






Set集合的定义
Java集合是一种特别有用的工具类,可用于存储数量不等的对象,并可以实现常用的数据结构,如栈、队列等。其中Set集合代表无序、不可重复的集合。他类似于一个罐子,程序可以依次把多个对象“丢件”Set集合,而Set集合通常不能记住元素的添加顺序。Set集合与Collection基本相同,没有提供任何额外的方法。实际上Set就是Collection,只是行为略有不同(Set集合不允许包含重复元素)。Set接口继承自Collection接口且有以下实现,框出来的是经常用的,需要了解掌握。

因为set接口的父接口是Collection,所以Collection的一些方法Set集合都有,如下:

HashSet
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很难好的存取和查找性能。
HashSet具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
- HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或两个以上线程同时修改了HashSet的集合时,则必须通过代码来保持其同步。
- 集合元素可以是null。
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals()方法比较返回true,但他们的hashCode()方法返回值不相同,HashSet将会把它们存储在不同的位置,依然可以添加成功。也就是说,HashSet集合判断两个元素是否相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
package ex.hql.set;
import java.util.HashSet;
import java.util.Set;
class A{
@Override
public boolean equals(Object obj) {
return true;
}
}
class B{
@Override
public int hashCode() {
return 1;
}
}
class C{
//重写该方法返回相同的hashcode,但两个对象通过equals比较false,会导致HashSet能存储元素的槽位(slot)放多个元素,这样会导致性能下降
@Override
public int hashCode() {
return 2;
}
@Override
public boolean equals(Object obj) {
return true;
}
}
public class HashSetDemo {
public static void main(String[] args) {
Set set=new HashSet();
set.add(new A());
set.add(new A());
set.add(new B());
set.add(new B());
set.add(new C());
set.add(new C());
System.out.println(set);
}
}
创建A,B,C类,A类重写equals()方法,B类重写hashCode()方法,C类重写这两个方法,创建HashSet集合,加入这几个类,输出结果如下,可以看出C类只添加了一个,A,B类都添加成功两个。
可见:当把一个对象放入HashSet中,如果需要重写该对象对应类的equals()方法,则也应该重写其HashCode()方法。规则是:如果两个对象通过equals()方法比较返回true,这两个对象的hashCode值也应该相等。

如果向HashSet中添加一个可变对象后,后面程序修改了该可变对象的实例,则可能导致它与集合中的其它元素相等(即两个对象通过equals()方法返回比较true,两个对象的hashCode值也相等),这就有可能导致HashSet中包含两个相同的对象,有以下例子
package ex.hql.set;
import javax.jws.soap.SOAPBinding;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
class D{
int number;
public D(int number) {
this.number = number;
}
@Override
public String toString() {
return "D{" +
"number=" + number +
'}';
}
@Override
public boolean equals(Object obj) {
if(this==obj)
return true;
if(obj!=null&&obj.getClass()==D.class){
D d=(D)obj;
return this.number==d.number;
}
return false;
}
@Override
public int hashCode() {
return this.number;
}
}
public class HashSetDemo2 {
public static void main(String[] args) {
Set set=new HashSet();
set.add(new D(6));
set.add(new D(-4));
set.add(new D(8));
set.add(new D(3));
System.out.println(set);
Iterator iterator=set.iterator();
D d=(D)iterator.next();//获取集合中的第一个对象
d.number=3;
System.out.println(set);
set.remove(new D(3));
System.out.println(set);
System.out.println("集合是否包含number为3的对象:"+set.contains(new D(3)));
System.out.println("集合是否包含number为-4的对象:"+set.contains(new D(-4)));
}
}
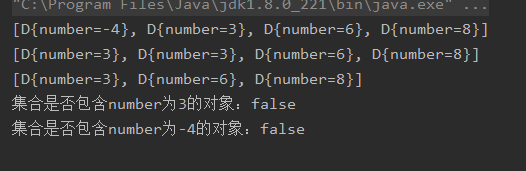
当试图删除number为3的对象时,HashSet会计算出该对象的hashCode值,从而找出该对象在集合中的存储的位置,然后把此处的对象与number为3的对象通过equals()方法进行比较,如果相同则删除该对象—HashSet只有第二个元素满足该条件,第一个元素实际存在hashCode为-4的对象的位置上,所以第二个元素被删除。第一个number为3的对象,保存在number为-4的位置上,通过equals比较为-4的对象又不相等返回false,这将导致HashSet不能准确的访问该元素。由此可见,当程序把可变对象添加到HashSet中之后,不要再去修改该集合元素中参与计算hashCode()、equals()的实例变量。
LinkedHashSet
LinkedHashSet是HashSet的一个子类,也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表来维护元素的次序,这样使得元素看起来是以插入的顺序保存的,因为要维护元素的插入顺序,因此性能略低于HashSet的性能。
package ex.hql.set;
import java.util.LinkedHashSet;
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet linkedHashSet=new LinkedHashSet();
linkedHashSet.add("第一个插入的");
linkedHashSet.add("第二个插入的");
linkedHashSet.add("第三个插入的");
linkedHashSet.add("第四个插入的");
linkedHashSet.add("第五个插入的");
System.out.println(linkedHashSet);
}
}
运行结果:

TreeSet
TreeSet是SortedSet接口的实现类,可以确保集合元素处于排序状态,TreeSet还提供了以下额外的方法:

package ex.hql.set;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet treeSet=new TreeSet();
treeSet.add(4);
treeSet.add(-6);
treeSet.add(19);
treeSet.add(8);
System.out.println(treeSet);
//输出最后一个元素
System.out.println(treeSet.last());
//输出集合中小于4的元素
System.out.println(treeSet.headSet(4));
//输出集合中大于8的元素,若集合中存在8,则包含8
System.out.println(treeSet.tailSet(8));
//返回大于-1,小于2的子集
System.out.println(treeSet.subSet(-1,2));
}
}
输出结果如下:
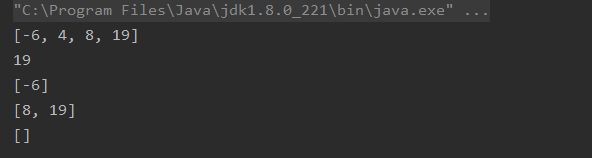
TreeSet支持两种排序方法:自然排序和定制排序,默认情况下采用自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小,然后将集合元素按升序排列,这种方式就是自然排序。
Java提供了一个Comparable接口,该接口定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类就可以比较大小。当一个对象调用该方法与另一个对象比较时,如果该方法返回0,表明这两个对象相等;如果该方法返回一个正整数,则表明大于;返回负数表示小于。
如果要将一个对象添加到TreeSet,该对象一定要实现Comparable接口,否则会抛出异常:
package ex.hql.set;
import java.util.TreeSet;
class F{
}
public class NatureDemo {
public static void main(String[] args) {
TreeSet set=new TreeSet();
set.add(new F());
}
}

TreeSet只能添加同一种类型的对象,判断两个对象是否相等的唯一标准是通过compareTo(Object obj)方法比较是否返回0,为0相等,否则不相等。
package ex.hql.set;
import java.util.TreeSet;
class F implements Comparable{
int number;
public F(int number) {
this.number = number;
}
@Override
public boolean equals(Object obj) {
return true;
}
@Override
public int compareTo(Object o) {
return 1;
}
}
public class NatureDemo {
public static void main(String[] args) {
TreeSet set=new TreeSet();
F f=new F(3);
//添加两个重复的元素
set.add(f);
set.add(f);
System.out.println(set);
}
}
输出如下:

从图可以看到虽然通过equals()方法比较两个元素相等,但是compareTo()方法比较不相等还是能添加重复的两个元素,所以如果要重写方法,傲保证这两个方法比较返回的值是一样的。
需要注意的是:推荐不要修改放入TreeSet集合中元素的关键实例变量,与上面的HashSet一样,因为这样可能导致出错。
定制排序
实现定制排序,需要通过Comparator接口的帮助,该接口里包含了一个int compare(T o1,T o2)方法,该方法用于比较o1和o2的大小;如果该方法返回0,表示相等;返回负数,表示o1小于o2.
如果需要实现定制排序,需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排列逻辑。
package ex.hql.set;
import java.util.Comparator;
import java.util.TreeSet;
class H{
int number;
public H(int number) {
this.number = number;
}
@Override
public String toString() {
return "H{" +
"number=" + number +
'}';
}
}
public class SpecificDemo {
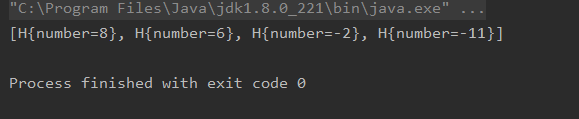
public static void main(String[] args) {
//实现降序排列,这里采用的是匿名内部类的方式,也可以用lambda表达式
TreeSet set=new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
H h1=(H)o1;
H h2=(H)o2;
return h1.number>h2.number?-1:h1.number<h2.number?1:0;
}
});
set.add(new H(-2));
set.add(new H(6));
set.add(new H(-11));
set.add(new H(8));
System.out.println(set);
}
}
输出结果如下:
EnumSet类
EnumSet是一个专门为枚举类设计的集合类,其中的所有元素必须是指定枚举类型的枚举值,该枚举类型在创建的时候显示的指或隐式的指定。EnumSet集合也是有序的,以枚举值在Enum类内的定义顺序来决定集合元素的顺序(不允许加入null)。
该类提供了以下方法:

各Set实现的性能
HashSet的性能总比TreeSet好(特别是最常用的添加,查询元素等操作),因为TreeSet需要额外的红黑树来维护集合元素的次序。只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该时候HashSet.
LinkedHashSet相比于HashSet,插入,删除略慢,遍历更快。
EnumSet是所有Set类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
HashSet,TreeSet,EnumSet线程都是不安全的,通常可以通过Collections工具类的synchronizedSortedSet方法来包装这些Set集合使其变得安全。














 7006
7006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









