







 BM算法是一种字符串匹配算法,通过坏字符策略(BC策略)和好后缀策略(GS策略)优化匹配过程。BC策略利用模式串中字符的最右侧位置来确定位移量,GS策略则利用已匹配的子串信息。BC策略在字母表大时表现优秀,最坏情况为O(nm);GS策略进一步提升性能,使得最坏情况为O(n+m)。
BM算法是一种字符串匹配算法,通过坏字符策略(BC策略)和好后缀策略(GS策略)优化匹配过程。BC策略利用模式串中字符的最右侧位置来确定位移量,GS策略则利用已匹配的子串信息。BC策略在字母表大时表现优秀,最坏情况为O(nm);GS策略进一步提升性能,使得最坏情况为O(n+m)。
在串匹配中,靠后的字符的失配能更多地排除待匹配的字符,也就是说模式串中越靠后的字符对算法的优化作用更大。因此BM算法将匹配的方向颠倒过来,从右向左进行匹配,即在每一趟比对中都从末字符开始比对。以下设文本串为T[],长度为n,模式串为P[],长度为m。
坏字符策略(BC策略)
某趟扫描中一旦发现T[i+j] == X!= Y ==P[j],则模式串P右移,并启动新的一轮比对。
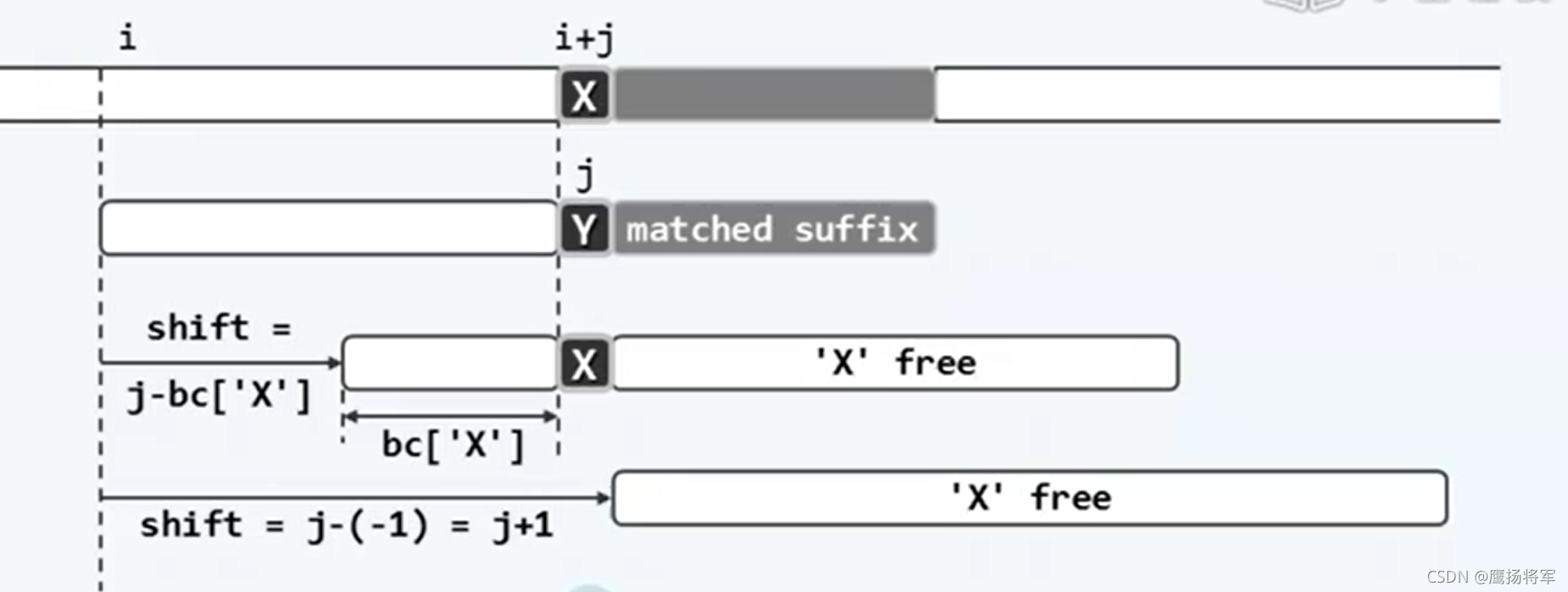 如上图,其中Y称作坏字符。此次失配后,若还想在文本串T的X附近产生一次匹配,则需要在模式串P中找到另外一个X,并将模式串P右移,使之与文本串T中的X对齐,接着从模式串P的最右端开始,启动下一次扫描比对。而模式串右移的位移量取决于失配位置j和X在模式串P中的位置,与文本串T无关,因此可以将每个字符对应的位移量事先计算出来。此计算可通过bc[]表实现,这个表记录了字母表中每一个字符在模式串中最靠右的秩。
如上图,其中Y称作坏字符。此次失配后,若还想在文本串T的X附近产生一次匹配,则需要在模式串P中找到另外一个X,并将模式串P右移,使之与文本串T中的X对齐,接着从模式串P的最右端开始,启动下一次扫描比对。而模式串右移的位移量取决于失配位置j和X在模式串P中的位置,与文本串T无关,因此可以将每个字符对应的位移量事先计算出来。此计算可通过bc[]表实现,这个表记录了字母表中每一个字符在模式串中最靠右的秩。
模式串中可能存在多个X,因此应该选择最靠后的X,换言之,在选取的X后缀中,不能包含任何X。
若模式串中不包含X,则将整个模式串移过X继续比对。
若模式串中最靠右的X过于靠右,以至与文本串中失配字符进行对齐时模式串没有右移反而发生了左移,此时将模式串直接右移一个字符,继续比对。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









