






 本文探讨了CrossEntropyLoss与BCELoss在多类和二元分类任务中的区别,包括用途、实施细节和实际应用。CrossEntropyLoss适用于多类,BCELoss专为二元分类设计,强调了sigmoid与softmax在输出概率上的角色。Pytorch中推荐BCEWithLogitsLoss和CrossEntropyLoss的使用场景。
本文探讨了CrossEntropyLoss与BCELoss在多类和二元分类任务中的区别,包括用途、实施细节和实际应用。CrossEntropyLoss适用于多类,BCELoss专为二元分类设计,强调了sigmoid与softmax在输出概率上的角色。Pytorch中推荐BCEWithLogitsLoss和CrossEntropyLoss的使用场景。
CrossEntropyLoss vs BCELoss
CrossEntropyLoss vs BCELoss
1. 用途差异
- CrossEntropyLoss主要用于多类分类,二元分类是可行的
- BCE 代表 二进制交叉熵,用于二元分类
- 那么,为了简单起见,我们为什么不对所有情况都使用CrossEntropyLoss呢?答案在 (3)
2. 细节实施的差异
- 当 CrossEntropyLoss 用于二元分类时,它需要 2 个输出要素。例如。logits=[-2.34, 3.45], Argmax(logits) →class 1
- 当 BCEloss 用于二元分类时,它需要 1 个输出特征。例如 1.logits=[-2.34]<0 →class 0;例如 2.logits=[3.45] >0→类 1
3. 目的差异(在实践中)
-
一个主要的区别是,如果要生成输出作为概率的一种形式,则应使用BCE。
-
这是因为我们可以使用 sigmoid 来处理单个输出,同时使用 BCELoss 作为损失函数。例如 1.σ(-2.34)=p₁=8.79%(输出为1类的概率为8.79%,p₀=1–8.79%=91.21%,因此很可能是0类);例如 2.σ(3.45)=p₁=96.9%(可能是1级)
-
我们不能将sigmoid用于2个输出特征,而使用CrossEntropyLoss作为损失函数。σ([-2.34, 3.45])=[8.79%, 96.9%]没有意义。这并不意味着 p₀=8.79%(如果是这样,p₁=1–8.79%=91.21%)。它也不意味着 p₁=96.9%。
-
对于CrossEntropyLoss,softmax是获取概率输出的更合适的方法。但是,对于只有 2 个值的二元分类,softmax 的输出将始终基于其公式类似于 [0.1%,99.9%] 或 [99.9%,0.1%]。例如。softmax([-2,34, 3,45])=[0.3%, 99.7%]。它不代表有意义的概率。
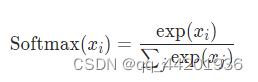
-
所以 softmax 只适合多类分类。
以上导致 — Sigmoid vs softmax
- 输出处的 Sigmoid 更适合二元分类。(可能也适用于多标签分类)。
- 输出端Softmax更适合多类分类
对于 BCE,请使用 BCEWithLogitsLoss();对于 CE,请使用 CrossEntropyLoss()
- 使用BCEWithLogitsLoss()而不是BCELoss(),因为前者已经包含一个sigmoid层。因此,您可以直接在损失函数中传递对数。技术原因:
这个版本在数值上比使用普通的Sigmoid后跟BCELoss更稳定,因为通过将运算组合成一层,我们利用对数-和-exp技巧来获得数值稳定性。(参考)
- CrossEntropyLoss() 已经包含了一个 softmax 层。
Pytorch 中的损失计算
- 对于 pytorch 中的损失计算(BCEWithLogitsLoss() 或 CrossEntropyLoss()),损失输出 loss.item() 是加载批次中每个样本的平均损失
- 因此,每批的总损失=损失*batch_size=loss.item()*x.size(0),整个数据集的平均损失将为total_loss/total_size
- 当在同一地块中绘制train_loss和val_loss时,这将非常有用。您可能希望以有意义的比例比较训练集和 val 集的损失,因为训练集和 val 集的数据大小通常不同。平均损失将是最合适的。
train_loss = 0
criterion = nn.BCEWithLogitsLoss()
for step, (x, y) in enumerate(train_loader):
model.train()
logits = model(x)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()*x.size(0)
ave_loss = train_loss/len(train_loader.dataset)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









