 实用图像处理与AI应用
实用图像处理与AI应用





 本文介绍了三种实用的图像处理技巧:使用Python爬虫下载图片,利用PIL库分割图像,以及采用PaddleHub进行图像抠图和口罩识别。通过具体代码示例,读者可以学习如何实现这些功能。
本文介绍了三种实用的图像处理技巧:使用Python爬虫下载图片,利用PIL库分割图像,以及采用PaddleHub进行图像抠图和口罩识别。通过具体代码示例,读者可以学习如何实现这些功能。
1、爬取网页中图片的实用小程序:
import requests
import os
# 右击图片复制地址
url = "http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root): # 保存文件路径
os.mkdir(root)
if not os.path.exists(path): # 写入文件
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")

2、对png格式图像进行分割:
import os
from PIL import Image
def splitimage(src, rownum, colnum, dstpath):
img = Image.open(src)
w, h = img.size
if rownum <= h and colnum <= w:
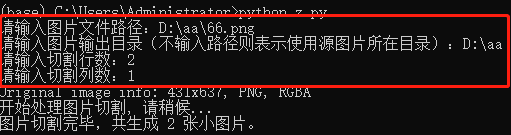
print('Original image info: %sx%s, %s, %s' % (w, h, img.format, img.mode))
print('开始处理图片切割, 请稍候...')
s = os.path.split(src)
if dstpath == '':
dstpath = s[0]
fn = s[1].split('.')
basename = fn[0]
ext = fn[-1]
num = 0
rowheight = h // rownum
colwidth = w // colnum
for r in range(rownum):
for c in range(colnum):
box = (c * colwidth, r * rowheight, (c + 1) * colwidth, (r + 1) * rowheight)
img.crop(box).save(os.path.join(dstpath, basename + '_' + str(num) + '.' + ext), ext)
num = num + 1
print('图片切割完毕,共生成 %s 张小图片。' % num)
else:
print('不合法的行列切割参数!')
src = input('请输入图片文件路径:')
if os.path.isfile(src):
dstpath = input('请输入图片输出目录(不输入路径则表示使用源图片所在目录):')
if (dstpath == '') or os.path.exists(dstpath):
row = int(input('请输入切割行数:'))
col = int(input('请输入切割列数:'))
if row > 0 and col > 0:
splitimage(src, row, col, dstpath)
else:
print('无效的行列切割参数!')
else:
print('图片输出目录 %s 不存在!' % dstpath)
else:
print('图片文件 %s 不存在!' % src)
#D:/aa/zz.png
原始图片(66.png):

切割后的图像(66_0.png):

切割后的图像(66_1.png):

3、抠图和批量抠图
import os, paddlehub as hub
humanseg = hub.Module(name='deeplabv3p_xception65_humanseg') # 加载模型
path = 'C:/Users/Administrator/figure/' # 文件目录
files = [path + i for i in os.listdir(path)] # 获取文件列表
results = humanseg.segmentation(data={'image':files}) # 抠图
print(results)

口罩识别:
import paddlehub as hub
# 加载模型
module = hub.Module(name='pyramidbox_lite_mobile_mask')
# 图片列表
image_list = ['face1.jpeg']
# 获取图片字典
input_dict = {'image':image_list}
# 检测是否带了口罩
module.face_detection(data=input_dict)
print(input_dict)


















 5850
5850




 到【灌水乐园】发言
到【灌水乐园】发言







