






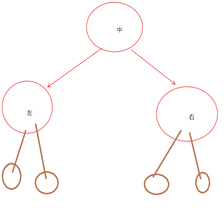


class Trie {
private Node root;
static class Node{
Node[] childs;
boolean isEnd;
public Node(){
childs = new Node[26];//默认为 null
}
}
/** Initialize your data structure here. */
public Trie() {
root = new Node();
}
/** Inserts a word into the trie. */
public void insert(String word) {
Node t = root;
int len = word.length();
for(int i=0;i<len;++i)
{
int index = word.charAt(i)-'a';
if(t.childs[index]==null) t.childs[index] = new Node();
t = t.childs[index];
}
t.isEnd = true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
int i = word.charAt(j)-'a';
if(top.childs[i]==null) return false;
top = top.childs[i];
}
return top.isEnd==true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
int i = word.charAt(j)-'a';
if(top.childs[i]==null) return false;
top = top.childs[i];
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
用途:

也可以构建出 hashmap, 使得查询的时间复杂度为 O(1)

 每个节点都有26个分支,这也只是英文的情况下,如果是中文的话就没办法使用数组了,要使用 哈希表来代替
每个节点都有26个分支,这也只是英文的情况下,如果是中文的话就没办法使用数组了,要使用 哈希表来代替
以上实现有一个缺点,就是只能看英文的,下面提供一种中文字典树的实现
/**
* 使用 HashMap 实现的中文字典树
*/
class Trie {
private Node root;
static class Node{
HashMap<Character,Node>childs;
boolean isEnd;
public Node(){
childs = new HashMap<>();
}
}
/** Initialize your data structure here. */
public Trie() {
root = new Node();
}
/** Inserts a word into the trie. */
public void insert(String word) {
Node t = root;
int len = word.length();
for(int i=0;i<len;++i)
{
char c = word.charAt(i);
if(!t.childs.containsKey(c))
{
t.childs.put(c,new Node());
}
t = t.childs.get(c);
}
t.isEnd = true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
char c = word.charAt(j);
if(!top.childs.containsKey(c))
{
return false;
}
top = top.childs.get(c);
}
return top.isEnd;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
char c = word.charAt(j);
if(!top.childs.containsKey(c))
{
return false;
}
top = top.childs.get(c);
}
return true;
}
}
下面是字典树的正确食用方式:
/**
* @Author lyr
* @create 2019/12/17 21:17
*/
public class Main {
public static void main(String[] args) {
Trie t = new Trie();
String s = "<script> alert('爱你爸爸') </script>";
t.insert("script");
t.insert("你爸爸");
HashSet set = new HashSet();
Trie.Node next;
for (int i = 0; i < s.length(); i++) {
int begin=i;int end=begin;
next = t.root;
for(int j=i;j<s.length();++j)
{
next = next.childs.getOrDefault(s.charAt(j),null);
if(next!=null)
{
System.out.print (s.charAt(j));
if(next.isEnd)
{
System.out.println("匹配成功");
end = j;
set.add(s.substring(begin,end+1));
}
}else{
break;
}
}
}
System.out.println(set);
}
static
class Trie {
private Node root;
static class Node{
HashMap<Character,Node>childs;
boolean isEnd;
public Node(){
childs = new HashMap<>();
}
}
/** Initialize your data structure here. */
public Trie() {
root = new Node();
}
/** Inserts a word into the trie. */
public void insert(String word) {
Node t = root;
int len = word.length();
for(int i=0;i<len;++i)
{
char c = word.charAt(i);
if(!t.childs.containsKey(c))
{
t.childs.put(c,new Node());
}
t = t.childs.get(c);
}
t.isEnd = true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
char c = word.charAt(j);
if(!top.childs.containsKey(c))
{
return false;
}
top = top.childs.get(c);
}
return top.isEnd;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String word) {
Node top = root;
int len = word.length();
for(int j=0;j<len;++j)
{
char c = word.charAt(j);
if(!top.childs.containsKey(c))
{
return false;
}
top = top.childs.get(c);
}
return true;
}
}
}















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









