







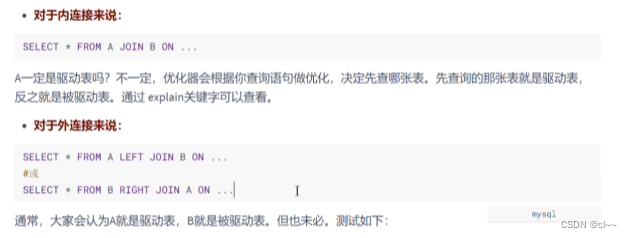
1.概述
A表通过外键(A.f_id == B.f_id)连接B表
当A表的f_id和B表的f_id都没有索引或者两个表都有索引时,以小表(记录少)作为驱动表
当其中一个表有索引而另一个表没有索引时,有索引的表作为被驱动表

2.驱动表和被驱动表
驱动表是主表,被驱动表是从表,非驱动表
在关联时,驱动表需要有优化器决定
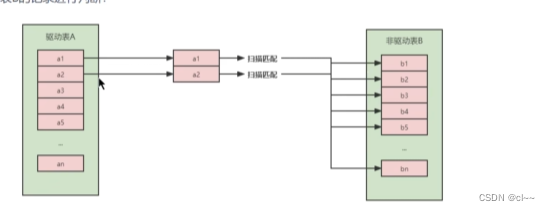
3.简单嵌套循环连接(Simple Nested-Loop Join)
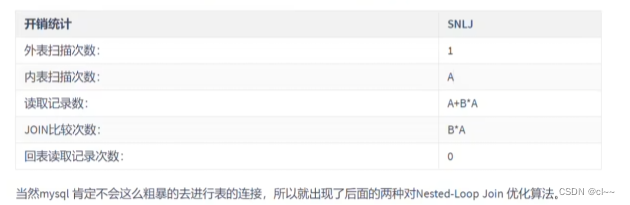
从A表中取出一条记录,遍历B表,将匹配到的记录放入结果集
4.索引嵌套循环连接(Index Nested-Loop Join)
为了减少内层表数据的匹配次数,要求被驱动表上必须有索引才可以。通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较
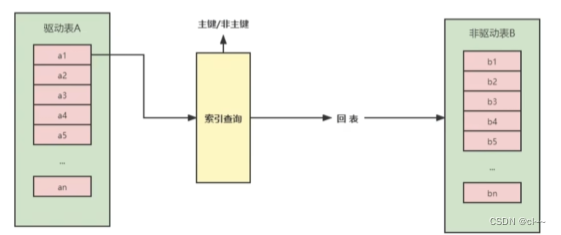
如果被驱动表的索引是主键,则不需要回表,效率更高
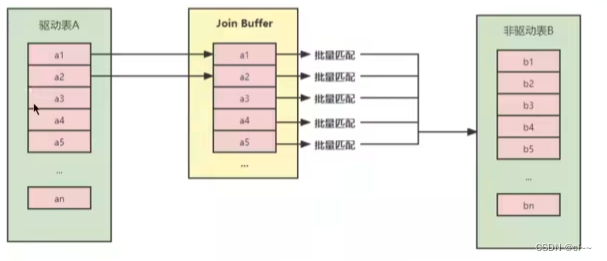
5.块嵌套循环连接(Block Nested-Loop Join)
将驱动表中的记录一块加入join buffer中,然后全表扫描被驱动表,被驱动表中的每一条记录一次性和join buffer中的所有驱动表记录匹配,将简单嵌套循环中的多次比较合成一次,降低了被驱动表的加入内存的次数
6.Hash Join
从mysql8.0.20开始废弃BNLJ,而引入了hash join默认使用hash join
- 对于被链接的数据子集较小时,Nested Loop是个较好的选择
- Hash Join是大数据集连接时常用的方式,优化器使用两个表中较小的表,利用Join Key在内存中建立散列表,然后扫描大的表并探测散列表,找出与Hash表匹配的行
7.总结
1)效率:INLJ > BNLJ > SNLJ
2)小结果集驱动大结果集
3)为被驱动表的条件增加索引,以减少内层表的循环匹配次数
4)增大join buffer大小
5) 减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









