







目录
一、Prometheus介绍
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
二、Prometheus特点
2.1、prometheus特点
1)多维度数据模型
每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
2)灵活的查询语言(PromQL):可以对采集的metrics指标进行加法,乘法,连接等操作;
3)可以直接在本地部署,不依赖其他分布式存储;
4)通过基于HTTP的pull方式采集时序数据;
5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
7)有多种可视化图像界面,如Grafana等。
8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
2.2、什么是样本
样本:在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(
metric):指标名称和描述当前样本特征的 labelsets; - 时间戳(
timestamp):一个精确到毫秒的时间戳; - 样本值(
value): 一个 folat64 的浮点型数据表示当前样本的值。
表示方式:通过如下表达方式表示指定指标名称和指定标签集合的时间序列:<metric name>{<label name>=<label value>, ...}
例如,指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为:api_http_requests_total{method="POST", handler="/messages"}
三、Prometheus组件介绍
1)Prometheus Server: 用于收集和存储时间序列数据。
2)Client Library: 客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
3)Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
4)Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。
5)Grafana:监控仪表盘,可视化监控数据
6)pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
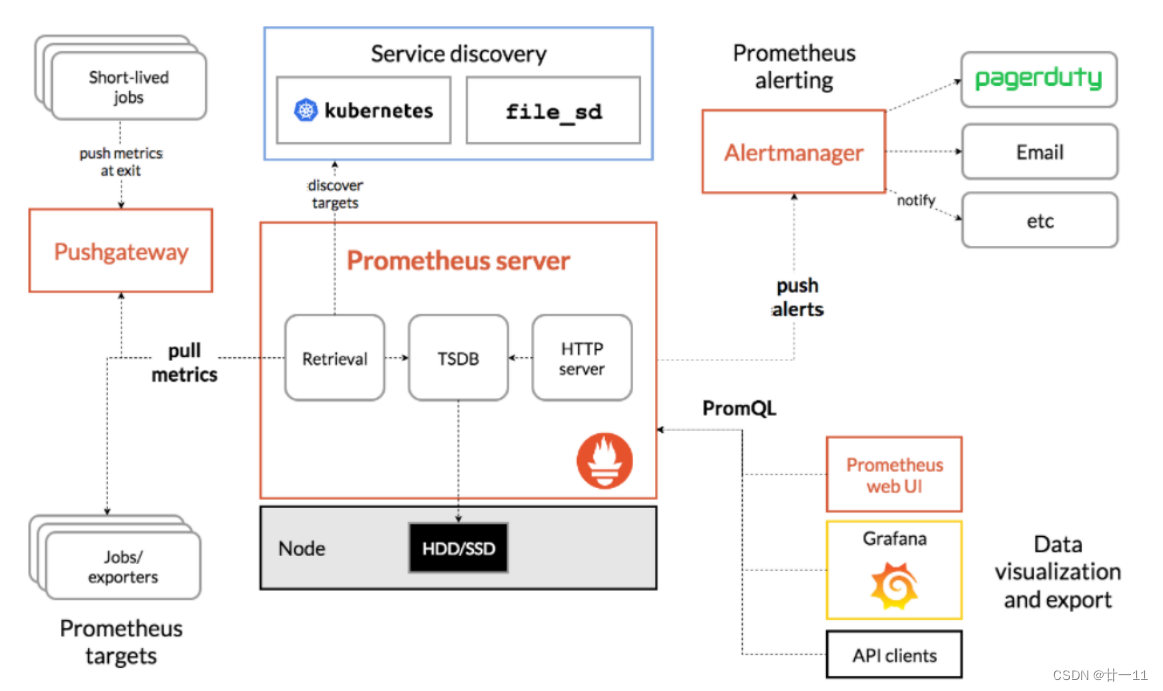
从上图可发现,Prometheus整个生态圈组成主要包括prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui界面,Prometheus server由三个部分组成,Retrieval,Storage,PromQL
Retrieval负责在活跃的target主机上抓取监控指标数据Storage存储主要是把采集到的数据存储到磁盘中PromQL是Prometheus提供的查询语言模块。
四、Prometheus工作流程
1)Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据;
2)Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
3)Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
4)Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
5)Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
6)Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
五、Prometheus和zabbix对比分析
| Zabbix | Prometheus |
| 后端用C开发,界面用PHP开发,定制化难度很高 | 后端用golang开发,前端是Grafana,JSON编辑即可解决,定制化难度较低 |
| 集群规模上限为10000个节点 | 支持更大的集群规模,速度也更快 |
| 更适合监控物理机环境 | 更适合云环境的监控,对OpenStack,Kubernetes有更好的集成 |
| 监控数据存储在关系型数据库内,如MySQL,很难从现有数据中扩展维度 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合 |
| 安装简单,zabbix-server一个软件包中包括了所有的服务端功能 | 安装相对复杂,监控、告警和界面都分属于不同的组件 |
| 图形化界面比较成熟,界面上基本上都能完成全部的配置操作 | 界面相对较弱,很多配置需要修改配置文件 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案 | 2015年后开始快速发展,但发展时间较短,成熟度不及Zabbix |
六、Prometheus的几种部署模式
6.1、基本高可用模式
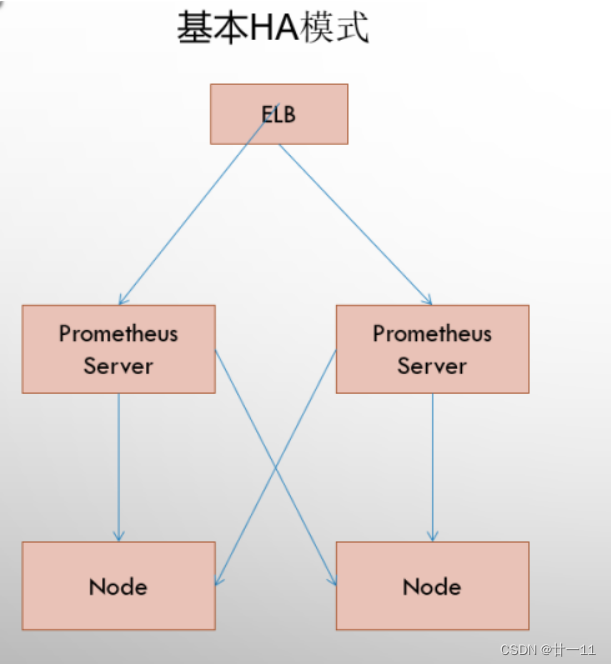
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
6.2、基本高可用+远程存储

在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
6.3、基本HA + 远程存储 + 联邦集群方案
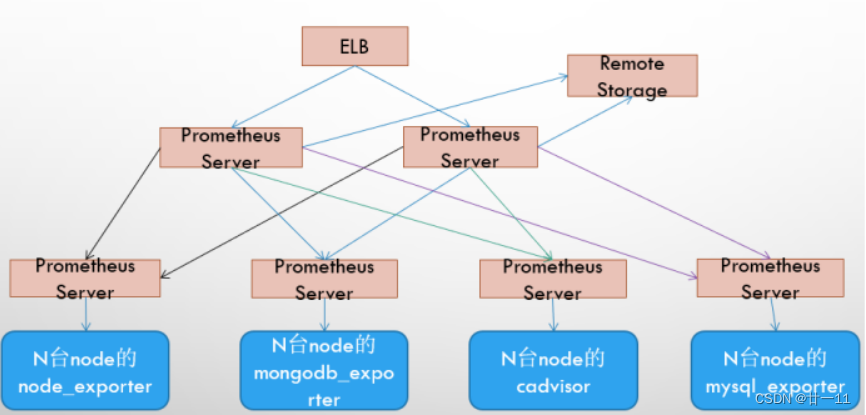
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
七、Prometheus的四种数据类型
7.1、Counter
Counter是计数器类型:
- Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
- 一直增加,不会减少。
- 重启进程后,会被重置。
# Counter类型示例
http_response_total{method="GET",endpoint="/api/tracks"} 100
http_response_total{method="GET",endpoint="/api/tracks"} 160Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来进行说明
1)通过rate()函数获取HTTP请求量的增长率:rate(http_requests_total[5m])
2)查询当前系统中,访问量前10的HTTP地址:topk(10, http_requests_total)
7.2、Gauge
Gauge是测量器类型:
- Gauge是常规数值,例如温度变化、内存使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
# Gauge类型示例
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80 对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
7.3、Histogram
7.3.1、Histogram作用及特点
histogram是柱状图,在Prometheus系统的查询语言中,有三种作用:
1)在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
2)对每个采样点值累计和(sum)
3)对采样点的次数累计和(count)
度量指标名称: [basename]上面三类的作用度量指标名称
1)[basename]bucket{le="上边界"}, 这个值为小于等于上边界的所有采样点数量
2)[basename]_sum_
3)[basename]_count小结:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
7.3.2、为什需要用histogram柱状图
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标(假设指标名称为 <basename>):
1)样本的值分布在 bucket 中的数量,命名为 <basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
# 1、在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
# 2、在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0
# 3、在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0
# 4、在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.02)所有样本值的大小总和,命名为 <basename>_sum
# 实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.1076708030000013)样本总数,命名为 <basename>_count,值和 <basename>_bucket{le="+Inf"} 相同
# 实际含义: 当前一共发生了 2 次 http 请求
io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0注意:
1)bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的采样点是包含前面的采样点的,假设 xxx_bucket{...,le="0.01"} 的值为 10,而 xxx_bucket{...,le="0.05"} 的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 0.01s的,其余 20 个采样点的响应时间是介于0.01s 和 0.05s之间的。
2)可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。分位数可能不太好理解,你可以理解为分割数据的点。我举个例子,假设样本的 9 分位数(quantile=0.9)的值为 x,即表示小于 x 的采样值的数量占总体采样值的 90%。Histogram 还可以用来计算应用性能指标值(Apdex score)。
7.4、Summary
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。它也有三种作用:
1)对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
2)统计班上所有同学的总成绩(sum)
3)统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据有如命名。
1、观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数="[φ]"}
2、[basename]_sum, 是指所有观察值的总和_
3、[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为 <basename>{quantile="<φ>"}。
# 1、含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983
# 2、含义:这 12 次 http 请求中有 90% 的请求响应时间是 8.003261666s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666所有样本值的大小总和,命名为 <basename>_sum。
# 1、含义:这12次 http 请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sum{path="/",method="GET",code="200",} 51.029495508样本总数,命名为 <basename>_count。
# 1、含义:当前一共发生了 12 次 http 请求
io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",} 12.0Histogram 与 Summary 的异同:
它们都包含了 <basename>_sum 和 <basename>_count 指标,Histogram 需要通过 <basename>_bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
# 从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。八、Prometheus能监控什么
# Databases---数据库
Aerospike exporter
ClickHouse exporter
Consul exporter (official)
Couchbase exporter
CouchDB exporter
ElasticSearch exporter
EventStore exporter
Memcached exporter (official)
MongoDB exporter
MSSQL server exporter
MySQL server exporter (official)
OpenTSDB Exporter
Oracle DB Exporter
PgBouncer exporter
PostgreSQL exporter
ProxySQL exporter
RavenDB exporter
Redis exporter
RethinkDB exporter
SQL exporter
Tarantool metric library
Twemproxy
# Hardware related---硬件相关
apcupsd exporter
Collins exporter
IBM Z HMC exporter
IoT Edison exporter
IPMI exporter
knxd exporter
Netgear Cable Modem Exporter
Node/system metrics exporter (official)
NVIDIA GPU exporter
ProSAFE exporter
Ubiquiti UniFi exporter
# Messaging systems---消息服务
Beanstalkd exporter
Gearman exporter
Kafka exporter
NATS exporter
NSQ exporter
Mirth Connect exporter
MQTT blackbox exporter
RabbitMQ exporter
RabbitMQ Management Plugin exporter
# Storage---存储
Ceph exporter
Ceph RADOSGW exporter
Gluster exporter
Hadoop HDFS FSImage exporter
Lustre exporter
ScaleIO exporter
# HTTP---网站服务
Apache exporter
HAProxy exporter (official)
Nginx metric library
Nginx VTS exporter
Passenger exporter
Squid exporter
Tinyproxy exporter
Varnish exporter
WebDriver exporter
# APIs
AWS ECS exporter
AWS Health exporter
AWS SQS exporter
Cloudflare exporter
DigitalOcean exporter
Docker Cloud exporter
Docker Hub exporter
GitHub exporter
InstaClustr exporter
Mozilla Observatory exporter
OpenWeatherMap exporter
Pagespeed exporter
Rancher exporter
Speedtest exporter
# Logging---日志
Fluentd exporter
Google's mtail log data extractor
Grok exporter
# Other monitoring systems
Akamai Cloudmonitor exporter
Alibaba Cloudmonitor exporter
AWS CloudWatch exporter (official)
Cloud Foundry Firehose exporter
Collectd exporter (official)
Google Stackdriver exporter
Graphite exporter (official)
Heka dashboard exporter
Heka exporter
InfluxDB exporter (official)
JavaMelody exporter
JMX exporter (official)
Munin exporter
Nagios / Naemon exporter
New Relic exporter
NRPE exporter
Osquery exporter
OTC CloudEye exporter
Pingdom exporter
scollector exporter
Sensu exporter
SNMP exporter (official)
StatsD exporter (official)
# Miscellaneous---其他
ACT Fibernet Exporter
Bamboo exporter
BIG-IP exporter
BIND exporter
Bitbucket exporter
Blackbox exporter (official)
BOSH exporter
cAdvisor
Cachet exporter
ccache exporter
Confluence exporter
Dovecot exporter
eBPF exporter
Ethereum Client exporter
Jenkins exporter
JIRA exporter
Kannel exporter
Kemp LoadBalancer exporter
Kibana Exporter
Meteor JS web framework exporter
Minecraft exporter module
PHP-FPM exporter
PowerDNS exporter
Presto exporter
Process exporter
rTorrent exporter
SABnzbd exporter
Script exporter
Shield exporter
SMTP/Maildir MDA blackbox prober
SoftEther exporter
Transmission exporter
Unbound exporter
Xen exporter
# Software exposing Prometheus metrics---Prometheus度量指标
App Connect Enterprise
Ballerina
Ceph
Collectd
Concourse
CRG Roller Derby Scoreboard (direct)
Docker Daemon
Doorman (direct)
Etcd (direct)
Flink
FreeBSD Kernel
Grafana
JavaMelody
Kubernetes (direct)
Linkerd九、Prometheus对kubernetes的监控
对于Kubernetes而言,我们可以把当中所有的资源分为几类:
- 基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
- 容器基础设施(Container):为应用提供运行时环境
- 用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
- 内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
- 外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
因此,如果要构建一个完整的监控体系,我们应该考虑,以下5个方面:
- 集群节点状态监控:从集群中各节点的kubelet服务获取节点的基本运行状态;
- 集群节点资源用量监控:通过Daemonset的形式在集群中各个节点部署Node Exporter采集节点的资源使用情况;
- 节点中运行的容器监控:通过各个节点中kubelet内置的cAdvisor中获取个节点中所有容器的运行状态和资源使用情况;
- 如果在集群中部署的应用程序本身内置了对Prometheus的监控支持,那么我们还应该找到相应的Pod实例,并从该Pod实例中获取其内部运行状态的监控指标。
- 对k8s本身的组件做监控:apiserver、scheduler、controller-manager、kubelet、kube-proxy















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









