








要求:
1,选取wordcount和sort两个程序,每个程序五个输入数据集
2,wordcount数据集(20M,100M,500M,1G,2G)
3,sort数据集(20M,100M,500M,1G,2G)
4,对每个程序分别对比程序执行时间
5,选几个重要的性能计数器(6个以上),观察性能计数器的变化
6,画图表,总结分析
一、操作过程:
Wordcount操作
(1)使用dd命令产生5个文件,分别为1M、5M、10M、20M、40M





(2)将文件上传至hdfs

(3)执行Wordcount程序
1M

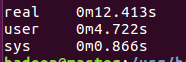





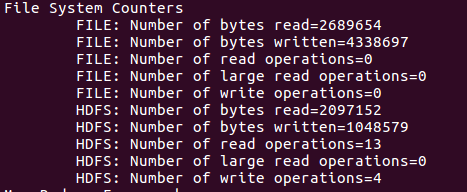

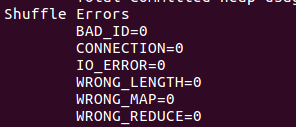


 其它的更这个差不多····我写不动了
其它的更这个差不多····我写不动了
让我们开始terasort吧
taresort
执行teragen生成数据1M、5M、10M、20M、40M
注意,teragen后的数值单位是行数;因为每行100个字节,所以如果要产生1T的数据量,则这个数值应为1T/100=10000000000(10个0)。
time hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar teragen 10000 /terasort/input-1M
1M的


其它也差不多一样,就不写出来了
执行taresort排序
这次举5M的例

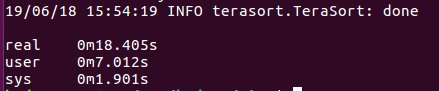

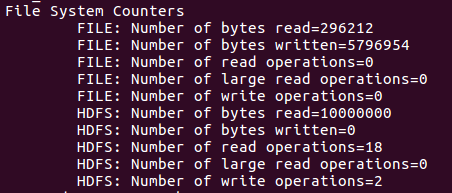



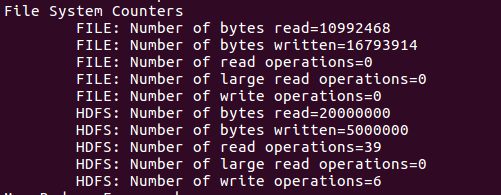



当然,你也可以执行
time hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar terasort /wordcountInput/wordcountinput-40M /terasort/output-40M
用之前wordcount1时创建的文件来用terasort运行
二:对比
(1)时间对比

(2)6个性能计数器对比

















 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









