






在之前的案例中,我们所启用的服务提供方和服务消费方都只有一个,然后使用RestTemplate通过DiscoveryClient进行动态去调用服务。
但是在实际开发中,微服务一般都是以集群的形式存在的,此时我们获取的服务信息背后就会有多台服务器,那么到底应该访问哪一个呢?
一般在这个时候我们编写负载均衡算法,在多个实例列表中进行选择,不过SpringCloud已经帮我们集成了负载均衡组件:Ribbon。
什么是Ribbon?
Ribbon是Netflix发布的负载均衡器,它有助于控制HTTP和TCP客户端的行为。为Ribbon配置服务提供者列表之后,Ribbon就可基于某种负载均衡算法,自动帮助服务消费者去请求。Ribbon默认为我们提供了很多的负载均衡算法,例如轮询、随机等。当然,我们也可以为Ribbon实现自定义的负载均衡算法。
一、修改之前的案例,开启Ribbon负载均衡
首先我们需要复制一个服务提供方的测试用例,实现服务提供方的集群,然后通过负载均衡去调用服务提供方。
因为Eureka其中已经集成了Ribbon,所以不需要再多添加任何依赖,我们只需要通过在服务消费放的RestTemplate上添加注解,并且通过服务名去调用服务即可。
①启用负载均衡
@Bean
@LoadBalanced //启用Riboon负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
}
②使用服务名调用服务提供方的接口
@RequestMapping("/{uid}")
public User findByid(@PathVariable Integer uid){
// List<ServiceInstance> instances = discoveryClient.getInstances("SERVICE-PRODUCER");
// ServiceInstance serviceInstance = instances.get(0);
return restTemplate.getForObject("http://SERVICE-PRODUCER/user/findByid/"+uid,User.class);
}
通过如上方式,Ribbon就会通过服务名去按照负载均衡算法自动选择服务器进行访问,默认的负载均衡算法是轮询。
自定义负载均衡策略配置:
当我们需要给不同的微服务配置不同的负载均衡策略的时候就需要自己来配置,配置如下:
service-provider: #服务提供方的id
riboon:
NFLoadBalancerRuleClassName:com.netflix.loadbalancer.RandomRule
#参数值为负载均衡算法对象的全限定类名
Hystrix简介:
Hystrix英文意思是豪猪,是一种保护机制。
Hystrix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。
雪崩问题
微服务中,服务间调用关系错综复杂,一个请求,可能需要调用多个微服务接口才能实现,会形成非常复杂的调用链路:

如上图所示,一次业务请求,需要调用A、P、H、I四个服务,这四个服务有可能调用其他服务。
如果此时,某个服务出现异常:
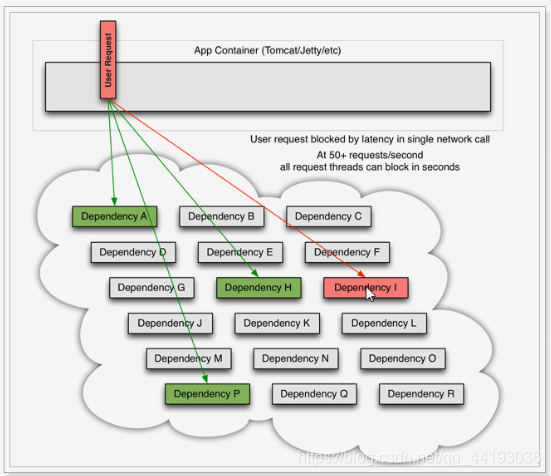
例如服务I发生异常,请求阻塞,用户不会得到响应,则tomcat这个线程不会被释放,于是越来越多的用户请求到来,越来越多的线程会阻塞。
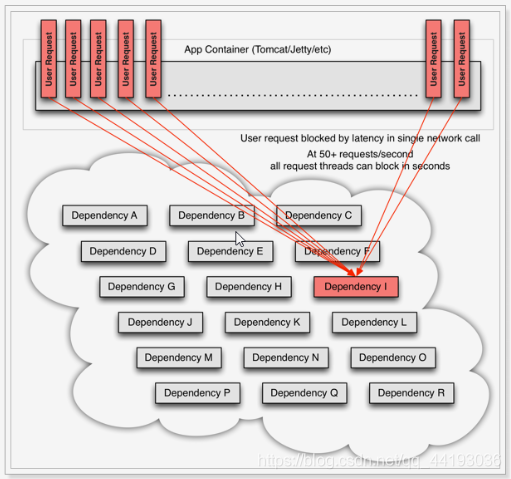
服务器支持的线程和并发数有限,请求一直阻塞会导致服务器资源耗尽,从而导致其他服务都不可用,形成雪崩效应。
Hystrix解决雪崩问题的手段有两个:
- 线程隔离
- 服务熔断
线程隔离和服务降级
Hystrix为每个依赖服务调用分配一个小的线程池,如果线程池已满则调用立即被拒绝,默认不采用排队,加速失败判定时间。
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,或者请求超时,则会进行降级处理。
降级处理:优先保证核心服务,而非核心服务不可用或弱可用。
采用线程池和服务的降级处理之后,用户的请求故障时,不会被阻塞,更不会无休止的等待或者看到系统崩溃,至少可以看到一个执行结果(例如返回的友好的提示信息)。
服务降级虽然会导致请求失败,但是不会导致堵塞,而且最多影响这个依赖服务对应的线程池中的资源,对其他服务没有影响。
触发Hystrix服务降级的条件:
- 线程池已满
- 请求超时
改造案例演示Hystrix请求服务失败进行降级之后返回提示信息:
1、在服务消费方引入Hystrix启动器
<!--引入Hystrix启动器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2、在引导类上添加注解启动熔断器

3、改造远程调用的控制器,添加熔断方法
@RequestMapping("/{uid}")
public String findByid(@PathVariable Integer uid){
// List<ServiceInstance> instances = discoveryClient.getInstances("SERVICE-PRODUCER");
// ServiceInstance serviceInstance = instances.get(0);
return restTemplate.getForObject("http://SERVICE-PRODUCER/user/findByid/"+uid,String.class);
}
//findByid()方法的熔断方法
public String findByidFallBack(Integer uid){
return "服务器正忙,请稍后再试!";
}
findByidFallBack()就是findByid()方法的熔断方法,熔断方法必须与被熔断的方法保持返回值和参数列表一致。
在此为了显示错误信息,将原来返回User实体修改为返回String字符串。
4、使用注解添加熔断方法和被熔断方法之间的关系
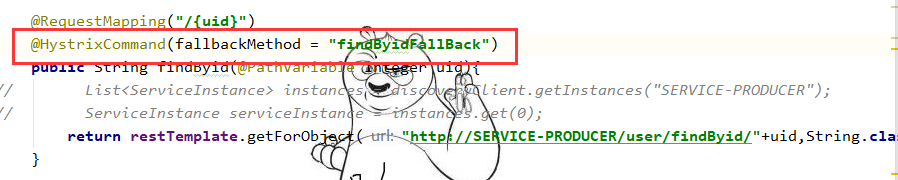
使用@HystrixCommand注解的fallbackMethod属性可以绑定对应的熔断方法。
此时,当服务请求超时或者请求失败的时候就会触发熔断器进行熔断,并且发送熔断方法中的提示信息进行较友好的提示。
配置全局熔断方法:
每一个请求服务方法都去单独配置熔断方法是非常麻烦的,我们可以在Controller类上添加@DefaultPropertis注解,通过该注解的defaultFallBack属性来配置该控制器的全局熔断方法。

配置了全局的熔断方法之后,之前在方法上配置的熔断方法就不需要配置了,但是@HystrixCommand注解还是需要的,用于声明某个拉取请求的方法需要进行熔断,因为在开发时不一定每个方法都需要进行熔断。
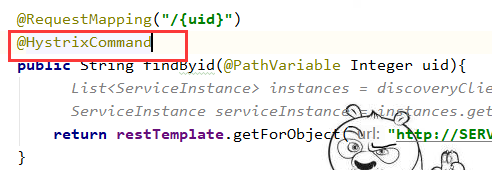
在之前定义熔断方法的时候要保证返回值和参数列表一致,此时如果定义全局的参数列表的话就不需要参数列表了。
设置Hystrix请求超时时间:
默认配置下,Hystrix在请求超过1秒之后就判定请求失败,这个时间在开发环境下是可以的。但是在生产环境下,可能会因为网络等原因导致请求超时,所以需要将这个超时时间略微设置大一点:
hystrix:
command:
default:
execution:
isolation
thread:
timeoutInMilliseconds: 6000 #设置响应超时时间为6秒
在这里演示的是当服务超时或者失败的时候,Hystrix不会让请求一直阻塞等待,而是会直接返回错误信息,减少判定时间。而此过程中仍然会持续接收前台的请求。
组合注解@SpringCloudApplication
@SpringCloudApplication组合注解相当于@SpringBootApplication、@EnableDiscoveryClient、@EnableCircuitBreaker这三个注解。
也就是说在一个类上使用@SpringCloudApplication注解就标志这个类为引导类,并且开启Eureka客户端和Hystrix熔断器。
服务熔断
熔断机制的原理很简单,就像家里的电路熔断器,如果电路发生短路能够立刻熔断电路,避免发生灾难。在分布式系统中应用这一模式之后,服务调用方可以自己进行判断某些服务反应慢或者存在大量的超时情况时,能够主动熔断,防止整个系统被拖垮。
不同于电路熔断只能断不能重连,Hystrix可以实现弹性容错,当情况好转之后,可以自动重连。
通过断路的方式,可以将后续请求直接拒绝掉,一段时间之后允许部分请求通过,如果调用成功则回到电路闭合状态,否则继续断开。
熔断器的三个状态:
- Closed:关闭状态,所有的请求都正常访问。
- Open:打开状态,所有的请求都会被降级。Hystrix会对请求情况计数,当一定时间内失败请求百分比达到阀值,则触发熔断,熔断器会完全打开。默认失败比例的阀值是50%,请求次数最少不低于20次。
- Half Open:半开状态,open状态不是永久的,打开之后会进入休眠时间(默认是5s)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会完全关闭断路器,否则持续保持打开,再次进入休眠计时。
通过相关参数修改熔断策略:
circuitBreaker.requestVolumeThreshold=10
circuitBreaker.sleepwindowInMilliseconds=10000
circuitBreaker.errorThresholdPercentage=50
requestVolumeThreshold:触发熔断的最小请求次数,默认20
sleepwindowInMilliseconds:休眠时长,默认5000毫秒
errorThresholdPercentage:触发熔断的失败请求最小占比,默认50%














 6852
6852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









