堆只要 O(N) 的时间而已
至此,堆排序讲完















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









