






首先选择一个弹幕较多,自己喜欢的视频,进行弹幕的采集,比如我当时做项目的时候非常痴迷棋魂,选择了一个棋魂的混剪视频,采集其中的弹幕进行词类分析。
不知道提取相关数据是否是合理操作,所以隐去这段代码,提取的结果如图所示:

然后根据本数据集,画一个云图的模板,
import numpy as np
import matplotlib.pyplot as plt
x, y = np.ogrid[:300, :300]
mask = (x - 150) ** 2 + (y - 150) ** 2 > 130 ** 2
mask = 255 * mask.astype(int)
plt.imsave('cloud_shape.png', mask, cmap='gray')
然后将这些词的分析填充进模板里面,
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from snownlp import SnowNLP
excel_file = 'danmaku4.xlsx'
df = pd.read_excel(excel_file)
danmaku_texts = df['弹幕内容'].tolist()
dm_str = " ".join(danmaku_texts)
words_list = jieba.lcut(dm_str)
words_count = {}
for word in words_list:
words_count[word] = words_count.get(word, 0) + 1
# 输出词频统计
words_freq = sorted(words_count.items(), key=lambda x: x[1], reverse=True)
print("词频统计:")
for word, freq in words_freq:
print(f"{word}: {freq}")
#掩码
mask_image_path = 'cloud_shape.png'
mask = np.array(Image.open(mask_image_path))
wordcloud = WordCloud(
background_color='white',
mask=mask,
width=800,
height=600,
max_words=2000,
max_font_size=100,
min_font_size=10,
font_path='C:/Windows/Fonts/simhei.ttf',
prefer_horizontal=0.9,
relative_scaling=0.5,
collocations=False, # 避免重复单词
contour_color='steelblue'
).generate_from_frequencies(words_count)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
output_image_path = 'yumu.png'
wordcloud.to_file(output_image_path)
print(f"词云图已保存到 {output_image_path}")
positive = 0
negative = 0
for text in danmaku_texts:
s = SnowNLP(text)
if s.sentiments > 0.5:
positive += 1
else:
negative += 1
total = positive + negative
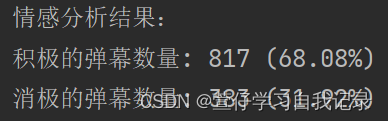
print(f"情感分析结果:")
print(f"积极的弹幕数量: {positive} ({positive / total * 100:.2f}%)")
print(f"消极的弹幕数量: {negative} ({negative / total * 100:.2f}%)")结果如下图所示:

输出的结果,借用了snownlp库的函数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









