





特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示最大的敬意。如有任何侵权请联系我下架相关文章。
摘要:
在过去几年中,将深度学习应用于视频压缩的研究受到了越来越多的关注。在本文中,我们专注于端到端学习的视频压缩,特别注重更好地学习和利用时间上下文。我们提出了一种方法,不仅传播最后重建的帧,还传播重建帧之前的特征,以挖掘时间上下文。从传播的特征中,我们学习到多尺度的时间上下文,并将这些学习到的时间上下文重新填充到我们的压缩方案模块中,包括上下文编码器-解码器、帧生成器和时间上下文编码器。此外,我们舍弃了不利于并行的自回归熵模型,从而追求更高效的编码和解码时间。
实验结果表明,我们提出的方案在压缩比方面优于现有的学习型视频编解码器。我们的方案还优于 x264 和 x265(分别代表 H.264 和 H.265 的工业软件),以及 H.264、H.265 和 H.266 的官方参考软件(分别为 JM、HM 和 VTM)。具体而言,当帧内周期为 32 并以 PSNR 为目标时,我们的方案比 H.265-HM 节省了 14.4% 的比特率;当以 MS-SSIM 为目标时,我们的方案比 H.266-VTM 节省了 21.1% 的比特率。
paper: https://arxiv.org/pdf/2111.13850
code: https://github.com/microsoft/DCVC
引言:
如今,视频数据占据了大部分的互联网流量。因此,高效的视频压缩始终是降低传输和存储成本的关键需求。在过去的二十年中,已经开发了多种视频编码标准,包括 H.264/AVC、H.265/HEVC 和 H.266/VVC。
近年来,学习型视频压缩探索出了一条新方向。现有的学习型视频压缩大致可以分为四类。基于残差编码的方案:在像素域或特征域中首先进行预测,然后对预测的残差进行压缩。基于体积编码的方案:将视频视为包含多个帧的体积,通过 3D 卷积获取潜在表示。基于熵编码的方案:每帧都使用独立的图像编解码器进行编码,通过探索不同帧的潜在表示之间的相关性来指导熵建模。基于条件编码的方案:将时间上下文作为条件,编码器自动探索时间相关性以消除冗余。此外,还有一些专注于感知质量优化的学习型编解码器方案。我们认为感知质量比客观质量更为重要,学习型编解码器由于支持端到端训练和反向传播,在优化感知质量方面具有传统编解码器无法比拟的优势。然而,本文仍然聚焦于客观失真指标,以便更容易与之前的方案进行比较。
在现有的学习型视频编解码器中,Li 等人提出了一种深度上下文视频压缩(DCVC)框架,并实现了最先进的压缩比。DCVC 是基于上述条件编码结构的开放框架,利用运动补偿和多个卷积层从先前解码的帧生成单尺度的时间上下文。尽管方法简单且有效,但先前解码的帧仅包含三个通道,丢失了许多纹理和运动信息。此外,单尺度上下文可能无法包含足够的时间信息。因此,本文尝试找到一种更优的方法来学习和利用时间上下文。
基于条件编码结构,我们提出了一种时间上下文挖掘(TCM)模块,用于从传播的特征中学习更丰富且更精确的时间上下文。我们传播重建帧之前的特征,并利用 TCM 模块从这些特征中学习当前帧的时间上下文。考虑到单尺度上下文可能难以描述时空上的非均匀性,TCM 模块采用分层结构生成多尺度的时间上下文。最终,我们将这些学习到的时间上下文重新填充到压缩方案的模块中,包括上下文编码器-解码器、帧生成器和时间上下文编码器。我们将这一过程称为时间上下文重填(TCR)。
与大多数先前方案类似,本文聚焦于具有延迟约束的低延迟编码场景,尽管随机访问是最有效的编码配置。一些方案报告了高于 H.265/HEVC 的压缩比,但大多数只使用了 x265,这种方案优化了快速编码时间,而无法代表 H.265/HEVC 的最佳压缩比。本文尽可能使用 H.264/AVC、H.265/HEVC 和 H.266/VVC 的官方参考软件(JM、HM 和 VTM),以代表传统视频编解码器的最高潜力压缩比,并未采用任何降低其性能的技巧。此外,许多方案使用了自回归熵模型以提高压缩比,但这在实现并行化时面临显著挑战,同时显著增加了解码时间。我们并未在方案中应用自回归熵模型,以构建一个支持并行化的解码器,尽管我们同意自回归熵模型可以显著提升压缩比。
实验结果表明,我们的方案在编码和解码速度上显著快于其他学习型视频编解码器。据我们所知,这是第一个在峰值信噪比(PSNR)和多尺度结构相似性(MS-SSIM)指标上分别超越 HM 和 VTM 的端到端学习型视频压缩方案。
我们的贡献总结如下:
-
我们提出了一种时间上下文挖掘(TCM)模块,用于从传播的特征中学习多尺度的时间上下文,而非从先前重建的帧中学习。
-
我们提出了一种时间上下文重填(TCR)过程,将学习到的多尺度时间上下文重新填充到上下文编码器-解码器、帧生成器和时间上下文编码器中,以帮助压缩和重建当前帧。
-
在不使用自回归熵模型的情况下,我们提出的方案在压缩比方面优于现有的学习型视频编解码器。具体而言,我们的方案在 PSNR 指标上比 H.265/HEVC 的参考软件 HM 提高了 14.4% 的比特率节省,在 MS-SSIM 指标上比 H.266/VVC 的参考软件 VTM 提高了 21.1% 的比特率节省。
本文其余部分的结构如下:第二部分对相关工作进行了简要回顾;第三部分描述了我们提出的方案的具体方法;第四部分呈现了实验结果和分析;第五部分总结了本文的主要贡献并讨论了未来的研究方向。
相关工作:
传统视频压缩
传统视频压缩技术已经发展了几十年,并提出了多种视频编码标准。例如,H.264/AVC 在 1999 年到 2003 年期间由 ITU-T 和 ISO/IEC 标准组织开发,并取得了巨大成功,被广泛应用于诸多场景,如高定义电视信号广播、互联网和移动网络视频。随着视频分辨率的提高以及并行处理架构的应用,H.265/HEVC 于 2013 年推出,与 H.264/AVC 相比节省了大约 50% 的比特率。H.265/HEVC 的卓越压缩效率推动了高保真 4K 视频的普及。
H.266/VVC 是新一代国际视频编码标准,它不仅设计用于进一步降低相较 H.265/HEVC 的比特率,还能满足所有当前和新兴的媒体需求。这些视频编码标准遵循类似的混合视频编码框架,包括预测、变换、量化、熵编码和环路滤波。尽管学习型图像编解码器已经赶上甚至超越了传统图像编码方法,但在压缩比方面,传统视频压缩技术依然保持着领先地位。
学习型视频压缩
近年来,学习型视频压缩探索出了一条新方向。Lu 等人(DVC)用卷积神经网络替代了传统的运动补偿预测和残差编码框架中的各个部分,并通过率失真成本联合优化整个网络。Lin 等人探索了多参考帧,并关联多个运动矢量以生成更准确的当前帧预测,从而减少运动矢量的编码成本。Yang 等人设计了一种基于循环学习的视频压缩方案,提出了循环自编码器和循环概率模型,利用较长时间范围内的时间信息生成潜在表示并重建压缩输出。
Hu 等人从输入帧中提取特征,并应用可变形卷积进行运动预测。学习得到的偏移和残差在特征域中被压缩。随后,存储在解码缓冲区中的多个参考特征通过非局部注意模块进行融合,以获得重建帧。除了基于运动补偿预测和残差编码的框架之外,Habibian 等人(《Video Compression With Rate-Distortion Autoencoders》)将视频视为包含多个帧的体积,并提出了一种 3D 自编码器来直接压缩多个帧。Liu 等人使用图像编解码器对每帧进行压缩(《Conditional Entropy Coding for Efficient Video Compression》),并提出了一种熵模型来探索潜在表示的时间相关性。
Li 等人将编码范式从残差编码转变为条件编码(DCVC)。他们从先前解码的帧中学习时间上下文,并让编码器自动探索时间相关性以消除冗余。
传统视频编解码器与学习型视频编解码器
尽管许多现有的学习型视频编解码器报告了优于 H.265/HEVC 的压缩比,但它们可能未使用最佳的编码器,主要存在以下问题:
-
使用 x264 和 x265 来分别代表 H.264/AVC 和 H.265/HEVC 的压缩比。然而,这些工具更多地优化了编码速度,而非压缩比。因此,为了体现传统视频编码器的最高潜力压缩比,应该使用官方参考软件 JM、HM 和 VTM。例如,x265 和 HM 之间的性能差距约为 80%。
-
使用不现实的帧内周期(如 10 或 12)来限制时间误差传播。然而,在实际应用中,当使用如此短的帧内周期时,I 帧所占比特数在总比特数中占据较大比例。例如,对于 VTM,帧内周期为 12 时,I 帧占比特总量的 51%;帧内周期为 32 时,I 帧占比特总量的 29%。帧内周期为 12 对压缩比有害,并且在实际应用中很少使用。因此,本文提出使用帧内周期为 32(对于 30fps 视频大约为 1 秒),这是更合理的衡量视频编解码器间编码性能的方式。
-
在现有方案中,传统编解码器的内部色彩空间通常设定为 YUV420。然而,通过对比不同色彩空间后,我们发现 YUV444 比 YUV420 和 RGB 更优,即便最终失真是在 RGB 空间中测量的。性能差距超过了 30%。因此,我们建议在 JM、HM 和 VTM 中使用 YUV444 作为内部色彩空间,以挖掘传统编解码器更高的潜在压缩比。同样的结论也适用于学习型图像压缩。
-
为传统编解码器使用最合适的配置(如使用扩展范围配置文件编码 YUV444 内容)。不同配置之间的性能差距可能超过 40%。
综上,为了公平对比,我们采用了官方参考软件 JM、HM 和 VTM 的最佳配置,避免了任何可能降低传统视频编码器性能的技巧。
方法:
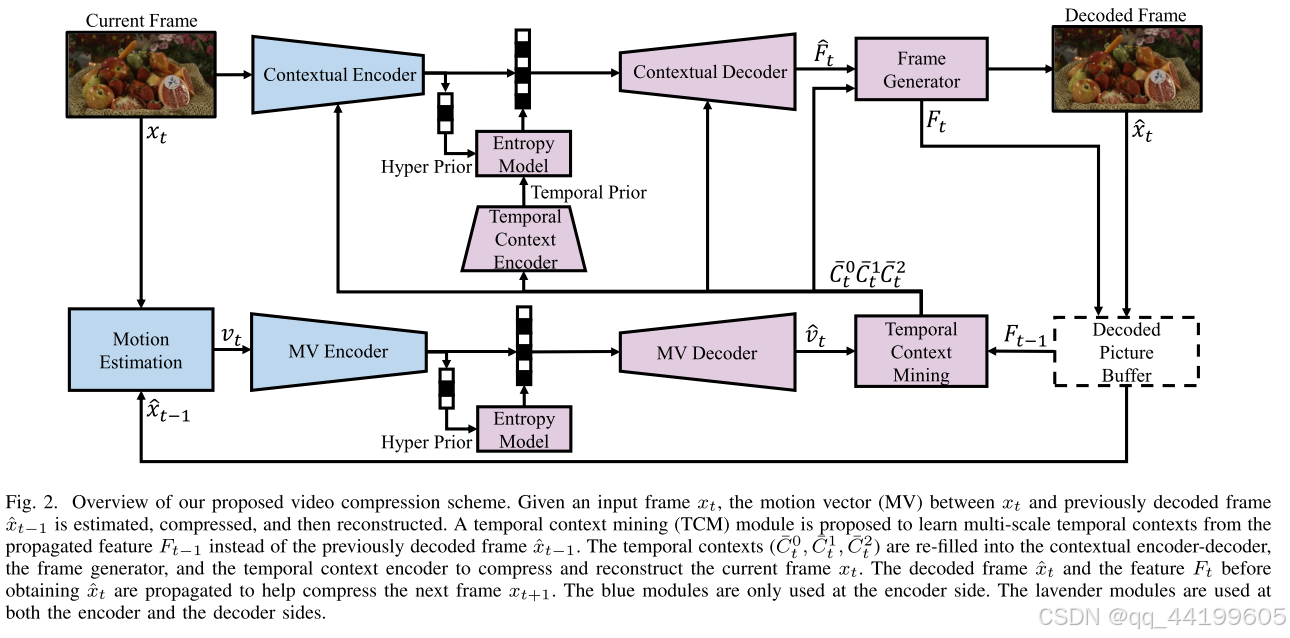
概述
为了找到更好的方式来学习和利用时间上下文,我们提出了一种基于时间上下文挖掘和重填的新型学习型视频压缩方案。图 2 展示了我们方案的整体框架。
-
运动估计:我们将当前帧 x t x_t xt 和先前解码的帧 x ^ t − 1 \hat{x}_{t-1} x^t−1 输入到一个基于神经网络的运动估计模块中,用以估计光流。光流被视为每个像素的运动矢量(MV) v t v_t vt。在本文中,运动估计模块基于预训练的 Spynet。
-
MV 编码器-解码器:在获得运动矢量 v t v_t vt 之后,我们使用 MV 编码器和解码器对输入的 v t v_t vt 进行有损压缩和重建。具体来说, v t v_t vt 通过具有超先验结构的自编码器进行压缩。重建的 MV 表示为 v ^ t \hat{v}_t v^t。
-
学习时间上下文:我们提出了一种时间上下文挖掘(TCM)模块,从传播的特征 F t − 1 F_{t-1} Ft−1 中学习更丰富且更准确的时间上下文,而不是从先前解码的帧 x ^ t − 1 \hat{x}_{t-1} x^t−1 中学习。与生成单尺度时间上下文不同,TCM 模块生成多尺度时间上下文 C ˉ t l \bar{C}_t^l Cˉtl,以捕获时空上的非均匀运动和纹理,其中 l l l 是不同尺度的索引。学习到的时间上下文被重新填充到上下文编码器-解码器、帧生成器和时间上下文编码器中,以提高压缩比。这一过程被称为时间上下文重填(TCR)。我们将在第 III-B 和 III-C 节中详细介绍这些内容。
-
上下文编码器-解码器和帧生成器:在多尺度时间上下文 C ˉ t l \bar{C}_t^l Cˉtl 的帮助下,上下文编码器-解码器和帧生成器用于压缩和重建当前帧 x t x_t xt。解码后的帧表示为 x ^ t \hat{x}_t x^t,而在获得 x ^ t \hat{x}_t x^t 之前的特征表示为 F t F_t Ft。 x ^ t \hat{x}_t x^t 和 F t F_t Ft 被传播,以帮助压缩下一帧 x t + 1 x_{t+1} xt+1。第 III-C 节将详细介绍。
-
时间上下文编码器:为了利用上下文编码器生成的不同帧的潜在表示的时间相关性,我们利用时间上下文编码器生成低维时间先验 f c f_c fc,通过利用多尺度时间上下文 C ˉ t l \bar{C}_t^l Cˉtl 进一步改进潜在表示的熵建模。更多细节将在第 III-C 节中提供。
-
熵模型:我们使用超先验的因子化熵模型和拉普拉斯分布对潜在表示进行建模。为了实现解码过程的并行化,我们没有使用自回归熵模型,尽管它可以进一步提升压缩比。对于上下文编码器-解码器,我们融合超先验和时间先验以更精确地估计拉普拉斯分布的参数。在写入比特流时,我们采用了与现有工作类似的实现方法。
时间上下文挖掘

考虑到先前解码的帧 x ^ t − 1 \hat{x}_{t-1} x^t−1 仅包含三个通道,丢失了大量信息,因此从 x ^ t − 1 \hat{x}_{t-1} x^t−1 学习时间上下文并不是最优选择。在本文中,我们提出了一种时间上下文挖掘(TCM)模块,从传播的特征 F t − 1 F_{t-1} Ft−1 中学习时间上下文。不同于现有视频压缩方案,这些方案在特征域中从先前解码的帧 x ^ t − 1 \hat{x}_{t-1} x^t−1 中提取特征,我们传播的是在获得 x ^ t − 1 \hat{x}_{t-1} x^t−1 之前的特征 F t − 1 F_{t-1} Ft−1。
具体来说,在重建 x ^ t − 1 \hat{x}_{t-1} x^t−1 的过程中,我们存储了帧生成器最后一层卷积之前的特征 F t − 1 F_{t-1} Ft−1,并将其保存在通用解码图像缓冲区(DPB)中。为了降低计算复杂度,我们不存储多个先前解码帧的特征,而是仅存储单一特征。随后, F t − 1 F_{t-1} Ft−1 被传播,用于学习当前帧 x ^ t \hat{x}_t x^t 的时间上下文。对于第一个 P 帧,我们仍然从重建的 I 帧中提取特征,以使模型适应不同的图像编解码器。
此外,单一尺度上下文可能难以很好地描述时空上的非均匀运动和纹理 。正如图 3 所示,在最大的尺度上下文中,一些通道专注于纹理信息,而另一些通道专注于颜色信息;在最小的尺度上下文中,通道主要专注于大运动区域。因此,我们采用分层方法来学习多尺度时间上下文。
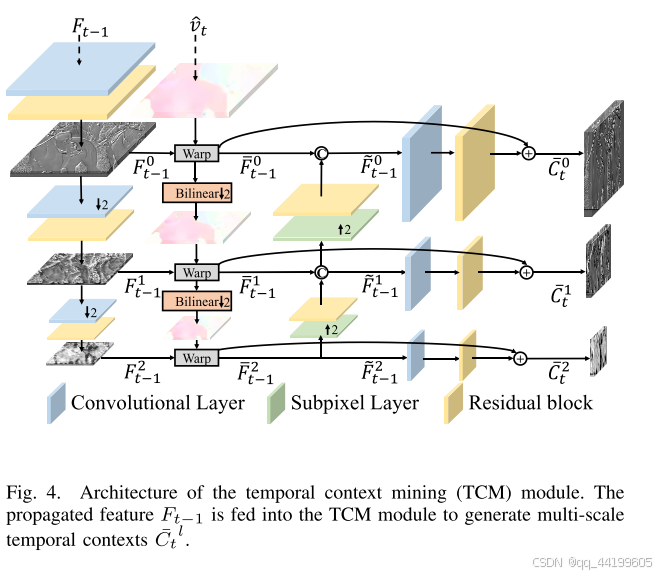
如图 4 所示,我们首先通过一个特征提取模块(extract)从传播的特征 F t − 1 F_{t-1} Ft−1 生成多尺度特征 F t − 1 l F_{t-1}^l Ft−1l,该模块由卷积层和残差块 组成。在本文中,我们使用三个层级(L = 3)。其公式如下:
F t − 1 l = extract ( F t − 1 ) , l = 0 , 1 , 2 F_{t-1}^l = \text{extract}(F_{t-1}), \quad l = 0, 1, 2 Ft−1l=extract(Ft−1),l=0,1,2
同时,通过双线性滤波对解码的运动矢量 v ^ t \hat{v}_t v^t 进行下采样,以生成多尺度运动矢量 v ^ t l \hat{v}_t^l v^tl,其中 v ^ t 0 = v ^ t \hat{v}_t^0 = \hat{v}_t v^t0=v^t。需要注意的是,每个下采样后的运动矢量值都除以 2。然后,我们利用 v ^ t l \hat{v}_t^l v^tl 在相同尺度上对多尺度特征 F t − 1 l F_{t-1}^l Ft−1l 进行变换(warp),公式如下:
F ˉ t − 1 l = warp ( F t − 1 l , v ^ t l ) , l = 0 , 1 , 2 \bar{F}_{t-1}^l = \text{warp}(F_{t-1}^l, \hat{v}_t^l), \quad l = 0, 1, 2 Fˉt−1l=warp(Ft−1l,v^tl),l=0,1,2
接着,我们通过一个上采样模块(upsample)对变换后的特征 F ˉ t − 1 l + 1 \bar{F}_{t-1}^{l+1} Fˉt−1l+1 进行上采样。上采样模块由一个子像素层 \cite{49} 和一个残差块组成。然后,我们将上采样后的特征与同尺度的 F ˉ t − 1 l \bar{F}_{t-1}^l Fˉt−1l 进行级联(concat),其公式如下:
F ~ t − 1 l = concat ( F ˉ t − 1 l , upsample ( F ˉ t − 1 l + 1 ) ) , l = 0 , 1 \tilde{F}_{t-1}^l = \text{concat}\left(\bar{F}_{t-1}^l, \text{upsample}(\bar{F}_{t-1}^{l+1})\right), \quad l = 0, 1 F~t−1l=concat(Fˉt−1l,upsample(Fˉt−1l+1)),l=0,1
在分层结构的每一级,我们使用一个上下文细化模块(refine)来学习残差。该模块由一个卷积层和一个残差块组成 \cite{50}。我们将学习到的残差添加到 F ˉ t − 1 l \bar{F}_{t-1}^l Fˉt−1l 上,从而生成最终的时间上下文 C ˉ t l \bar{C}_t^l Cˉtl,公式如下:
C ˉ t l = F ˉ t − 1 l + refine ( F ~ t − 1 l ) , l = 0 , 1 , 2 \bar{C}_t^l = \bar{F}_{t-1}^l + \text{refine}(\tilde{F}_{t-1}^l), \quad l = 0, 1, 2 Cˉtl=Fˉt−1l+refine(F~t−1l),l=0,1,2
如图 4 所示,TCM 模块的架构清楚地展示了如何从传播的特征 F t − 1 F_{t-1} Ft−1 中生成多尺度时间上下文 C ˉ t l \bar{C}_t^l Cˉtl。
时间上下文重填
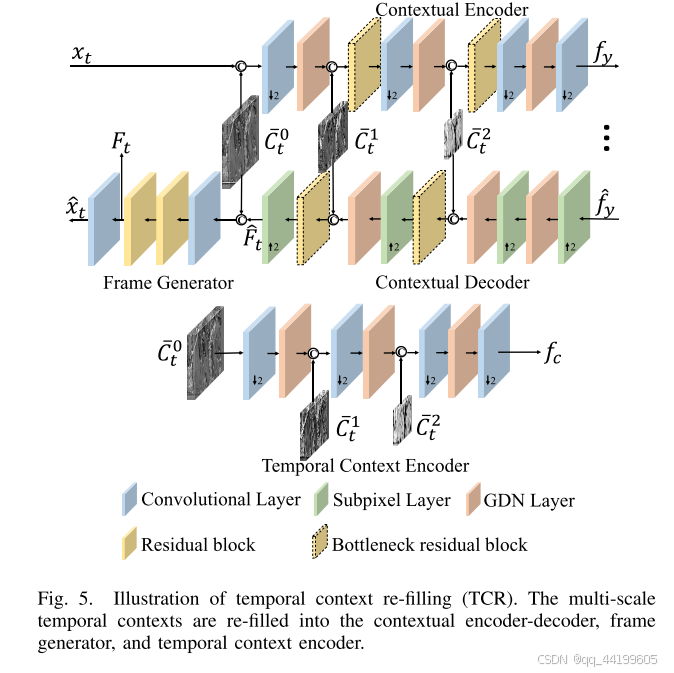
为了充分利用时间相关性,我们将学习到的多尺度时间上下文重新填充到压缩方案的模块中,包括上下文编码器-解码器、帧生成器以及时间上下文编码器,如图 5 所示。时间上下文在时间预测和时间熵建模中起着重要作用。通过重新填充多尺度时间上下文,我们方案的压缩比得到了显著提升。
- 上下文编码器-解码器和帧生成器:
我们将最大的尺度时间上下文 C ˉ t 0 \bar{C}_t^0 Cˉt0 与当前帧 x t x_t xt 级联,然后将其输入到上下文编码器中。在从 x t x_t xt 映射到潜在表示 f y f_y fy 的过程中,我们还将 C ˉ t 1 \bar{C}_t^1 Cˉt1 和 C ˉ t 2 \bar{C}_t^2 Cˉt2 与其他尺度的特征一起级联到编码器中。在解码器的对称操作中,使用上下文解码器将量化的潜在表示 f ^ y \hat{f}_y f^y 映射到特征 F ^ t \hat{F}_t F^t,并利用 C ˉ t 1 \bar{C}_t^1 Cˉt1 和 C ˉ t 2 \bar{C}_t^2 Cˉt2 辅助解码。随后, F ^ t \hat{F}_t F^t 和 C ˉ t 0 \bar{C}_t^0 Cˉt0 被级联,并输入到帧生成器中以获得重建的帧 x ^ t \hat{x}_t x^t。由于级联操作增加了通道数量,我们在中间层使用了“瓶颈”残差块,以降低复杂度。详细的架构如图 6 所示。在帧生成器的最后一层卷积之前,特征 F t F_t Ft 会被存储,以帮助压缩下一帧 x t + 1 x_{t+1} xt+1。
- 时间上下文编码器:
为了探索上下文编码器生成的不同帧的潜在表示之间的时间相关性,我们利用时间上下文编码器生成低维的时间先验 f c f_c fc。不同于只使用单一尺度时间上下文 的方法,我们在生成时间先验的过程中将多尺度时间上下文级联在一起。时间先验与超先验相结合,用于估计拉普拉斯分布的均值和方差,从而对潜在表示 f ^ y \hat{f}_y f^y 进行建模。时间上下文编码器的架构如图 5 所示。
损失函数
我们的方案目标是联合优化率失真(R-D)成本。当前时间步 t t t 的损失函数定义如下:
L t = λ D t + R t = λ d ( x t , x ^ t ) + R v ^ t + R f ^ t , L_t = \lambda D_t + R_t = \lambda d(x_t, \hat{x}_t) + R_{\hat{v}_t} + R_{\hat{f}_t}, Lt=λDt+Rt=λd(xt,x^t)+Rv^t+Rf^t,
其中, d ( x t , x ^ t ) d(x_t, \hat{x}_t) d(xt,x^t) 表示输入帧 x t x_t xt 和重建帧 x ^ t \hat{x}_t x^t 之间的失真。 d ( ⋅ ) d(\cdot) d(⋅) 可以表示为均方误差(MSE)或 1 − MS-SSIM 1 - \text{MS-SSIM} 1−MS-SSIM 。 R v ^ t R_{\hat{v}_t} Rv^t 表示对量化运动矢量潜在表示及其超先验进行编码所需的比特率。 R f ^ t R_{\hat{f}_t} Rf^t 表示对量化上下文潜在表示及其超先验进行编码所需的比特率。
我们采用逐步训练模型的方法,以提高训练的稳定性,类似于之前的方案。需要特别指出的是,在最后五个训练周期中,我们采用了一种在最近的工作中常用的训练策略,即在连续的训练帧上训练模型,以缓解误差传播。
完整的训练损失函数定义如下:
L T = 1 T ∑ t L t = 1 T ∑ t { λ d ( x t , x ^ t ) + R v ^ t + R f ^ t } , L_T = \frac{1}{T} \sum_{t} L_t = \frac{1}{T} \sum_{t} \left\{ \lambda d(x_t, \hat{x}_t) + R_{\hat{v}_t} + R_{\hat{f}_t} \right\}, LT=T1t∑Lt=T1t∑{λd(xt,x^t)+Rv^t+Rf^t},
其中 T T T 是时间间隔,在我们的实验中设置为 4。
实验:
实验设置

- 数据集:
许多学习型视频压缩研究中使用了不同的训练数据集。在本文中,我们使用常用的 Vimeo-90k 训练集,并随机裁剪视频为 256 × 256 256 \times 256 256×256 的小块。为了评估我们提出的视频压缩方案的性能和应用场景,我们使用了 UVG、MCL-JCV 和 HEVC 数据集。这些数据集包含了各种视频内容,包括慢速/快速运动以及低/高质量的视频,这些内容在学习型视频压缩领域中非常常见。
UVG 数据集包含 7 个 1080p 视频序列,MCL-JCV 数据集包含 30 个 1080p 视频序列。考虑到 MCL-JCV 数据集中动画序列(18, 20, 24, 25)与训练数据集中的自然视频有较大差异(如图 7 所示),我们按照现有设置,构建了一个名为 MCL-JCV-26 的数据集,该数据集排除了上述 4 个动画序列。HEVC 数据集包含 16 个序列,包括 Class B、Class C、Class D 和 Class E。由于这些数据集的原始视频以 YUV420 格式存储,而 PSNR 是在 RGB 颜色空间中计算的,我们额外构建了一个名为 HEVC Class RGB 的分类,其中包括 6 个 1080p 视频,这些视频具有 10 位深度并以 RGB444 格式存储,如图 8 所示。
- 实现细节:
我们训练了四种不同 λ \lambda λ 值的模型( λ = 256 , 512 , 1024 , 2048 \lambda = 256, 512, 1024, 2048 λ=256,512,1024,2048),以支持多种编码速率。训练过程中使用 AdamW 优化器,批量大小设置为 4。当使用 MS-SSIM 进行性能评估时,我们通过使用 1 − MS-SSIM 1 - \text{MS-SSIM} 1−MS-SSIM 作为失真损失,对模型进行了微调,分别针对不同的 λ \lambda λ 值( λ = 8 , 16 , 32 , 64 \lambda = 8, 16, 32, 64 λ=8,16,32,64)。我们的模型基于 PyTorch 框架实现,并在 2 个 NVIDIA V100 GPU 上训练,模型训练耗时约为 2.5 天。
- 评价指标:
我们使用比特每像素(bpp)来衡量每帧中每个像素所需的比特数。同时,使用 PSNR 和 MS-SSIM 来评估解码帧与原始帧之间的失真。
实验结果
- 对比设置:
尽管随机访问模式是最有效的编码模式,但本文聚焦于低延迟编码模式,与大多数现有方案保持一致。因此,我们将 x264、x265、JM-19.0、HM-16.20 和 VTM-13.2 设置为低延迟模式。对于 x264 和 x265,我们使用 FFmpeg 中的 veryslow 预设配置。其内部颜色空间设置为 YUV420,与之前的方案一致。对于 JM、HM 和 VTM,我们使用扩展范围配置文件,而非主配置文件,以启用针对非 YUV420 数据设计的编码工具。具体来说,我们分别使用 encoder JM LB HE、encoder lowdelay main rext 和 encoder lowdelay vtm 配置文件。内部颜色空间设置为 YUV444。同时,它们默认使用 4 个参考帧以追求最高的压缩比。正如在前文分析中所述,I 帧的比特数在总比特数中占据了较大比例。因此,对于学习型视频编解码器(DVC Pro、MLVC、RLVC、DCVC),我们使用与我们方案相同的图像编解码器来压缩 I 帧,以确保公平的比较。我们采用 CompressAI 实现的 Cheng2020Anchor,但移除了其自回归熵模型。DVC Pro 模型由我们自行训练,其他模型使用作者公开的版本。之前的方案中,帧内周期通常设置为 10 或 12,以限制时间误差传播。然而,如前文所述,较短的帧内周期在实际应用中较少使用,因此我们建议使用更合理的帧内周期 32。此外,我们还测试了帧内周期为 12 的情况。由于 VTM 的 GOP 大小为 8,其默认配置不支持帧内周期 12,因此我们添加了一个修改后的 VTM* 配置,该配置使用低延迟 P 模式、8 位内部深度和单一参考帧设置。我们对所有测试数据集中的视频进行了 96 帧编码。
- 实验结果:
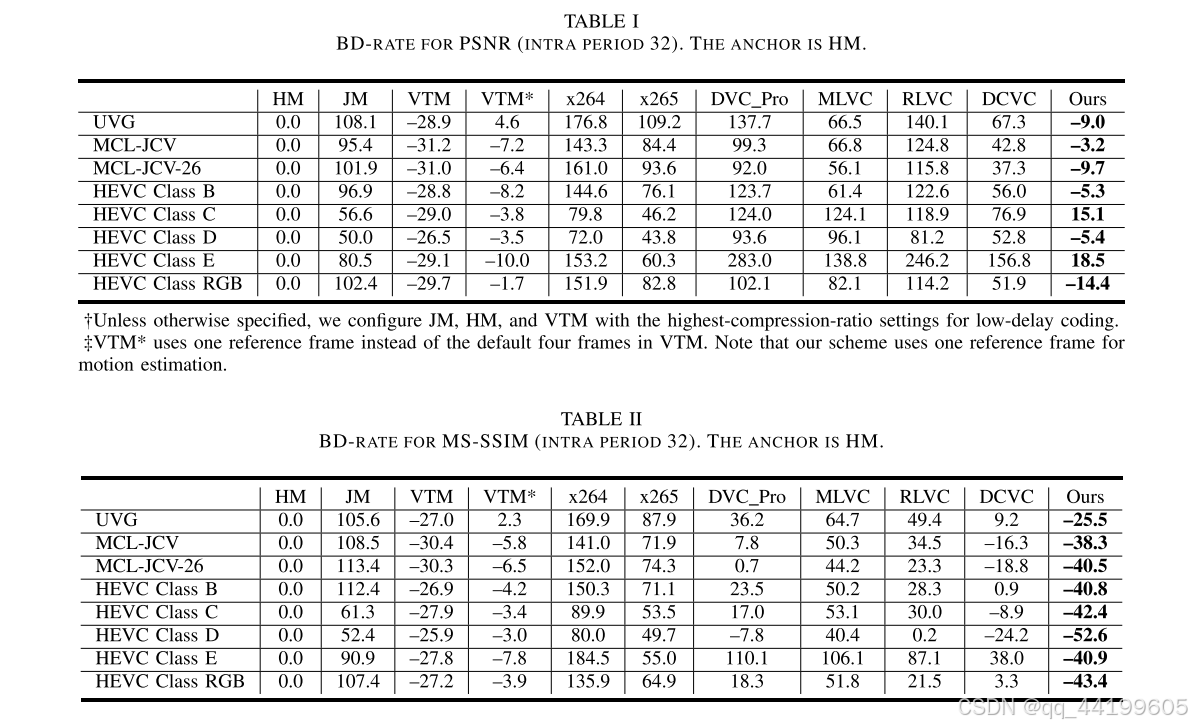
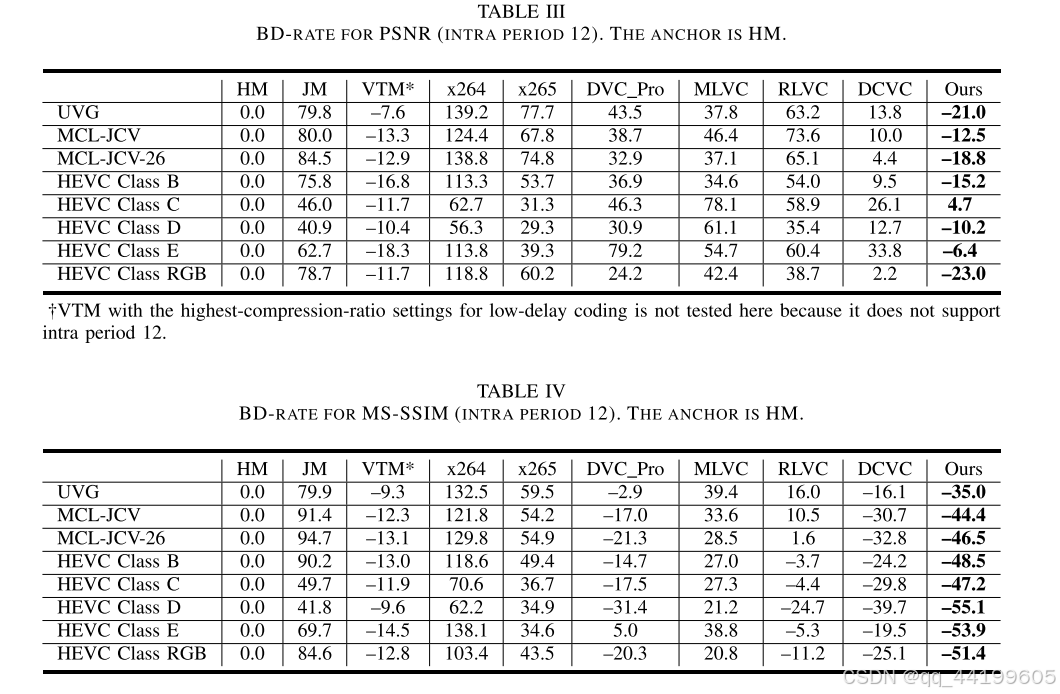
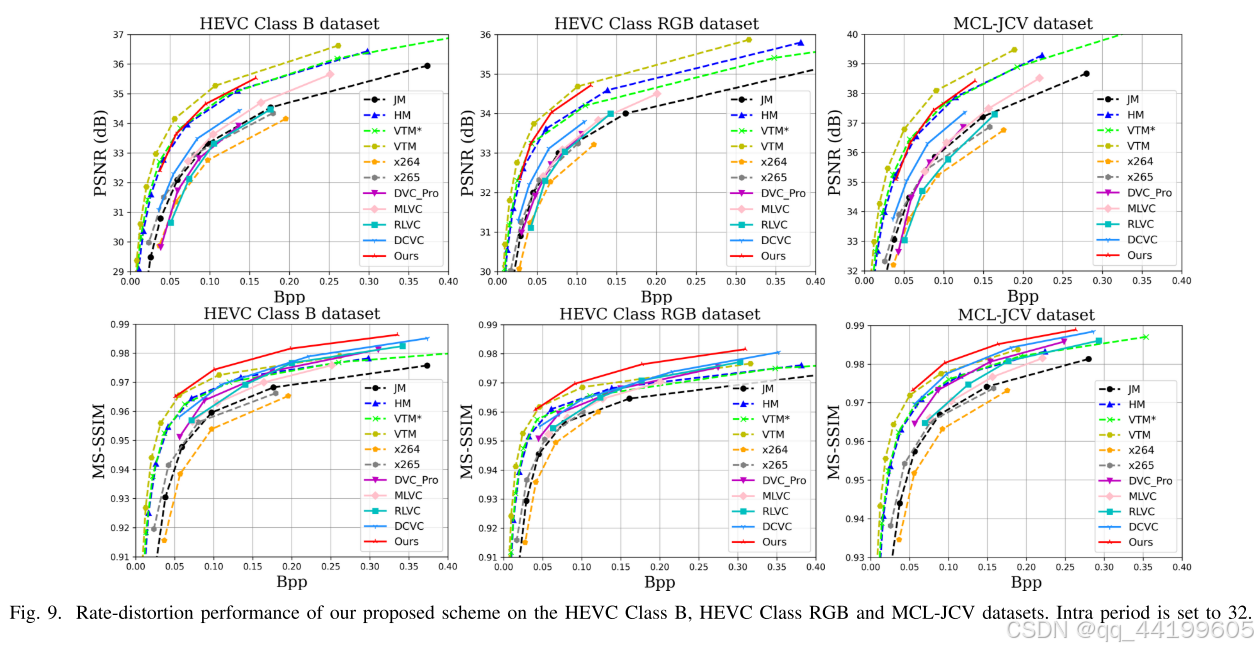
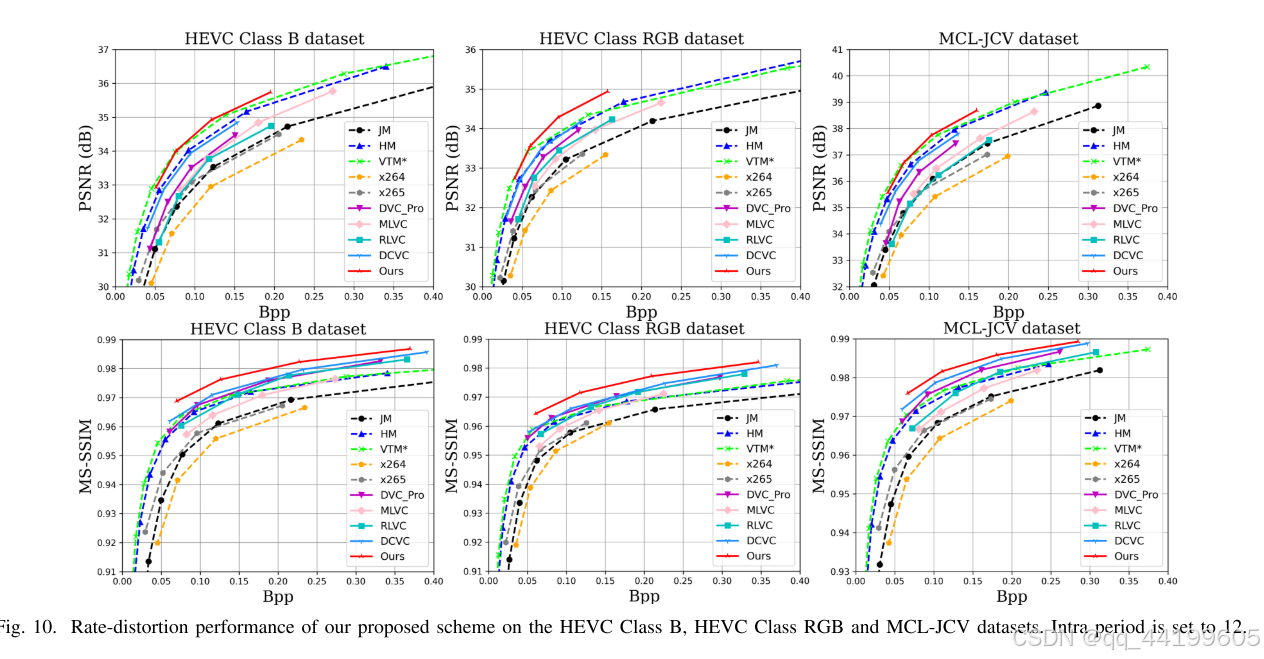
表 I 和表 II 报告了帧内周期为 32 时的 BD-rate 结果。表 III 和表 IV 报告了帧内周期为 12 时的 BD-rate 结果。锚点为 HM。负值表示比 HM 节省了比特率,正值表示比 HM 增加了比特率。实验结果显示,对于帧内周期为 32 的情况,我们的方案在 HEVC Class RGB 数据集上比 HM 在 PSNR 指标上提高了 14.4%,比 VTM* 提高了 14.2%。尽管在 PSNR 性能上仍与 VTM 的最佳配置存在 25.4% 的差距,但我们的方案在 MS-SSIM 指标上超过了 VTM 21.1%。对于帧内周期为 12 的情况,我们的方案在压缩比方面取得了更大的提升。需要注意的是,当与 VTM 或 VTM* 比较时,VTM 或 VTM* 被视为锚点,BD-rate 值是重新计算的,而不是直接从前述表格中减去值。与帧内周期为 32 和 12 的结果相比,当帧内周期增加时,我们的方案依然保持较高的压缩比,而其他学习型视频编解码器的性能却显著下降。图 9 和图 10 展示了不同帧内周期下 HEVC Class B、HEVC Class RGB 和 MCL-JCV 数据集的率失真曲线。我们发现,学习型视频编解码器在源视频为 RGB 格式时表现更好。主观对比结果如图 11 所示,我们的方案可以保留更多细节。

- 模型复杂度和编码/解码时间:
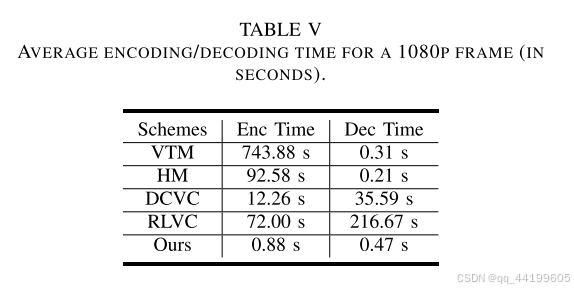
我们的方案的总参数数量为 10.7M。在处理一帧 1080p 视频时,我们方案的 MACs(乘加运算次数)为 2.9T,而 DCVC 的 MACs 为 2.4T。图 1 展示了不同编解码器处理单帧 1080p 视频的平均编码和解码时间,表 V 列出了详细数值。与现有的一些方案不同,这些方案未计算熵编码的时间或 CPU 和 GPU 之间数据传输的时间,我们方案的时间统计包含了模型推理、熵建模、熵解码以及 CPU 和 GPU 之间的数据传输时间。我们的编码时间定义为从读取原始帧到将比特流写入硬盘的全部时间,解码时间定义为从读取比特流到生成最终重建帧的全部时间。由于传统视频编解码器经过优化以运行在 CPU 上,我们在 Intel® Xeon® Platinum 8272CL CPU 上运行传统视频编解码器,与之前的方案保持一致。对于学习型视频编解码器,我们在 NVIDIA V100 GPU 上运行。我们仅与那些官方发布的代码支持比特流写入的学习型视频编解码器进行比较。实验结果显示,我们方案平均编码一帧 1080p 视频需要 0.88 秒,解码需要 0.47 秒。尽管我们方案的 MACs 相比 DCVC 增加了约 21%,但由于移除了不支持并行化的自回归熵模型(尽管这种模型可以提升压缩性能),解码时间减少了约 98.7%。与 HM 和 VTM 相比,尽管我们方案的编码时间更短且解码时间相似,这主要归因于我们的方案运行在非常先进且昂贵的 GPU 上,而 HM 和 VTM 则运行在通用 CPU 上。因此,我们方案的复杂性,特别是解码复杂性,需要进一步降低以便在实际中应用。
消融研究
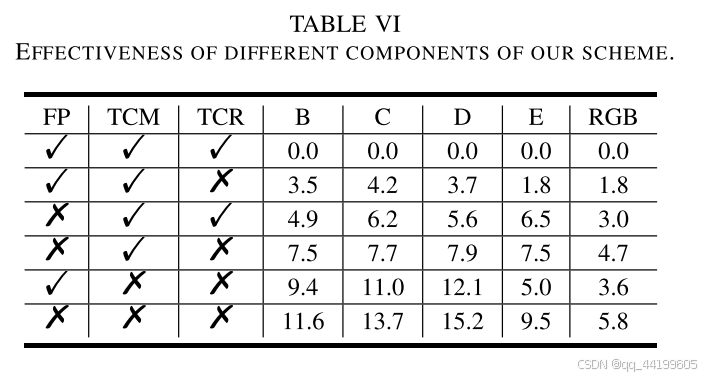
1) 不同组件的有效性:
在我们的工作中,我们专注于更好地学习和利用时间上下文。我们提出从传播的特征中学习时间上下文,并将学习到的时间上下文重新填充到压缩方案的各个模块中。为了验证这些思想的有效性,我们进行了消融研究,其结果如表 VI 所示。基准方案是我们的最终解决方案(即特征传播(FP)+ 时间上下文挖掘(TCM)+ 时间上下文重填(TCR))。
从表 VI 中可以看出,无论是从重建帧还是传播特征中学习并重新填充时间上下文,都能够提升压缩比。这验证了我们提出的 TCM 和 TCR 可以更好地学习和利用时间上下文。此外,从表 VI 中还可以发现,从传播特征中学习时间上下文的提升幅度大于从重建帧中学习的提升幅度。这表明,与重建帧相比,传播的特征可能包含更多的时间信息。
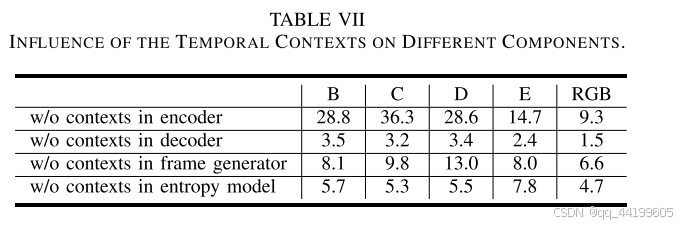
2) 时间上下文对不同组件的影响:
在时间上下文重填过程中,我们将时间上下文输入到上下文编码器-解码器、帧生成器以及时间上下文编码器中,以提升压缩性能。为了探索时间上下文对不同组件的影响,我们进行了消融研究,具体移除了编码器、解码器、帧生成器和熵模型中的时间上下文,分别评估其对性能的影响。
表 VII 展示了四种变体的 BD-rate 结果,基准方案为我们的最终解决方案。可以看出,重新填充的时间上下文在时间预测、帧重建以及时间熵建模中都起到了重要作用。
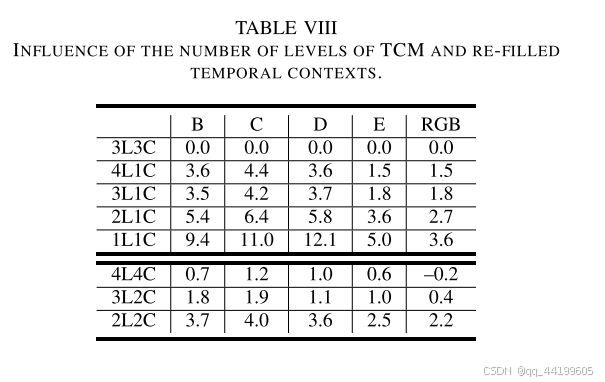
3) TCM 模块的层数和重填时间上下文数量的影响:
为了研究 TCM 模块层数的影响,我们调整了 TCM 模块分层结构的层数,但仅输出单一尺度的时间上下文 C ˉ t 0 \bar{C}_t^0 Cˉt0,例如,在 TCR 过程中仅使用 C ˉ t 0 \bar{C}_t^0 Cˉt0。nL1C 指的是 TCM 的层数,但仅输出单一尺度的上下文。基准方案是我们的最终解决方案。如表 VIII 所示,随着 TCM 模块层数的增加,码率节省逐渐提高,但当层数达到 3 时开始趋于饱和。
为了研究重填时间上下文数量的影响,我们调整了 TCM 的输出上下文数量。如表 VIII 所示,随着重填时间上下文数量的增加,码率节省有所提高。然而,当重填时间上下文的数量超过 3 时,性能提升变得不明显。在本文中,我们采用了 3 个时间上下文。
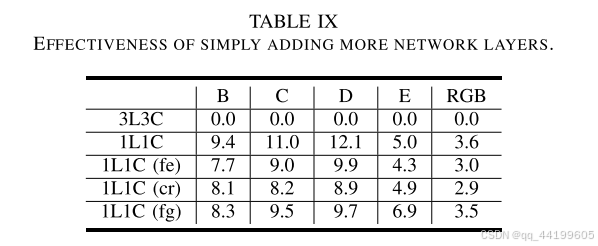
为了证明压缩比的提升并非仅仅是由于网络层数的增加,我们在 1L1C 模型中为特征提取模块(fe,公式 (1) 中定义)、上下文细化模块(cr,公式 (4) 中定义)以及帧生成器模块(fg,图 2 中定义)添加了更多的残差块,以使这些模型的 MACs 与我们的最终方案相当。我们将这些修改后的模型分别记为 1L1C(fe)、1L1C(cr) 和 1L1C(fg)。如表 IX 所示,仅仅增加网络层数并不能显著提高压缩比。
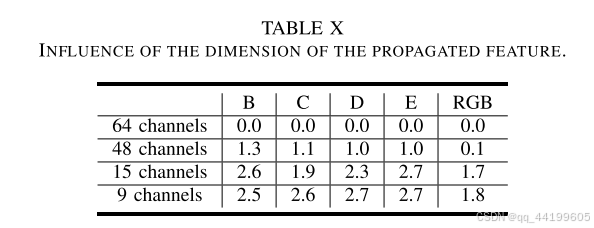
4) 传播特征维度的影响:
为了公平比较,我们选择特征维度为 64,以确保通用解码图像缓冲区(DPB)的大小与 RLVC 相同。为了探索传播特征维度的影响,我们还将特征维度更改为 48(与 FVC 相同的 DPB 大小)、15(与 MLVC 相同的 DPB 大小)以及 9(与 4 参考帧编码器相同的 DPB 大小)。如表 X 所示,较低的特征维度仅会带来轻微的性能损失。用户可以根据硬件能力自适应地调整特征维度。
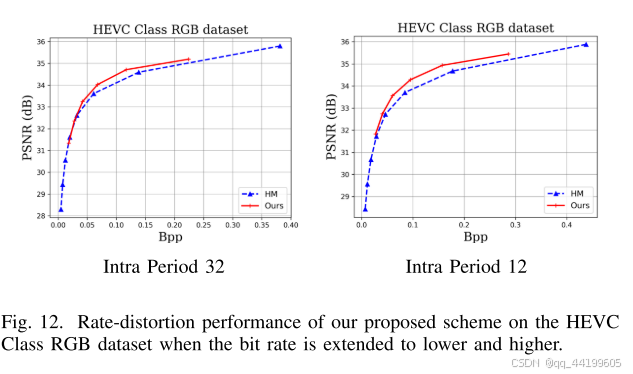
5) 更宽的码率范围:
在之前的学习型视频编解码器中,通常会训练四个不同码率的模型。这种做法在相关领域已十分常见。为了方便与现有学习型视频编解码器进行对比,我们的方案采用了相同的设置。然而,探索学习型视频编解码器在带宽受限(低码率)和带宽充足(高码率)环境中的性能表现仍然是必要的。
因此,当目标为 PSNR 时,我们将 λ \lambda λ 设置为 128 和 4096,训练额外的两个模型;当目标为 MS-SSIM 时,我们将 λ \lambda λ 设置为 4 和 128。对于其他学习型视频编解码器(如 DVC Pro、MLVC、RLVC 和 DCVC),由于其官方发布的模型仅支持四个码率点,我们无法扩展其码率范围。
图 12 展示了在 HEVC Class RGB 数据集上,当码率扩展到更低和更高范围时,我们提出方案的率失真性能。结果表明,我们的方案在更宽的码率范围内依然表现良好。
结论:
在本文中,我们提出了一种端到端学习型视频压缩方案,专注于更好地学习和利用时间上下文。具体来说,我们提出了一种时间上下文挖掘(TCM)模块,用于从传播的特征中学习更丰富的时间上下文,并设计了一种时间上下文重填(TCR)机制,将学习到的时间上下文重新填充到压缩方案的各个模块中。为了实现解码过程的高效并行化,我们在方案中未使用自回归熵模型。实验结果表明,我们提出的方案在压缩比方面优于现有的学习型视频编解码器,并在多种数据集上与传统视频编码器(包括 H.264、H.265 和 H.266)进行了全面比较。我们的方案在峰值信噪比(PSNR)和多尺度结构相似性(MS-SSIM)指标上表现出色,展示了在更广泛应用场景中的潜力。
未来的工作可能包括以下几个方面:进一步优化时间上下文挖掘和重填模块以提升性能,在支持并行化的前提下探索更高效的熵模型,以及在低延迟和随机访问场景下实现更全面的性能提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









