










UW-CSE at SemEval-2016 Task 10: Detecting Multiword Expressions and
Supersenses using Double-Chained Conditional Random Fields 论文解读
github:https://github.com/mjhosseini/2-CRF-MWE
一、Introduction
将文本切分为最小的单元与用语义类标记这些单元密切相关。
与其他的CRF一样2-CRF是一个特征概率模型,即能表现出特征和标签之间的概率依赖,也能表现出连续的字词之间的概率依赖。
2-CRF用两个平行的标签链表示MWE和超感知序列之间的局部依赖关系,将两者之间的相互关系限制在局部,单一词语位置上,以标签的限制来确保全局性。
二、Task:检测最小语义
每一个名词或者动词都会有一个超感知标签,名词有26个超感知标签,动词有15个,只有MWE的首个单词才会被标记上超感知标签(自我感觉这个BIO标记法的B开头标记类似)
三、Model
1、Baseline:多元逻辑回归,预测句子中每一个单词对应的标签
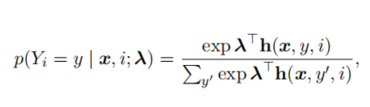
其中h是特征向量,描述了token(i)和它临近的token(x,y)之前的关系,(y代表token(x)的标签)。 入 则是一个特征权重向量,需要通过训练从数据中学习。
对于第i个word的标签预测,限制依赖于第i-1个word的标签预测结果(即个第i个的标签预测跟前一个的特征相关)
2、链式条件随机场
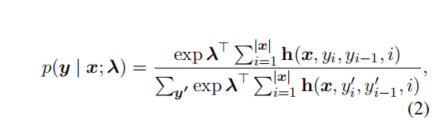
入 代表所有的位置(即所有的word)和句子共享的特征权重向量。
特征向量h 则 包含了零阶特征和一阶特征,
一阶特征建立了第i个word 和 第i+1个word之间的标签的依赖关系模型。
使用L-BFGS算法学习特征权重向量 入,
L-BFGS详细参考:https://www.cnblogs.com/zyfd/p/10120036.html
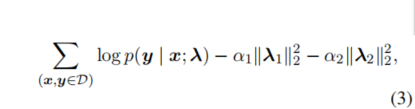
D表示所有的(word,tag),入1 入2 对应零阶特征和一阶特征,a1 a2 是对应的正则化强度。
3、双链式条件随机场
该模型已被用于词性标注和名词短语分词,它将标签分为多种MWE和超感知标注
2-CRF分离了MWE和超感知标签的零阶特性,

x是整个句子,对于第 i 位置的标记,它MWE标签是mi ,它的超感知标签是 si。
如果mi 和 si 对之前的所有特征权重 入 为零,则2-CRF模型对于这两个任务则等效于分为两个独立的CRF,因此具有一定的灵活性,也就是说2-CRF模型具有较好的泛化能力。
对于具有有效标号序列y=(m,s) 其条件概率定义为:
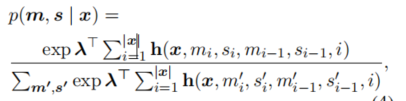
其中x代表着一个句子,(m,s)为一个标签序列
如:x=(歇斯底里 地 哭了 ) (m,s)=((m1,s1),(m2,s2),(m3,s3))
m就是一个多词表达的标签,s是超感知标签(为多词表达的开头第一个word的标签)
特征向量h可以表示为:
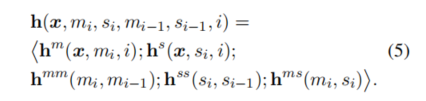
也就是h包含的特征有:零阶特征的MWE标签mi和超感知标签si,以及mi,mi-1、 si,si-1 、
mi,si 之间的一阶特征。
跟CRF类似,在训练和预测期间都会对MWE标签序列进行约束。使得每一个多次表达的开头一定是B-mwe_class 而不是I-mwe_class 那么则为一个有效的多词表达
4、结构感知机 (Structured perceptron)
SP
参考 https://www.cnblogs.com/en-heng/p/6416297.html
5、标注方法:
O Not part of or inside any MWE
o Not part of any MWE, but inside the gap of an MWE
B First token of an MWE, not inside a gap
b First token of an MWE, inside the gap of another MWE
I Token continuing an MWE, not inside a gap
i Token continuing an MWE, inside the gap of another MWE
四、代码实践
声明:由于上面论文github中找不到对应的模型构建代码,只有大部分的数据处理代码(而且代码看起来好多好乱。。。),而且双链式来做识别个人感觉可能比不过现在的Bi-LSTM+CRF 进行抽取,在此借用命名实体识别的方法来做做多词表达的抽取。
首先假设有三种多次表达类型(实际可能几十种)
标注方式使用 简单的BIO ,论文里面用的是超感知标签标记mwe_class的开头 再结合的BIO进行标注(而且还分B,b,I,i,O,o),操作起来有点小麻烦。
**注:**本代码实践操作中是抽取的是具体到某一个多次表达类别上去,如果知识单纯的想抽取多词表达而不是连同类别一起识别,那会更加容易操作,但是简单的BIO标注可能无法识别出嵌套多次表达,就是一个多次表达中嵌套了另外的一个多次表达。
三种标注的话那么就直接b-a,i-a,b-b,i-b,b-c,i-c,o 其中类别去标记每一个子。
下面请看代码:(基于keras实现的,大部分是数据处理转化成输入所需要的形式)
这里是只拿了3000条数据做训练500条数数据做测试而已。
'''最原始的数据是长这样子的哈,每一个数字代表一个字,/a /b /c 可以表示这是一个多词表达类别 o则代表啥都不是
17325_19285_6042_20691_8649_3868_16712_7664_15033_3988_16712_16496/o 16470_6000_19365/c 20620_16885_4846_3809_5759_21224_16546_3133_2432_2041_21224_16496_1027_9199_13751_11123_7747_2379_12617_4846_4935_9679_21224_12252_6036_19315_14132_21224_19421_1202_17166_5540_21224_11276_2379_17834_16254_15274/o
3545_7105/o 19832_15762/b 16805_2969_3948_3948_10609_11541_16419/o 4246_7659_17457_21115_12302/a 6196_9187_8197_3647_5810_13940_10789_7706_8041_17409/o 17219_9196/b 19421_1856_7664/o 17622_19832/b 19421_1856_16712_14459_18962_15034_20129_20583_7106_21224_19832_9779_5863_7007_19421_1856_16712_14459_18962_15034_2003_5390_8772_15692_15274/o
14132_10072_8041_19356_21224_7384_4846_9701_15556_21224_1027_9701_15712_12617_16512_4216_20859_3343_15692_8197_4106_2289_21209_1847_4935_9679_13040_13040_9701_15712_4216_3445_2379_9701_968_21224_9701_968_16512_7384_4846_4104_5626_9701_15556_8197_14978_7706_18053_21224_8387_9701_15712_16512_17145_9701_15556_968_7664_4570_7664_17773_8197_416_4104_2641_1847_15274/o
'''下面我们会通过load_data函数进行转换
所需环境
import numpy as np
from collections import Counter
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Bidirectional, LSTM, Dropout, Activation
from keras.callbacks import EarlyStopping
from keras_contrib.layers import CRF
import pickle
from keras.optimizers import Adam
from keras_contrib.metrics import crf_accuracy
from keras_contrib.losses import crf_loss
load_data进行初始数据的处理转化
train_data_path='mwe_data.txt'
test_data_path='mwe_test_data.txt'
#返回每一行数据的以字位单位的列表和对应的标签序列
def load_data(data_path):
data_file = open(data_path, 'r', encoding='utf-8')
data_lines=data_file.readlines()
data_file.close()
data_x = []
data_y = []
for line in data_lines:
line_cells = line.split(' ')
temp_x = []
temp_y = []
for cells in line_cells:
cell = cells.split('/')
temp_x.append(cell[0].split('_'))
temp_y.append(cell[1].strip())
data_x.append(temp_x)
data_y.append(temp_y)
real_data_x=[]
for sentence in data_x:
temp_sentence = []
for token in sentence:
for word in token:
temp_sentence.append(word)
real_data_x.append(temp_sentence)
real_data_y=[]
for s_index, sentence in enumerate(data_x):
temp_y = []
tokens_tag = data_y[s_index] #一个短语序列的标签,为一个列表
for i, token in enumerate(sentence): #遍历每一个词
for j, word in enumerate(token):
if tokens_tag[i] == 'o':
temp_y.append('o')
elif j == 0:
temp_y.append('b_' + tokens_tag[i])
else:
temp_y.append('i_' + tokens_tag[i])
real_data_y.append(temp_y)
return np.array(real_data_x),np.array(real_data_y)
此函数返回的数据输出样式:
train_data_x,train_data_y=load_data(train_data_path)
test_data_x,test_data_y=load_data(test_data_path)
for temp in train_data_x[0]:
print(temp,end=' ')
print()
for temp in train_data_y[0]:
print(temp,end=' ')
'''输出的数字在此书代表着一个字,每个字被标上对应的标签,本来这些数字应该是一个一个独立的字的。
7212 17592 21182 8487 8217 14790 19215 4216 17186 6036 18097 8197 11743 18102 5797 6102 15111 2819 10925 15274
b_c i_c i_c o o o o o o o o o o o o o o o o o
'''
#处理data数据 成为对应的id序列
def process_data(data_x,data_y, vocab, tags, maxlen=None, onehot=False): # vocab是字频词典
if maxlen is None:
maxlen = max([len(sentence) for sentence in data_x])
word2idx = dict((word, id) for id, word in enumerate(vocab))
x_word_id = [[word2idx.get(word.lower(), 1) for word in sentence] for sentence in data_x] # 将每一行的data转化为对应的id, 设置未知词的下标为1
y_tag_id = [[tags.index(tag) for tag in sentence_tag] for sentence_tag in data_y] #将data_y转化位 tag的id 序列(0,1,2,3,4,5,6)
#np.argwhere(tags==tag)[0][0] 是找到对应tag的下标
x_word_id = pad_sequences(x_word_id, maxlen) # left padding 在左边补零
y_tag_id = pad_sequences(y_tag_id, maxlen, value=-1) #用-1补充
if onehot:
y_tag_id = np.eye(len(tags), dtype='float32')[y_tag_id]
else:
y_tag_id =np.expand_dims(y_tag_id, 2) #扩成三维度
return x_word_id, y_tag_id #每一行数据的id序列,和对应的标签id序列
word2idx 是 vocab词汇表中每一个字对应的index 字典
y_tag_id 是将每一行数据 中的每一个字的标签转化为对应的 id (总共有7种)
x_word_id则是将每个字转化为id (前面每一个字用一个数字表示,那个数字不是id,这里在词典中最终表示的才是id)
然后使用对应数据集合中长度最大的那一条数据的长度作为maxlen,后座padding,用0值padding,在后面神经网络加层的时候可以设置mask参数,训练中自动忽略零值,相当于实现了变长输入。即在embedding层的时候input_length是可变的,也就是对应的Bi-LSTM层的time_setp是可变的。
这个后面再细说。
此处输出的数据x_word_id,y_tag_id跟下面get_data函数输出数据格式相同,下面说。
conf_file_path='config.pkl'
def get_data(data_path,test=False,maxlen=None,low_frequency=2):
data_x,data_y=load_data(data_path)
if test==False:
word_counts = Counter([word.lower() for sentence in data_x for word in sentence]) #计算字典
vocab = [word for word, freqency in iter(word_counts.items()) if freqency >= low_frequency] #计算词频 并过滤
tags=['o','b_a','i_a','b_b','i_b','b_c','i_c'] #a,b,c在此可以代表三种类别的多词表达
with open(conf_file_path, 'wb') as conf_file: #存储字典列表和标签
pickle.dump((vocab,tags), conf_file)
data_x,data_y = process_data(data_x ,data_y, vocab, tags,maxlen= maxlen, onehot=False)
return (data_x,data_y),(vocab, tags)
else:
with open(conf_file_path, 'rb') as conf_file:
(vocab, tags) = pickle.load(conf_file)
data_x,data_y = process_data(data_x ,data_y, vocab, tags,maxlen= maxlen, onehot=False)
return (data_x,data_y)
如果进来的是训练集,那么就构建一个词汇表,以及字典和频率,过滤掉频率低于low_frequency的字,顺便把词汇表和tags标签组合存放
如果是转化测试集的话,那就直接读取已有的词汇表和tags标签组合,然后进行数据转化为id序列
(data_x,data_y),(vocab,tags)=get_data(train_data_path)
#不约束maxlen的话就按照最长的数据为最大。
data_x.shape,data_y.shape
#((3000, 280), (3000, 280, 1))
len(vocab) #次数演示上的数据量比较少
#2557
#大概是这样子,每一行输入maxlen是280
接下来就是构建模型了,调用keras相对比较简单,原理可看看前几篇文章。
简单说就是用bi-lstm捕获每一条句子中的前后信息,特征表示更加明显,后crf 则是 第 i 前面的 i -1 个的预测结果算出自己属于每一个标签类别的概率得分。
def bi_lstm_crf_model(train_data_path=None,test_data_path=None):
if train_data_path!=None and test_data_path!=None:
(train_x,train_y),(vocab,tags)=get_data(train_data_path,test=False)
(test_x,test_y)=get_data(test_data_path,test=True)
else:
with open(conf_file_path, 'rb') as conf_file:
(vocab, tags) = pickle.load(conf_file)
model = Sequential()
model.add(Embedding(input_dim=len(vocab),output_dim= embed_dim, mask_zero=True))
# 内部随机embedding,如果有bert嵌入矩阵估计更好 mask_zero设置为True才能够变长输入,即 句子输入可以长度,padding的零值在训练中会被忽略
model.add(Activation('relu'))
model.add(Bidirectional(LSTM(lstm_unit,return_sequences=True)))
model.add(Dropout(drop))
model.add(Activation('relu'))
crf = CRF(len(tags), sparse_target=True)
model.add(crf)
optimizer=Adam(1e-3)
model.compile(optimizer=optimizer, loss=crf_loss, metrics=[crf_accuracy])
if train_data_path!=None and test_data_path!=None:
model.summary()
return model, (train_x, train_y), (test_x, test_y)
else:
return model, (vocab, tags)
在此的embedding权重矩阵是随机keras内部随机嵌入的,如果有预训练模型训练好的权重矩阵,效果估计会更佳。
训练模型:
model_path='bi_lstm_crf.h5'
def train_model(train_data_path,test_data_path):
model, (train_x, train_y), (test_x, test_y) = bi_lstm_crf_model(train_data_path,test_data_path)
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
print(test_y.shape)
callback=EarlyStopping(monitor='val_crf_accuracy',patience=1,verbose=1)
#patience设置为1意思是当val_acc不再上升时再多训练一个epoch就停止训练。
model.fit(train_x, train_y, batch_size=b_size, epochs=epoch, validation_data=[test_x, test_y],callbacks=[callback])
model.save(model_path)
embed_dim=200
lstm_unit=100
drop=0.4
b_size=32
epoch=5
train_model(train_data_path,test_data_path)

process_pre_data 函数用来预处理要进行预测的数据格式,lengths存放每一条预测数据原始的长度,在padding之后才能通过lengths来截取到原始的长度。
def process_pre_data(data, vocab, maxlen=None): #将data字符转化为id 566
word2idx = dict((word, index) for index, word in enumerate(vocab))
x_id = [[word2idx.get(word.lower(), 1) for word in sentence] for sentence in data]
lengths = [len(sentence) for sentence in x_id]
if maxlen==None:
maxlen = max(lengths)
x_id = pad_sequences(x_id, maxlen) # left padding
return x_id, lengths
这段评分代码我写得有点乱。。没啥好解释的,注释都打在里边了。
#字标注得分
def get_word_score(data_path,maxlen=566):
print('get word score')
model, (vocab, tags) = bi_lstm_crf_model()
test_x, test_y = load_data(data_path)
test_y=[[tags.index(tag) for tag in sentence_tag ]for sentence_tag in test_y ] #转化为标签id序列
pre_test_x, lengths = process_pre_data(test_x, vocab,maxlen=maxlen) # lengths存放每一行数据的长度,方便后面截断掉前部分的padding出来的
print('pre_test_x shape:',pre_test_x.shape)
print('pre_y_len:',len(lengths))
model.load_weights(model_path)
tags_id_predict = model.predict(pre_test_x)
print('tags_id_predict shape:',tags_id_predict.shape) # one-hot 形式 n*maxlen*len(tags)
tags_id_pre = [] #存放标签的id序列 与 test_y相对应
tags = np.array(tags)
for i, sentence_tags_id in enumerate(tags_id_predict):
sentence_tags_id = sentence_tags_id[-lengths[i]:] # 截断掉前面的padding部分
sentence_tags_id = np.argmax(sentence_tags_id, axis=1).astype('int32') # 每一行的字标签的index 也就是id
tags_id_pre.append(sentence_tags_id) # 对每一行求出最大值的index
tags_id_pre=np.array(tags_id_pre)
test_y=np.array(test_y)
all_count=0
correct_count=0
for i,true_y in enumerate(test_y): #判断预测的 标签id 的正确数目
pre_y=tags_id_pre[i]
for j,true_tag in enumerate(true_y):
pre_tag=pre_y[j]
if true_tag==pre_tag:
correct_count+=1
all_count+=1
print('word_tag_acc:',correct_count*100/all_count,'%')
'''
get word score
pre_test_x shape: (500, 566)
pre_y_len: 500
tags_id_predict shape: (500, 566, 7)
word_tag_acc: 90.05589649376539 % #加大训练会更高的,这里epoch 才5次,而且训练数据才3000
'''
#词标注得分,以及序列切分得分
def load_token(data_path):
data_file = open(data_path, 'r', encoding='utf-8')
data_lines = data_file.readlines()
data_file.close()
data_x = []
data_y = []
for line in data_lines:
line_cells = line.split(' ')
temp_x = []
temp_y = []
for cells in line_cells:
cell = cells.split('/')
temp_x.append(cell[0].strip())
temp_y.append(cell[1].strip())
data_x.append(temp_x)
data_y.append(temp_y)
data_x=np.array(data_x)
data_y=np.array(data_y)
return data_x,data_y
load_token函数加载原始的数据的一个一个多词表达的原始样式和标签。
输入的数据是原始的数据
输出的数据格式:
test_data_token,test_data_tag=load_token(test_data_path)
test_data_token[0],test_data_tag[0] #'16470_6000_19365' 则可以视为一个多次表达c

以下获取唯一位置对应的每一个抽取出来的多次表达的位置的准确率以及他们标签的准确率
#判断每一个多词表达是否一一对应和它的类别是否一一对应
def get_token_score(data_path,maxlen=566):
print('get token score')
test_token_x,test_token_y=load_token(data_path)
model, (vocab, tags) = bi_lstm_crf_model()
test_x, test_y = load_data(data_path)
pre_test_x, lengths = process_pre_data(test_x, vocab,maxlen=maxlen) # lengths存放每一行数据的长度,方便后面截断掉前部分的padding出来的
model.load_weights(model_path)
tags_id_predict = model.predict(pre_test_x)
print('pre_test_x shape:', pre_test_x.shape)
print('pre_y_len:', len(lengths))
print('tags_id_predict shape:', tags_id_predict.shape) # one-hot 形式 n*maxlen*len(tags) n*566*7
tags_pre = [] #每一个字对应的标签
tags = np.array(tags)
for i, sentence_tags_id in enumerate(tags_id_predict):
sentence_tags_id = sentence_tags_id[-lengths[i]:] # 截断掉前面的padding部分
sentence_tags_id = np.argmax(sentence_tags_id, axis=1).astype('int32') # 每一行的字标签的index 也就是id
tags_pre.append(tags[sentence_tags_id]) # 取出每一行的每个字的标签
#先计算出每一个字的标签,后面方便计算每一个多字组合(token)对应的标签
word_tags_pre = [] #存放每个字的标签 word/tag
for i, sentence in enumerate(test_x): # 遍历每行数据
sentence_tags = tags_pre[i] # 每一行数据的tag
count = 0
sentence_tag = ''
for word, tag in zip(sentence, sentence_tags):
if count != 0 or count != len(word):
sentence_tag += ' ' # 不是第一个和最后一个就加上个空格
count += 1
if tag == 'o':
sentence_tag += word + '/o'
else:
sentence_tag += word + '/' + tag.split('_')[1]
word_tags_pre.append(sentence_tag)
token_tags_pre = [] # 每一行为一条数据的若干个token/tag
for sentence_tag in word_tags_pre:
sentence_tag = sentence_tag.strip().split(' ')
token_tag_of_sentence = ''
length = len(sentence_tag)
for i in range(length):
word_tag = sentence_tag[i].split('/')
word = word_tag[0]
tag = word_tag[1]
if i != 0:
if tag == sentence_tag[i - 1].split('/')[1]: # 比较是否与上那个一个字的标签相同,相同的话持续加上
token_tag_of_sentence += '_' + word
else:
token_tag_of_sentence += '/' + sentence_tag[i - 1].split('/')[1] + ' ' + word # 不同的话就在前面加上前一个token的标签
else:
token_tag_of_sentence = word # 如果是第一个字,就直接复制
if i == length - 1: # 如果是最后一个则补上当前标签
token_tag_of_sentence += '/' + tag
token_tags_pre.append(token_tag_of_sentence)
pre_token_x=[] #与test_x
pre_token_y=[] #与test_y对应
for token_tag_of_sentence in token_tags_pre: #token_tag_of_sentence意思就是每一行数据的多个字的组合(token)对应的标签(a,b,c,o)
temp_x=[]
temp_y=[]
for token_tag in token_tag_of_sentence.split(' '): #token_tag 就是token/tag 表示的字符串
temp_x.append(token_tag.split('/')[0])
temp_y.append(token_tag.split('/')[1])
pre_token_x.append(temp_x)
pre_token_y.append(temp_y)
token_correct=0
token_all=0
print('test_token_x length:',len(test_token_x))
print('pre_token_x length:',len(pre_token_x))
for i,te_x in enumerate(test_token_x):
pre_x=pre_token_x[i]
token_all+=len(pre_x)
for j in range(min(len(pre_x),len(te_x))): #比较到最短的序列完为止
if pre_x[j]==te_x[j]:
token_correct+=1
print('token_acc:',token_correct*100/token_all,'%')
tag_correct=0
tag_all=0
for i,te_y in enumerate(test_token_y):
pre_y=pre_token_y[i]
tag_all+=len(pre_y)
for j in range(min(len(pre_y),len(te_y))): #比较到最短的序列完为止
if pre_y[j]==te_y[j]:
tag_correct+=1
print('token_tag_acc:',tag_correct*100/tag_all,'%')
# for result in token_tags_pre[:10]:
# print(result)
return token_tags_pre
'''
get token score
pre_test_x shape: (500, 566)
pre_y_len: 500
tags_id_predict shape: (500, 566, 7)
test_token_x length: 500
pre_token_x length: 500
'''
token_tags_pre=get_token_score(test_data_path)
token_tags_pre[0]
#输出的结果格式如下,每一行被划分为几个多字组合(token) 然后被标上相应的标签类别
‘17325_19285_6042_20691_8649_3868_16712_7664_15033_3988_16712_16496/o 16470_6000/b 19365_20620_16885_4846_3809_5759_21224_16546_3133_2432_2041_21224_16496_1027_9199_13751_11123_7747_2379_12617_4846_4935_9679_21224_12252_6036_19315_14132_21224_19421_1202_17166_5540_21224_11276_2379_17834_16254_15274/o’
下面来一下具体输出:
token_of_sentence_tags=[]
for sentence in token_tags_pre:
dic={'a':[],'b':[],'c':[],'o':[]}
tokens=sentence.split(' ')
for token in tokens:
cells=token.split('/')
dic[cells[1]].append(cells[0])
token_of_sentence_tags.append(dic)
for temp in token_of_sentence_tags[:10]:
print(temp)
'''每一行数据对应出来的多次表达组合,训练不足原因,可能部分没抽出来
{'a': [], 'b': ['16470_6000'], 'c': [], 'o': ['17325_19285_6042_20691_8649_3868_16712_7664_15033_3988_16712_16496', '19365_20620_16885_4846_3809_5759_21224_16546_3133_2432_2041_21224_16496_1027_9199_13751_11123_7747_2379_12617_4846_4935_9679_21224_12252_6036_19315_14132_21224_19421_1202_17166_5540_21224_11276_2379_17834_16254_15274']}
{'a': ['9196_19421_1856'], 'b': ['19832_15762', '4246_7659', '17622_19832'], 'c': [], 'o': ['3545_7105', '16805_2969_3948_3948_10609_11541_16419', '17457_21115_12302_6196_9187_8197_3647_5810_13940_10789_7706_8041_17409_17219', '7664', '19421_1856_16712_14459_18962_15034_20129_20583_7106_21224_19832_9779_5863_7007_19421_1856_16712_14459_18962_15034_2003_5390_8772_15692_15274']}
{'a': [], 'b': [], 'c': [], 'o': ['14132_10072_8041_19356_21224_7384_4846_9701_15556_21224_1027_9701_15712_12617_16512_4216_20859_3343_15692_8197_4106_2289_21209_1847_4935_9679_13040_13040_9701_15712_4216_3445_2379_9701_968_21224_9701_968_16512_7384_4846_4104_5626_9701_15556_8197_14978_7706_18053_21224_8387_9701_15712_16512_17145_9701_15556_968_7664_4570_7664_17773_8197_416_4104_2641_1847_15274']}
{'a': [], 'b': [], 'c': [], 'o': ['1819_2658_2557_21224_6040_18496_11123_19215_4216_16046_1965_5863_1819_19311_2128_12333_10627_11043_4244_6891_19654_10536_4929_974_8197_968_7501_15274']}
{'a': [], 'b': [], 'c': [], 'o': ['17409_10925_19311_7438_8505_6102_11068_16374_21224_19315_14132_11679_5647_14199_4859_19215_18158_17597_4846_17219_5647_10619_8197_4106_4988_3486_15274']}
{'a': [], 'b': ['16468_19134'], 'c': [], 'o': ['17219_20027_14244_1984_6102_2819_20359_2483_17225_7706_21195_17219_14033_5797_6102_1984_3277_21224_1819_19285_14684_11123_717_19987_19356_18173_159_8505_6102_968_17186_21224_4819_12052_10925_21097_19285_16496_9089_17145_1984_3277_1027_1961', '11385_4163_16468_16929_12617_8197_8344_18173_15274']}
{'a': [], 'b': [], 'c': [], 'o': ['15964_16512_8379_586_10609_3545_8523_20583_13862_6102_9391_11188_3948_11664_11664_1668_3166_882_11367_4921_7105_9267_21224_19421_20583_15345_400_16906_9860_18541_17681_15274']}
{'a': [], 'b': ['417_20684'], 'c': ['11990_2573'], 'o': ['20380_19421_19517_18158', '10571_20821_20808_6181_10925_20201_17622_2128_15799_10083_7706_5852_15274']}
{'a': [], 'b': ['8489_18850'], 'c': [], 'o': ['15788_14123_17219_1223_19311_7438_2256_19675_20743_6135', '11806_11123_9180_10925_15274']}
{'a': [], 'b': [], 'c': [], 'o': ['5026_2289_11702_567_7706_13751_19365_12302_21224_16113_20027_12751_4581_5808_16623_8197_1514_13494_6437_20451_19356_18173_159_3647_5810_21224_19220_19092_3647_5810_6623_14582_16712_19061_15274_12617']}
'''















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









