







论文链接:https://arxiv.org/pdf/2404.16022
github:https://github.com/ToTheBeginning/PuLID
comfyui节点:GitHub - cubiq/PuLID_ComfyUI: PuLID native implementation for ComfyUI
论文亮点
-
增加了对比对齐loss和ID loss,最大限度减少对源模型的破坏并保证高保真
-
提示词可以很好的引导生成过程
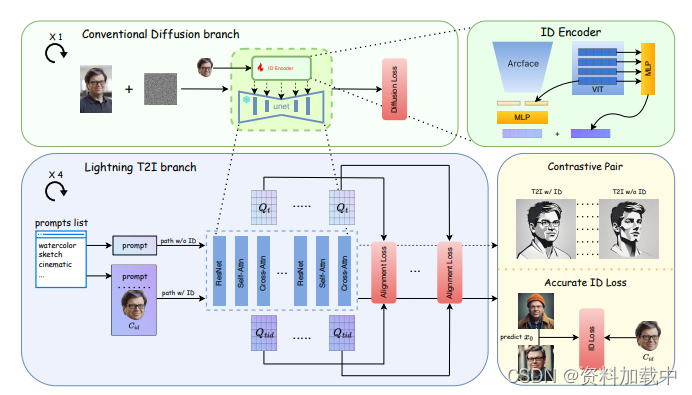
论文详解
前置知识
扩散模型的loss
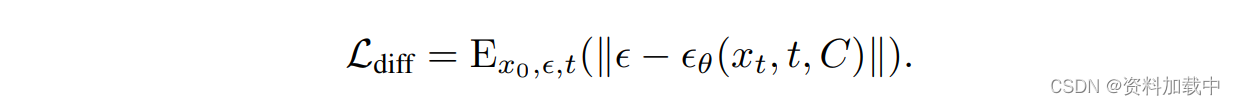
扩散模型结构主要由resnet block,self attention和cross attention组成
交叉注意力
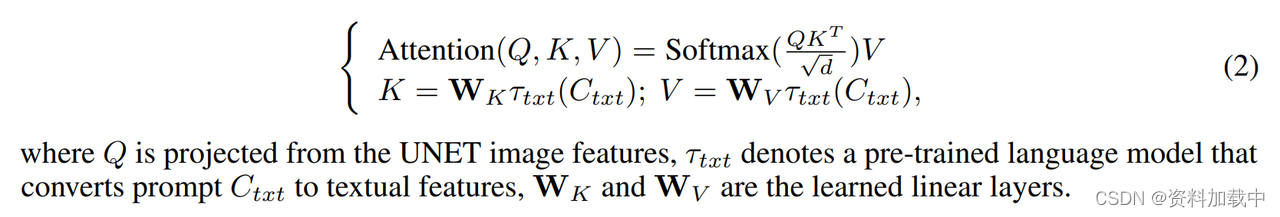
ID作为另一个条件嵌入到网络中
不需要微调的ID特征提取模型CLIP图像编码器,Arcface图像识别骨干模型加上可学习的头。将ID嵌入到基础图生图模型的有效方式是加一个平行的交叉注意力层。在这个可学习的线性层中,ID被映射为Kid和Vid,与主干网络中的Q做注意力计算。这项技术最早被ipadapter提出来。
本文同时使用了ARcface和Clip图像编码器,通过两个编码器后,分别使用MLP网络对其进行映射,并对两个向量进行了拼接。
网络结构
ID层的嵌入
ID层的嵌入会从两个方面破坏原始文生图模型
-
与没有ID嵌入之前相比,生成元素发生了大量的变化,例如背景,光线,构图和风格
-
失去提示词的控制特性,导致我们很难通过提示词改变ID属性,方向和插件
在训练过程中,提示词和id是对齐的,测试时,会改变提示词,此时ID和提示词不在对齐,会存在偏置情况。
通过对比对齐方法插入未受污染的ID,在朱分支中在插入一个没有插入ID的分支。

训练期间,在预先准备的一些提示词模板中随即挑选一个作为文本条件,对齐是在所有层和时间步上进行的。
语义对齐loss
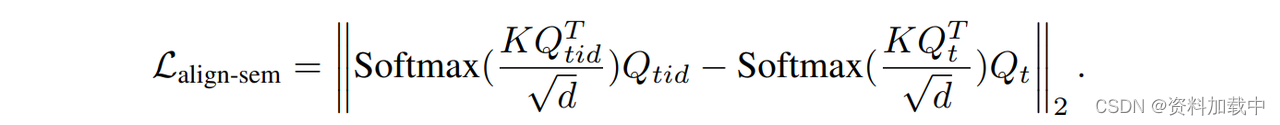
解释,就是一个Attention(K,Q,Q),两个路径的插值越小,表明ID嵌入对基础UNet的影响越小。但仅此一项并不能保证布局的一致性,所以需要加一项loss
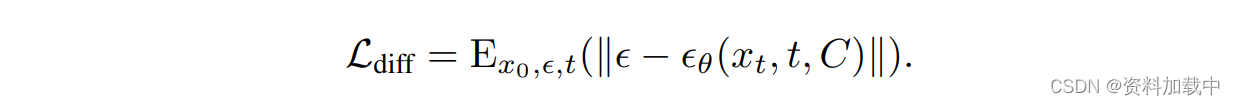
总的对齐loss
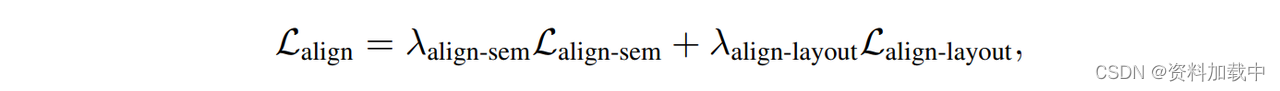
ID Loss

总的学习目标

实验细节
ID Encoder使用antelopev2作为人脸识别模型和EVA-CLIP作为CLIP图像编码器。x训练数据集是150万高质量图片,图片由BLIP-2反推打标。训练分为3个阶段;第一阶段,使用Ldiff训练传统扩散loss;第二阶段,我们在第一阶段的基础上训练ID loss(使用arcface-50来计算loss)和Ldiff;第三阶段,加入Lalign并使用全部的目标损失,设置lambda(align-layout)为0.1,lambda(id)为1.生图分辨率设置为768*768。训练是在8张A100上进行的。
效果对比




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











