






throw new PermanentLockingException(“Attempted to obtain a lock after
mutations had been persisted”);
// 使用key+column组装为lockID,供下述加锁使用!!!!!
KeyColumn lockID = new KeyColumn(key, column);
log.debug(“Attempting to acquireLock on {} ev={}”, lockID, expectedValue);
// 获取本地当前jvm进程中的写锁(看下述的 1:写锁获取分析)
// (此处的获取锁只是将对应的KLV存储到Hbase中!存储成功并不代表获取锁成功)
// 1. 获取成功(等同于存储成功)则继续执行
// 2. 获取失败(等同于存储失败),会抛出异常,抛出到最上层,打印错误日志“Could not commit transaction
[“+transactionId+”] due to exception” 并抛出对应的异常,本次插入数据结束
locker.writeLock(lockID, tx.getConsistentTx());
// 执行前提:上述获取锁成功!
// 存储期望值,此处为了实现当相同的key + value + tx多个加锁时,只处理第一个
// 存储在事务对象中,标识在commit判断锁是否获取成功时,当前事务插入的是哪个锁信息
tx.storeExpectedValue(this, lockID, expectedValue);
} else {
// locker为空情况下,直接抛出一个运行时异常,终止程序
store.acquireLock(key, column, expectedValue, unwrapTx(txh));
}
}
2、执行 locker.writeLock(lockID, tx.getConsistentTx()) 触发锁获取
public void writeLock(KeyColumn lockID, StoreTransaction tx) throws
TemporaryLockingException, PermanentLockingException {
if (null != tx.getConfiguration().getGroupName()) {
MetricManager.INSTANCE.getCounter(tx.getConfiguration().getGroupName(),
M_LOCKS, M_WRITE, M_CALLS).inc();
}
// 判断当前事务是否在图实例的维度 已经占据了lockID的锁
//
此处的lockState在一个事务成功获取本地锁+分布式锁后,以事务为key、value为map,其中key为lockID,value为加锁状态(开始时间、过期时间等)
if (lockState.has(tx, lockID)) {
log.debug(“Transaction {} already wrote lock on {}”, tx, lockID);
return;
}
// 当前事务没有占据lockID对应的锁
// 进行(lockLocally(lockID, tx) 本地加锁锁定操作,
if (lockLocally(lockID, tx)) {
boolean ok = false;
try {
// 在本地锁获取成功的前提下:
// 尝试获取基于Hbase实现的分布式锁;
// 注意!!!(此处的获取锁只是将对应的KLV存储到Hbase中!存储成功并不代表获取锁成功)
S stat = writeSingleLock(lockID, tx);
// 获取锁分布式锁成功后(即写入成功后),更新本地锁的过期时间为分布式锁的过期时间
lockLocally(lockID, stat.getExpirationTimestamp(), tx); // update local lock
expiration time
// 将上述获取的锁,存储在标识当前存在锁的集合中Map<tx,Map<lockID,S>>,
key为事务、value中的map为当前事务获取的锁,key为lockID,value为当前获取分布式锁的ConsistentKeyStatus(一致性密匙状态)对象
lockState.take(tx, lockID, stat);
ok = true;
} catch (TemporaryBackendException tse) {
// 在获取分布式锁失败后,捕获该异常,并抛出该异常
throw new TemporaryLockingException(tse);
} catch (AssertionError ae) {
// Concession to ease testing with mocks & behavior verification
ok = true;
throw ae;
} catch (Throwable t) {
// 出现底层存储错误! 则直接加锁失败!
throw new PermanentLockingException(t);
} finally {
// 判断是否成功获取锁,没有获分布式锁的,则释放本地锁
if (!ok) {
// 没有成功获取锁,则释放本地锁
// lockState.release(tx, lockID); // has no effect
unlockLocally(lockID, tx);
if (null != tx.getConfiguration().getGroupName()) {
MetricManager.INSTANCE.getCounter(tx.getConfiguration().getGroupName(),
M_LOCKS, M_WRITE, M_EXCEPTIONS).inc();
}
}
}
} else {
// 如果获取本地锁失败,则直接抛出异常,不进行重新本地争用
// Fail immediately with no retries on local contention
throw new PermanentLockingException(“Local lock contention”);
}
}
包含两个部分:
- 本地锁的获取
lockLocally(lockID, tx) - 分布式锁的获取
writeSingleLock(lockID, tx)注意此处只是将锁信息写入到Hbase中,并不代表获取分布式锁成功,只是做了上述介绍的第一个阶段分布式锁信息插入
3、本地锁获取lockLocally(lockID, tx)
public boolean lock(KeyColumn kc, T requester, Instant expires) {
assert null != kc;
assert null != requester;
final StackTraceElement[] acquiredAt = log.isTraceEnabled() ?
new Throwable("Lock acquisition by " + requester).getStackTrace() : null;
// map的value,以事务为核心
final AuditRecord audit = new AuditRecord<>(requester, expires, acquiredAt);
// ConcurrentHashMap实现locks, 以lockID为key,事务为核心value
final AuditRecord inMap = locks.putIfAbsent(kc, audit);
boolean success = false;
// 代表当前map中不存在lockID,标识着锁没有被占用,成功获取锁
if (null == inMap) {
// Uncontended lock succeeded
if (log.isTraceEnabled()) {
log.trace(“New local lock created: {} namespace={} txn={}”,
kc, name, requester);
}
success = true;
} else if (inMap.equals(audit)) {
// 代表当前存在lockID,比对旧value和新value中的事务对象是否是同一个
// requester has already locked kc; update expiresAt
// 上述判断后,事务对象为同一个,标识当前事务已经获取这个lockID的锁;
// 1. 这一步进行cas替换,作用是为了刷新过期时间
// 2. 并发处理,如果因为锁过期被其他事务占据,则占用锁失败
success = locks.replace(kc, inMap, audit);
if (log.isTraceEnabled()) {
if (success) {
log.trace(“Updated local lock expiration: {} namespace={} txn={} oldexp={}
newexp={}”,
kc, name, requester, inMap.expires, audit.expires);
} else {
log.trace(“Failed to update local lock expiration: {} namespace={} txn={}
oldexp={} newexp={}”,
kc, name, requester, inMap.expires, audit.expires);
}
}
} else if (0 > inMap.expires.compareTo(times.getTime())) {
// 比较过期时间,如果锁已经过期,则当前事务可以占用该锁
// the recorded lock has expired; replace it
// 1. 当前事务占用锁
// 2. 并发处理,如果因为锁过期被其他事务占据,则占用锁失败
success = locks.replace(kc, inMap, audit);
if (log.isTraceEnabled()) {
log.trace(“Discarding expired lock: {} namespace={} txn={} expired={}”,
kc, name, inMap.holder, inMap.expires);
}
} else {
// 标识:锁被其他事务占用,并且未过期,则占用锁失败
// we lost to a valid lock
if (log.isTraceEnabled()) {
log.trace(“Local lock failed: {} namespace={} txn={} (already owned by {})”,
kc, name, requester, inMap);
log.trace(“Owner stacktrace:\n {}”, Joiner.on("\n ").join(inMap.acquiredAt));
}
}
return success;
}
如上述介绍,本地锁的实现是通过ConcurrentHashMap数据结构来实现的,在图实例维度下唯一!
4、分布式锁获取第一个阶段:分布式锁信息插入
protected ConsistentKeyLockStatus writeSingleLock(KeyColumn lockID,
StoreTransaction txh) throws Throwable {
// 组装插入hbase数据的Rowkey
final StaticBuffer lockKey = serializer.toLockKey(lockID.getKey(),
lockID.getColumn());
StaticBuffer oldLockCol = null;
// 进行尝试插入 ,默认尝试次数3次
for (int i = 0; i < lockRetryCount; i++) {
// 尝试将数据插入到hbase中;oldLockCol表示要删除的column代表上一次尝试插入的数据
WriteResult wr = tryWriteLockOnce(lockKey, oldLockCol, txh);
// 如果插入成功
if (wr.isSuccessful() && wr.getDuration().compareTo(lockWait) <= 0) {
final Instant writeInstant = wr.getWriteTimestamp(); // 写入时间
final Instant expireInstant = writeInstant.plus(lockExpire);// 过期时间
return new ConsistentKeyLockStatus(writeInstant, expireInstant); // 返回插入对象
}
// 赋值当前的尝试插入的数据,要在下一次尝试时删除
oldLockCol = wr.getLockCol();
// 判断插入失败原因,临时异常进行尝试,非临时异常停止尝试!
handleMutationFailure(lockID, lockKey, wr, txh);
}
// 处理在尝试了3次之后还是没插入成功的情况,删除最后一次尝试插入的数据
tryDeleteLockOnce(lockKey, oldLockCol, txh);
// TODO log exception or successful too-slow write here
// 抛出异常,标识导入数据失败
throw new TemporaryBackendException(“Lock write retry count exceeded”);
}
上述只是将锁信息插入,插入成功标识该流程结束
5、分布式锁获取第一个阶段:分布式锁锁定是否成功判定
这一步,是在commit阶段进行的验证
public void commit() throws BackendException {
// 此方法内调用checkSingleLock 检查分布式锁的获取结果
flushInternal();
tx.commit();
}
最终会调用checkSingleLock方法,判断获取锁的状态!
protected void checkSingleLock(final KeyColumn kc, final
ConsistentKeyLockStatus ls,
final StoreTransaction tx) throws BackendException, InterruptedException {
// 检查是否被检查过
if (ls.isChecked())
return;
// Slice the store
KeySliceQuery ksq = new KeySliceQuery(serializer.toLockKey(kc.getKey(),
kc.getColumn()), LOCK_COL_START,
LOCK_COL_END);
// 此处从hbase中查询出锁定的行的所有列! 默认查询重试次数3
List claimEntries = getSliceWithRetries(ksq, tx);
// 从每个返回条目的列中提取timestamp和rid,然后过滤出带有过期时间戳的timestamp对象
final Iterable iterable = Iterables.transform(claimEntries,
e -> serializer.fromLockColumn(e.getColumnAs(StaticBuffer.STATIC_FACTORY),
times));
final List unexpiredTRs = new ArrayList<>(Iterables.size(iterable));
for (TimestampRid tr : iterable) { // 过滤获取未过期的锁!
final Instant cutoffTime = now.minus(lockExpire);
if (tr.getTimestamp().isBefore(cutoffTime)) {
…
}
// 将还未过期的锁记录存储到一个集合中
unexpiredTRs.add(tr);
}
// 判断当前tx是否成功持有锁!
如果我们插入的列是读取的第一个列,或者前面的列只包含我们自己的rid(因为我们是在第一部分的前提下获取的锁,第一部分我们成功获取了基于当前进程的锁,所以如果rid相同,代表着我们也成功获取到了当前的分布式锁),那么我们持有锁。否则,另一个进程持有该锁,我们无法获得锁
// 如果,获取锁失败,抛出TemporaryLockingException异常!!!!
抛出到顶层的mutator.commitStorage()处,最终导入失败进行事务回滚等操作
checkSeniority(kc, ls, unexpiredTRs);
// 如果上述步骤未抛出异常,则标识当前的tx已经成功获取锁!
ls.setChecked();
}
四:整体流程
总流程如下图:

整体流程为:
- 获取本地锁
- 获取分布式锁
- 插入分布式锁信息
- commit阶段判断分布式锁获取是否成功
- 获取失败,则重试
五:总结
JanusGraph的锁机制主要是通过本地锁+分布式锁来实现分布式系统下的数据一致性;
分布式锁的控制维度为:property、vertex、edge、index都可以;
JanusGraph支持在数据导入时通过前面一致性行为部分所说的LOCK来开关分布式锁:
- LOCK:数据导入时开启分布式锁保证分布式一致性
- DEFAULT、FORK:数据导入时关闭分布式锁
是否开启分布式锁思考:
在开启分布式锁的情况下,数据导入开销非常大;如果是数据不是要求很高的一致性,并且数据量比较大,我们可以选择关闭分布式锁相关,来提高导入速度;
然后,针对于小数据量的要求高一致性的数据,单独开启分布式锁来保证数据安全;
另外,我们在不开启分布式锁定的情况下,可以通过针对于导入的数据的充分探查来减少冲突!
针对于图schema的元素开启还是关闭分布式锁,还是根据实际业务情况来决定。
最后
大家看完有什么不懂的可以在下方留言讨论.
谢谢你的观看。
觉得文章对你有帮助的话记得关注我点个赞支持一下!
作者:洋仔聊编程
链接:https://juejin.cn/post/6907081858548006920
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
链接:https://juejin.cn/post/6907081858548006920
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
学习网络安全技术的方法无非三种:
第一种是报网络安全专业,现在叫网络空间安全专业,主要专业课程:程序设计、计算机组成原理原理、数据结构、操作系统原理、数据库系统、 计算机网络、人工智能、自然语言处理、社会计算、网络安全法律法规、网络安全、内容安全、数字取证、机器学习,多媒体技术,信息检索、舆情分析等。
第二种是自学,就是在网上找资源、找教程,或者是想办法认识一-些大佬,抱紧大腿,不过这种方法很耗时间,而且学习没有规划,可能很长一段时间感觉自己没有进步,容易劝退。
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
第三种就是去找培训。

接下来,我会教你零基础入门快速入门上手网络安全。
网络安全入门到底是先学编程还是先学计算机基础?这是一个争议比较大的问题,有的人会建议先学编程,而有的人会建议先学计算机基础,其实这都是要学的。而且这些对学习网络安全来说非常重要。但是对于完全零基础的人来说又或者急于转行的人来说,学习编程或者计算机基础对他们来说都有一定的难度,并且花费时间太长。
第一阶段:基础准备 4周~6周
这个阶段是所有准备进入安全行业必学的部分,俗话说:基础不劳,地动山摇
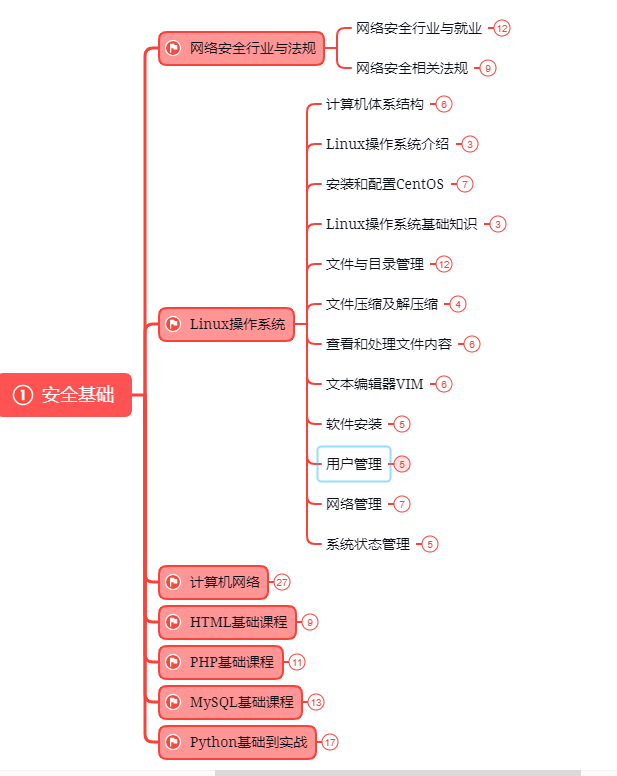
第二阶段:web渗透
学习基础 时间:1周 ~ 2周:
① 了解基本概念:(SQL注入、XSS、上传、CSRF、一句话木马、等)为之后的WEB渗透测试打下基础。
② 查看一些论坛的一些Web渗透,学一学案例的思路,每一个站点都不一样,所以思路是主要的。
③ 学会提问的艺术,如果遇到不懂得要善于提问。

配置渗透环境 时间:3周 ~ 4周:
① 了解渗透测试常用的工具,例如(AWVS、SQLMAP、NMAP、BURP、中国菜刀等)。
② 下载这些工具无后门版本并且安装到计算机上。
③ 了解这些工具的使用场景,懂得基本的使用,推荐在Google上查找。
渗透实战操作 时间:约6周:
① 在网上搜索渗透实战案例,深入了解SQL注入、文件上传、解析漏洞等在实战中的使用。
② 自己搭建漏洞环境测试,推荐DWVA,SQLi-labs,Upload-labs,bWAPP。
③ 懂得渗透测试的阶段,每一个阶段需要做那些动作:例如PTES渗透测试执行标准。
④ 深入研究手工SQL注入,寻找绕过waf的方法,制作自己的脚本。
⑤ 研究文件上传的原理,如何进行截断、双重后缀欺骗(IIS、PHP)、解析漏洞利用(IIS、Nignix、Apache)等,参照:上传攻击框架。
⑥ 了解XSS形成原理和种类,在DWVA中进行实践,使用一个含有XSS漏洞的cms,安装安全狗等进行测试。
⑦ 了解一句话木马,并尝试编写过狗一句话。
⑧ 研究在Windows和Linux下的提升权限,Google关键词:提权
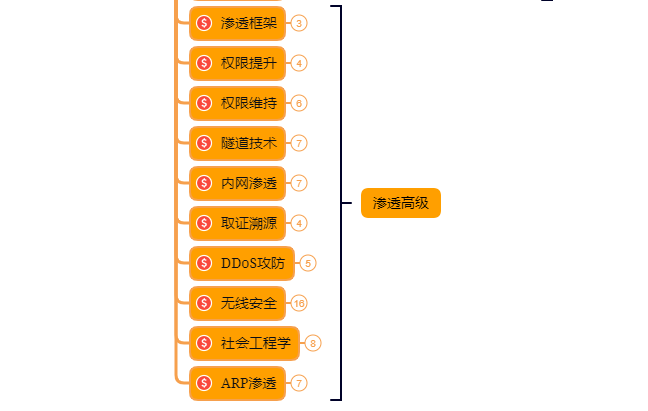
以上就是入门阶段
第三阶段:进阶
已经入门并且找到工作之后又该怎么进阶?详情看下图
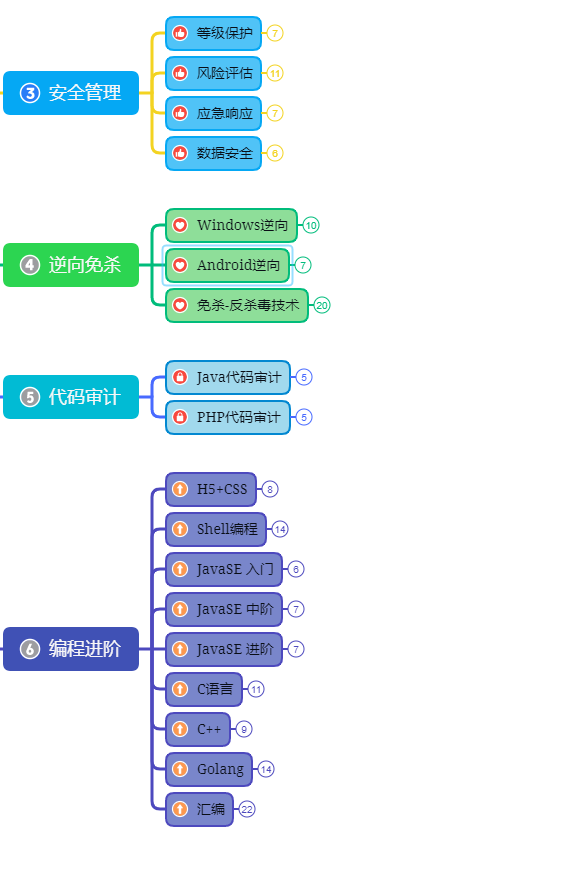
给新手小白的入门建议:
新手入门学习最好还是从视频入手进行学习,视频的浅显易懂相比起晦涩的文字而言更容易吸收,这里我给大家准备了一套网络安全从入门到精通的视频学习资料包免费领取哦!
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









