






数据结构之线性表中的链表
1.个人认为链表的重点:
- 创建链表
- 链表增删改查(也就是链表的基操)
2.单链表的定义
- 单链表的结点形式:
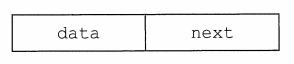
链表和顺序表最大差别就在于:顺序表的存储单元只存储数据,其位置信息全靠数组下标表示;链表的存储单元除了数据域之外,还有一个指针域,通过这个指针域获取下个结点所在的位置。 - 单链表结点的定义方式:
typedef struct LNode{
int data; //数据域
struct LNode *next; //指针域,指向结构体的指针
}LNode, *LinkList;
LNode定义了一个结点,结点中包含了数据域data和指针域next。
LNode既是标识符也是变量类型 - struct后面的LNode是标识符,结尾处的LNode是*变量类型(类似于int,char)*;
后面的*LinkList表示该结点的指针集合的意思,可以用来*定义所有将要指向结构体的指针*(很久没主C了,这个还是在大二写C语言学生管理系统的时候悟到的,有偏颇还请指正)。
LNode表示结点、LinkList指代链表
- 完整的链表形式:

观察一下,第一个结点仅仅用L表示,没有数据域。也就是说,这个链表是带头结点的链表。
那么为什么要大费周章弄个头结点呢?在这介绍一下链表引入头结点的优点是什么:
先看有了头结点带来了什么便利:处理第一个数据结点和处理其他数据结点是一样的。比如要在第一个结点前插入一个结点,如果带头结点,就在头结点后面按普通结点插入就行了。增删改查同理
如果没有头结点,需要把新节点的next连到旧的第一个数据结点,然后要把指针挪到新的第一个数据结点上,怎么挪?是不是想想就很麻烦(我比较懒,同学们可以自己拿着纸笔画一下)
3.单链表的基本操作:
- 头插法建立单链表(插入操作加建立链表的操作一锅端了):

LinkList List_Insert(LinkList &L){
LNode *s;
int x;
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL;
scanf("%d", &x);
while(x!=-1){ //结束输入的终止条件
s = (LNode)malloc(sizeof(LNode)); //开辟新空间
s->data = x; //先让新结点的值等于输入的值
s->next = L->next; //新结点的下一个结点是头结点的下一个结点
L->next = s; //移动头结点指向新插入的结点
scanf("%d", &x);
}
return L;
}
这种建立链表的方法也叫做头插法,即每次新加入一个结点到链表中都是通过在头结点后面插入结点(再次映证头结点带来的便利)。时间复杂度为O(N)
- 尾插法建立单链表
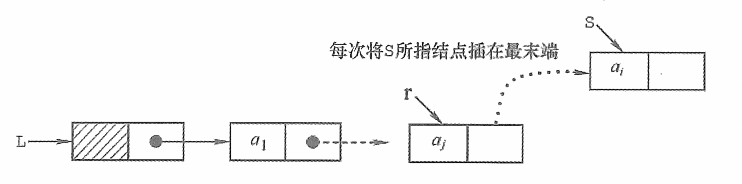
这种方式和头插法建立单链表交相呼应,无非就是插入结点的位置变为了链表的结尾。因此需要一个尾指针来指向当前链表的最末端结点。
LinkList List_TailInsert(LinkList &L){
int x;
L = (LinkList)malloc(sizeof(LNode));
LNode *s, *r = L; //把头结点指针赋值给s和r
scanf("%d", &x);
while(x!=-1){
s = (LNode)malloc(sizeof(LNode));
s->data = x; //s指向的是当前的结点
r->next = s;
scanf("%d", &x);
}
r->next = NULL; //r每次都指向尾结点
return L;
}
总结一下:尾插法需要两个指针,一个s和一个r,s的作用是每次用来开辟新的空间,r的作用是每次插入一个结点,都把这个结点链接到链表中来。
- 按序号查找结点值
给一个序号i,查找第i个结点的值。遍历链表
LinkList List_find(LinkList L, int pos){
LNode *p = L->next; //定义一个指针代替头指针,毕竟头指针不能乱跑
int i;
if(pos==0) //判断位置的合法性
return L;
if(pos<1)
return 0;
while(i<pos&&p!=NULL){ //没到指定位置并且没有跑出链表
p = p->next; //结点往后移
i++; //位置加一
}
return p.data; //返回找到的值
}
时间复杂度:O(N)
- 按值查找链表结点
操作和按位置查找差不多,到这代码已经轻车熟路了,应该写代码没啥问题了。
LinkList List_find(LinkList L, int v){
LNode *p = L->next;
while(p!=NULL){
if(p.data==v)
return 1;
p = p->next;
}
return 0;
}
- 插入结点操作

插入结点只需要记住一点:以上图为例:s先接上b。。。。好吧,然后再把a指向s。
因为如果先让a指向s,那么链子就断了,后面的b以及更后面的结点就变了没家的孩子,野了。
插入结点的顺序:
s->next = a->next;
a->next = s;
这个顺序切忌不能乱,我们再叨叨一遍,如果代码形式是这样的:
a->next = s;
好了,这个时候b已经成功的迷失在内存里了,有的同学会不会好奇,那我直接一手s->next = b;不就完事了,那么问题来了,b在哪谁也不知道,也许被置换丢到外存去了也不一定(瞎说的,反正就是找不到了)。
所以同学们在设计插入算法的时候,一定要:
先新结点指向已知结点,再把新结点接入链表
- 删除结点操作
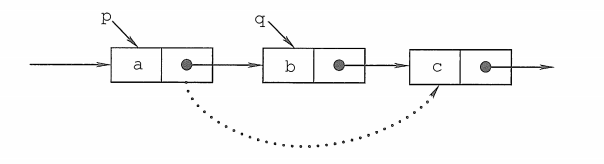
删除结点和插入结点有一个共同的思想 - 链表不能断。
还是以上图为例:我们要删除b这个结点,首先要用个指针指向b。然后先把a接到c上,再断链。不然一下又要多出很多野结点,永远迷失在内存中(当然断电也就🈚️了
删除结点的顺序:
q = p->next;
a->next = q->next;
free(q);
顺序不能乱哦,不能一上来啪的一下就把b这个结点free了,还说很快啊,这样的话,b后面的结点只能漂流瓶联系了。
有同学会不会说,为什么不直接q=b呢?我们的目的是用个指针指上去,然后想办法删了。q=b,相当于复制一个结点啊喂。
再插一句,a->b是结构体指针,相当于(*p).b
p->next = (*p).next
单链表差不多就到这了,双链表、循环链下节再说。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









