







目录
UA检测与伪装
UA: User-Aaent(请求载体的身份标识)
UA检测:在用爬虫爬取数据的时候,我们需要进行UA伪装。因为门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某款浏览器说明该请求是个正常的请求。但是如果检测到请求的载体身份标识不是基于某款浏览器的。则表示该请求为不正常的请求(爬虫)。则服务器端就很有可能拒绝该请求。
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器。所以我们需要自定义user-agent头部信息,来绕过UA检测,我们把它放入一个字典中
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}request.get()中的参数
requests中发送get请求里面有几个基础的参数如下
requests.get(url=url,params=param,headers=headers)- url:目标url
- params:查询参数,以字典的形式进行封装。requests会自动帮我们把这个参数拼接在接口请求地址中
- headers:HTTP请求头部
案例—百度搜索
我们输入一个关键词就可以进行百度搜索,然后获取搜索到的页面信息。
方法一
1. url观察
我们搜索校园,观察到url是很长的一段字符,其实里面很多字符是不需要的,我们可以删除

简化url,我们可以把url简化成如下样子,wd值为搜索的关键字,pn值代表当前显示的所在的页面数

2. 编写代码
查询url携带了两个参数一个是wd另一个是pn,我们将其以字典的形式封装,然后赋值给params参数。requests会自动帮我们把这个参数拼接在接口请求地址中
import requests
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
url='https://www.baidu.com/s'
content = input('请输入您想查询的词:')
param = {
'wd':content,
'pn':0
}
response = requests.get(url=url,params=param,headers=headers) #三个参数
ctx = response.text
with open('1.html','w',encoding='utf-8') as df:
df.write(ctx)
print('保存成功')爬取保存后数据如下
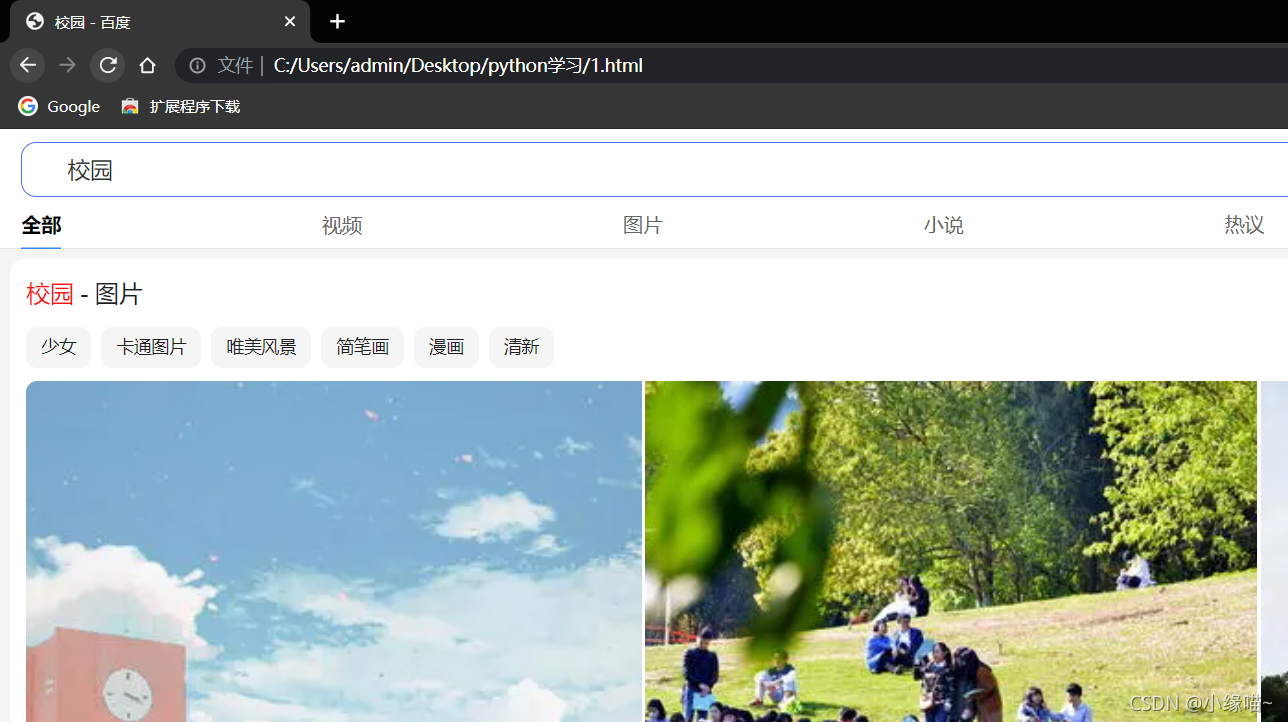
方法二
对于GET请求我们也可以不使用params参数,直接使用格式化输出方法在url中进行参数拼接就行
import requests
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
content = input('请输入您想查询的词:')
url=f'https://www.baidu.com/s?wd={content}&pn=0' #格式化输出拼接
response = requests.get(url=url,headers=headers)
ctx = response.text
with open('1.html','w',encoding='utf-8') as df:
df.write(ctx)
print('保存成功')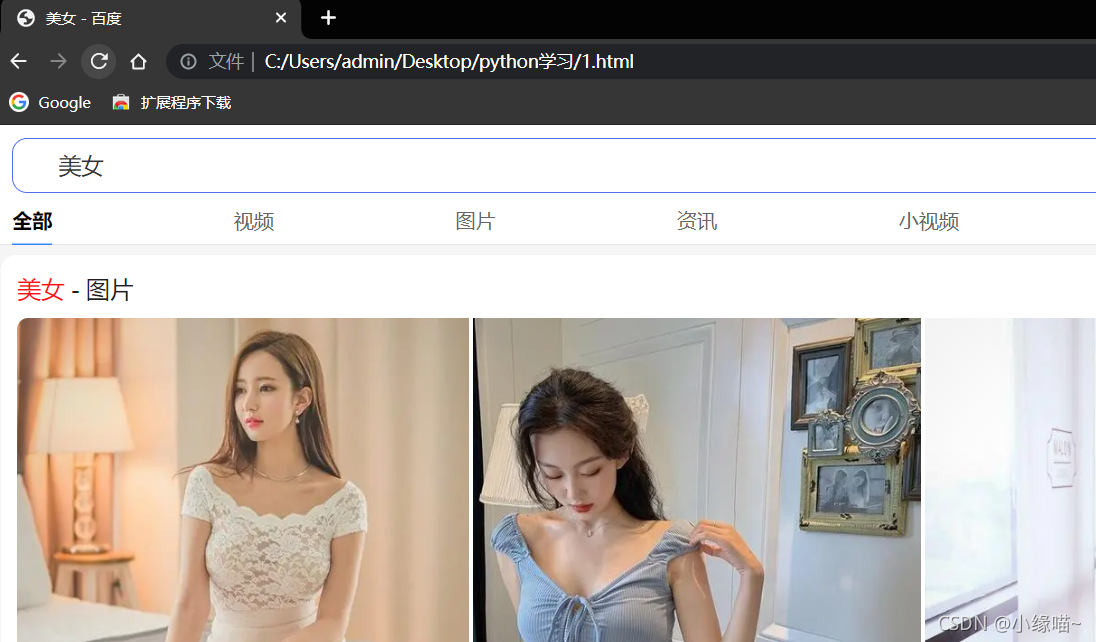


















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











