







用堆实现优先队列
场景
将一些作业发送到打印机中,此时的作业将会放在一个队列中,但是这看起来并不是一个最优的做法,因为有些作业特别的重要,你此时会让打印机来优先处理做个要紧的作业,。同样在一个多用户环境中,操作系统调度程序必须决定在若干个进程中优先运行哪一个时间紧迫的进程。因为一般情况下一个时间片只能处理一个进程。假如一个长进程需要占用很多时间来处理,那么后面的短进程就不得不需要等待长进程,这样就大大降低了计算机的运行效率。读到这,读者也许就会发现,这种先来先服务的策略明显不符合现代操作系统的需求。一般来说,我们更加希望把短的作业尽快处理掉,也就是说短作业的优先权更高。因此这就诞生了一个比较先进的模型:优先队列,下面我们将仔细讨论一下优先队列的数据结构。
- 优先队列至少有两种操作,插入和删除;
- 使用简单链表在表头以O(1)的方式执行插入的操作,并且遍历该链表删除最小的元素,这需要O(N)的时间复杂度,或则让链表表始终保持排序的状态,这使得插入的带教高昂O(N)而且删除的代价低廉O(1),因此结合具体需求来使用这两种方式;
- 使用二叉查找树的方式实现优先队列,这两种操作的方式平均运行时间是O(logN)。尽管插入是随机的,但是擦除却不是,那么上面的这一个结论是否还是成立呢?显然这个结论还是成立的。因为我们删除的唯一元素是最小元。反复擦除左子树中的结点似乎会损害树的平衡,使得右子树将会加重。但是右子树是随机的。在最坏的情况下,将deleteMin左子树删空,右边子树所拥有最多也是它具有的两倍。这还是在期望的深度上加了一个小常数。这里值得注意的是,通过一颗平衡二叉树,可以把这个边界变成最坏的情况的边界,这将防止出现最坏的插入序列。使用二叉查找树来实现优先队列的话可能会觉得大材小用,因为它有很多的操作用不上二叉查找树的功能,因此我们用一个比较容易理解的一个数据结构:数组来实现而不需要一个链表。它可以在最坏的情况下在以时间夫复杂度为O(logN)支持上面的插入和删除的操作,另外通过这个数据结构,我们发现插入操作其实只需要一个常数的平均时间,如果没有删除的干扰,该结构就相当于一个以线性时间建立的一个具有N顶的优先队列。最后也可以实现优先队列的合并,但是这操作需要用到链表的结构。
public class PriorityQueue { //这里使用基本方式中的第一种
static class Node{
int priority; //优先级,数值越大优先级就越高
int value;
Node next;
public Node(int value, int priority) {
this.value = value;
this.priority = priority;
}
}
Node head = null;
//head表头永远指向最小(即优先级是最高的元素)
public void insert(int value, int priority) {
if (head == null) {
head = new Node(value,priority);
return ;
}
Node cur = head;
Node newNode = new Node(value,priority);
if (head.priority < priority) { //将要插入的结点作为头结点
newNode.next = head;
this.head = newNode;
} else {
while (cur.next != null && cur.next.priority > priority) {
cur = cur.next;
}
newNode.next = cur.next;
cur.next = newNode;
}
}
public Node peek() {
return head;
}
public Node deleteNodeMin() {
if (head == null) {
return null;
}
Node temp = head;
head = head.next;
return temp;
}
public boolean isEmpty() {
return head == null;
}
public static void show(Node node) {
Node cur = node;
while (cur != null) {
System.out.print(cur.value+",");
cur = cur.next;
}
System.out.println();
}
public static void main(String[] args) {
PriorityQueue pQ = new PriorityQueue();
pQ.insert(5,1);
pQ.insert(4,2);
pQ.insert(3,3);
pQ.insert(1,5);
pQ.insert(2,4);
System.out.println(pQ.peek().value);
show(pQ.head);
}
}
上面的只是用链表的方式来实现优先队列,但是之并不是我们想要的
因此接下来我们将通过建立堆的方式(下面事建立小根堆来实现优先队列)
堆的性质
1.堆在物理上是保存在数组中;
(1)结构性:
堆是一个被完全填满的二叉树,另外一个高为h的完全二叉树有到2^ h,这里不再证明 2 ^ h ~2^(h+1)-1,这里不再证明。这意味着完全二叉树的高是向⌊logN⌋,显然它的时间复杂度是O(logN),如果读者能够仔细的发现,一个完全二叉树是很有规律的(将数组小标为0的位置空出来,这里以后可以做点手脚)。它的结点位置可以和数组的下标一一对应起来比如一个结点的索引是i,那么它的左孩子的索引就是2i,右孩子就是2i+1,而它的父节点是⌊i/2⌋,因此这里显然用一个数组来表示,对于计算机;来将是比较友好的方式,但是也有缺点,比如最大的堆的大小需要一个预判(这个可以解决,可以调整堆)
(2)堆序性:
满足任意结点的值都大于其子树中结点的值,叫做大堆,或者大根堆,或者最大堆。
让操作快的性质是堆性质,如果我们想要找出一个最小元(小根堆),它的最小元应该在根结点上,如果我们考虑任意一个子树也应该是一个堆,那么任意的结点应该小于它的所有的后裔。
下面是一个数组结构的二叉堆:
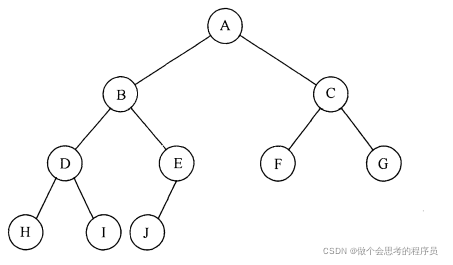

(3)下面我们将讲一下具体的代码功能
要想将一个元素X插入到一个堆中,我们首先可以在一个可用的插入的位置建立一个空穴(并不是想插入哪里就插入哪里,这样会破会堆的特性),如果将插入的元素放在一个空位置上,并且没有破坏堆的两个特性,那么就说明插入完成。否则我们降压调整堆的结构,直到调整到满足堆的特性为止,步骤如图:
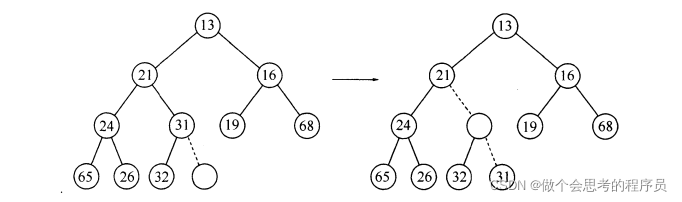
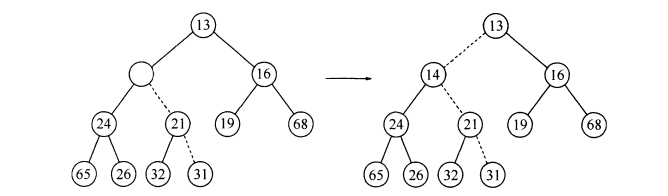
代码实现:
public void insert(AnyType x) {
if (this.currentSize == array.length-1) { //扩容
enlargeArray(array.length*2+1);
}
//上滤操作,新的元素在上滤过程中找到正确的位置
int hole = ++currentSize;
percolateUp(hole);
}
//上滤
private void percolateUp(int hole) {
AnyType temp = array[hole];
for ( ; temp.compareTo(array[hole/2]) < 0; hole /= 2) {
array[hole] = array[hole/2];
array[hole] = temp;
}
}
删除最小元:
删除同样也不能任意删除,要满足删除后的结构仍然符合堆的特性,首先你要找到一个最小元,当然了,这是一个小根堆,最小元就是在根结点,困难之处在于如何删除它,当你要删除一个最小元,你就要在一个根结点建立一个空穴。由于根的位置没有了元素,那么你就要想办法将其与结点来代替移动到这个位置上。删除时先将空位置上的两个儿子比较,哪个儿子的值最小就将它上滤到空位置的地方,这样就把空位置往下移动了一层,重复的比较,直到可以将X放入到沿着从根开始包含最小儿子的一条路径上的一个正确位置,下面如图:
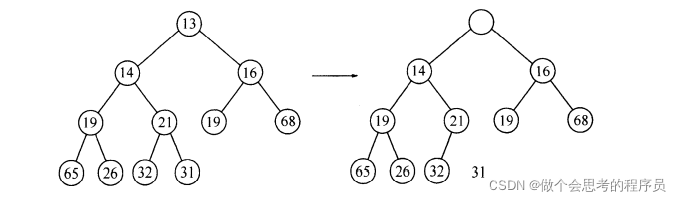
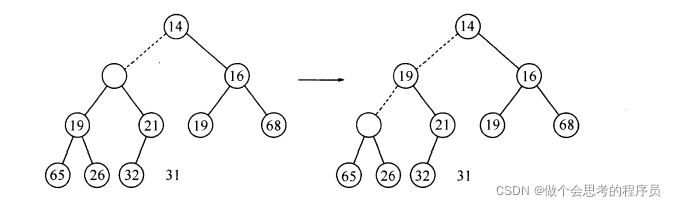
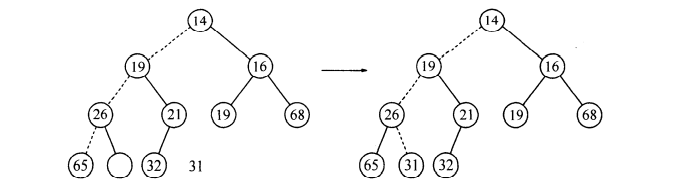
好了,读者看到了这里也相当颇有耐心了,接下来我们就来具体看看如何建立一个小根堆的过程:
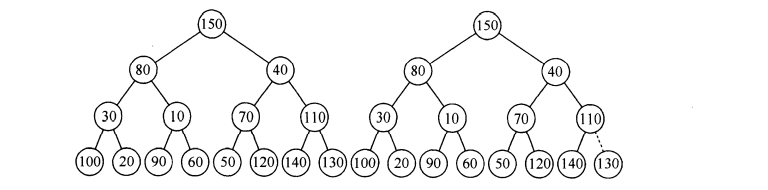
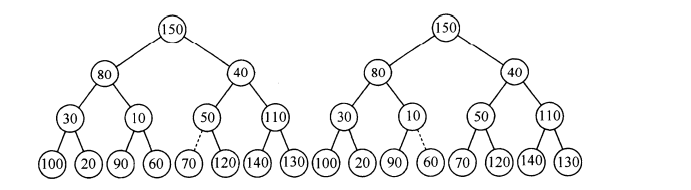
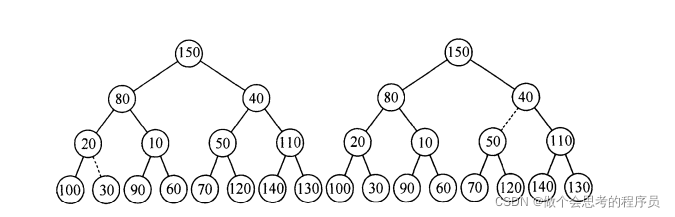
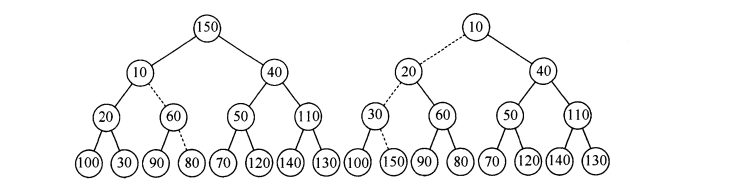
//设置优先队列的初始容量
private static final int DEFAULT_CAPACITY = 10;
//设置当前元素的个数
private int currentSize;
//存储元素的数组
private AnyType[] array;
//初始化
public PriorityQueueByBinaryHeap() {
array = (AnyType[]) new Comparable[DEFAULT_CAPACITY];
this.currentSize = 0;
}
public PriorityQueueByBinaryHeap(int capacity) {
array = (AnyType[]) new Comparable[capacity];
this.currentSize = 0;
}
public PriorityQueueByBinaryHeap(AnyType...items) {
currentSize = items.length;
array = (AnyType[]) new Comparable[(currentSize+2)*11/10];
int i = 1;
for (AnyType item : items) {
array[i++] = item;
}
buildHeap();
}
//建立堆(自顶向下建立堆)
private void buildHeap() {
for (int i = currentSize/2; i > 0; i--) {
percolateDown(i);
}
}
public AnyType deleteMin(){
if (isEmpty()) {
return null;
}
AnyType minItem = finMin();
array[1] = array[currentSize--];
return minItem;
}
private AnyType finMin() {
return isEmpty() ? null : array[1];
}
//下滤
private void percolateDown(int hole) {
int child = 0;
AnyType temp = array[hole];
for ( ; hole*2 <= currentSize; hole = child) {
child = hole*2;
//将它左边孩子和右边孩子的优先级进行比较
if (child != currentSize && array[child+1].compareTo(array[child]) < 0) {
child++;
}
//将上面比较出来结果和要下滤的元素进行比较
if (array[child].compareTo(temp) < 0) {
array[hole] = array[child];
} else {
break;
}
}
array[hole] = temp;
}
private boolean isEmpty() {
return currentSize == 0;
}
下面是实现一个堆的完整代码。
public class PriorityQueueByBinaryHeap<AnyType extends Comparable<? super AnyType>> {
//设置优先队列的初始容量
private static final int DEFAULT_CAPACITY = 10;
//设置当前元素的个数
private int currentSize;
//存储元素的数组
private AnyType[] array;
//初始化
public PriorityQueueByBinaryHeap() {
array = (AnyType[]) new Comparable[DEFAULT_CAPACITY];
this.currentSize = 0;
}
public PriorityQueueByBinaryHeap(int capacity) {
array = (AnyType[]) new Comparable[capacity];
this.currentSize = 0;
}
/**
* 二叉堆是有一些初始集合构成的。
* 这种方式以N顶作为输入,并把他们放入一个建立好的堆中,每个插入到堆中的时间复杂度是O(1)平均复杂度
* O(logN)是最坏的时间复杂度,因此是先将集合中的元素任意放入树中,先保持好二叉树的特性,然后再通过下滤来达到堆的性质
* @param items
*/
public PriorityQueueByBinaryHeap(AnyType...items) {
currentSize = items.length;
array = (AnyType[]) new Comparable[(currentSize+2)*11/10];
int i = 1;
for (AnyType item : items) {
array[i++] = item;
}
buildHeap();
}
//建立堆(自顶向下建立堆)
private void buildHeap() {
for (int i = currentSize/2; i > 0; i--) {
percolateDown(i);
}
}
/**
* 插入操作:
* 维持一个堆结构,我们需要在最后一个雨伞的下一位置添加一个空的结点,暂时作为一个新元素的插入位置,这样就不会破坏堆的结构
* 但是堆序性无法得到满足,因此需要将待插入的元素和父节点进行比较,如果待插入的元素优先级低于待插入位置的父节点的优先级,
* 则直接将元素插入这个位置上,否则交换插入结点和父节点的位置。然后不对的往上比较,使得这个节点不断向上来调整,使得满足堆的特性
* 当找到合适的位置后将其插入,那么这一个过程叫做调也叫做上滤,并且待插入节点上滤的过程中,无论怎么样去调整,
* 只会涉及完全二叉树的某一条链路(因为只会和它的父节点进行调整,不会和它的兄弟结点调整),所以上滤的时间复杂度就是O(logN)
* @param x
*/
public void insert(AnyType x) {
if (this.currentSize == array.length-1) { //扩容
enlargeArray(array.length*2+1);
}
//上滤操作,新的元素在上滤过程中找到正确的位置
int hole = ++currentSize;
percolateUp(hole);
}
//上滤
private void percolateUp(int hole) {
AnyType temp = array[hole];
for ( ; temp.compareTo(array[hole/2]) < 0; hole /= 2) {
array[hole] = array[hole/2];
array[hole] = temp;
}
}
//扩容
private void enlargeArray(int newSize) {
if (newSize <= array.length) {
return ;
} else {
AnyType[] oldArray = array;
array = (AnyType[]) new Comparable[newSize];
for (int i = 0; i < currentSize; i++) {
array[i] = oldArray[i];
}
}
}
/**
* 删除最小值的元素(优先级最高的)
* 1.先找到优先级最高的元素并且删除它,因为这是一个堆结构的优先队列,它的优先就最高的元素就是根元素,因此找到优先级最高的元素的代价的时间复杂度是O(1)
* 但是这里并不能直接删除它,因为会破坏堆的结构,因此先让这个根为空,然后将堆中最底层的最后一个元素X来移动到根处,这样删除最后一个元素,仍然保存了堆的结构性,
* 那么接下来如何保证它的堆序性呢,做法是让X的两个儿子结点中优先级最高的一个和它交换位置,使得这个元素下降一层,这样由优先级最高的元素又变成了新的根,
* 然后让X不断的与它的两个儿子的有优先级比较,直到X找到属于自己新的位置
* @param
*/
public AnyType deleteMin(){
if (isEmpty()) {
return null;
}
AnyType minItem = finMin();
array[1] = array[currentSize--];
return minItem;
}
private AnyType finMin() {
return isEmpty() ? null : array[1];
}
/**
* 下滤
* @param hole
*/
private void percolateDown(int hole) {
int child = 0;
AnyType temp = array[hole];
for ( ; hole*2 <= currentSize; hole = child) {
child = hole*2;
//将它左边孩子和右边孩子的优先级进行比较
if (child != currentSize && array[child+1].compareTo(array[child]) < 0) {
child++;
}
//将上面比较出来结果和要下滤的元素进行比较
if (array[child].compareTo(temp) < 0) {
array[hole] = array[child];
} else {
break;
}
}
array[hole] = temp;
}
private boolean isEmpty() {
return currentSize == 0;
}
public void show() {
for (int i = 1; i <= currentSize; i++) {
System.out.print(array[i]+",");
}
System.out.println();
}
public static void main(String[] args) {
PriorityQueueByBinaryHeap pQ = new PriorityQueueByBinaryHeap(150,80,40,30,10,70,110,100,20,90,60,50,120,140,130);
System.out.print("小根堆的数据:");
pQ.show();
}
}
写到这里一个堆实现的优先队列就接近尾声了,这些只是一个入门,后续我还会继续更新些d-堆,斜堆等,当然不仅局限于数据结构与算法,后期还会扩展操作系统,计算机组成原理,计算机网络,编译原理,数据库原理等的底层内容,以及数学的相关知识,让我们一起来探究计算机的本源。我会保持不断的学习,持续关注我。














 1936
1936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









