






MySQL的内部数据组织方式
在MySQL中, 我们对数据的组织逻辑上是按照库/表/数据 这种结构组织的.
数据库: 表示一份完整的数据仓库, 在这个数据仓库中分为多张不同的表.
表: 表示某种特定类型数据的的结构化清单, 里面包含多条数据.
数据: 表中数据的基本单元.

登录数据库
mysql -u root -p [回车]
输入密码
注释
-- <注释>; # 注释语句 # <注释>; # 注释语句 /* <注释> # 注释语句 */注意:
在数据库语句中如果我们需要注释某些内容, 一般有三种方式
--注释符(要注意的是--之后要有一个空格再接着书写注释内容)
#注释符 (之后不需要空格)
/* */注释符 (一般用于多行注释)
注2: 分号
SQL语句应该要以分号作为结束
库操作
查看数据库
show databases; # 查看所有数据库 show databases like '%数据库名%'; # 查看和期望命名相匹配的数据库 show create database 数据库名; # 查看数据库创建信息 show databases like 'test'; -- 指明就找test eg: show databases like '%n'; -- 一个以n字符结束的数据库 show databases like '%n%'; -- 数据库名字中, 有一个n字符 show create database test; -- 查看之前怎么创建的test数据库(sql语句是什么)
information_schema:主要存储了系统中的一些
数据库对象信息,比如用户表信息、列信息、权限信息、字符集信息和分区信息等。mysql:MySQL 的核心数据库,主要负责存储数据库
用户、用户访问权限等 MySQL 自己需要使用的控制和管理信息。常用的比如在 mysql 数据库的 user 表中修改 root 用户密码。
update mysql.user set authentication_string=password(‘123456’) where user=‘root’;
flush privileges;performance_schema:主要用于
收集数据库服务器性能参数。sys:sys 数据库主要提供了一些视图,数据都来自于 performation_schema,主要是让开发者和使用者更
方便地查看性能问题。

创建数据库
create database [if not exists] <数据库名> [[default]character set <字符集名>] [[default] collate <校对规则名>]; eg: 创建一个db47的数据库, 有可能创建失败直接报错(假如数据库服务里面已经有一个db47的数据库了) create database db47; 如果不存在名字为db47的数据库, 就创建db47, 如果已经存在了db47的数据库, 就不创建(也不报错) create database if not exists db47; 创建一个指定字符编码格式的和指定排序规则的数据库 create database if not exists test character set utf8 collate utf8_bin;
[ ]可选。<数据库名>:创建数据库的名称。
IF NOT EXISTS:在创建数据库之前进行判断,只有该数据库目前尚不存在时才能执行操作。
[DEFAULT] CHARACTER SET:指定数据库的字符集。
[DEFAULT] COLLATE:指定字符集的默认校对规则(utf8使用utf8_bin)。
注:一些注意事项编码格式utf8, utf8mb4, 尤其注意
数据库的默认的编码格式: latin1. 所以一定要在创建数据库的时候指明utf8格式的数据库编码格式.
- UTF8 和UTF8MB4的区别
(1) 5.5.3 版本以后的才支持UTF8MB4 (2) UTF8MB4是 UTF8 的超集并完全兼容UTF8。 (3) UTF8(也称UTF8MB3),1字符最多使用3字节存储。 (4) UTF8MB4,1字符最多使用4字节存储。(专门用来兼容4字节的UNICODE编码-平面设计-Emoji问题)。
删除数据库: 完全不建议
删除数据库 DROP DATABASE [IF EXISTS] <数据库名>; eg: 删除test数据库 drop database test;
修改数据库: 完全不建议
数据库中只提供了对数据库使用的字符集和校对规则修改操作。
ALTER DATABASE [数据库名] { [ DEFAULT ] CHARACTER SET <字符集名> | [ DEFAULT ] COLLATE <校对规则名> }; eg: 把test数据库的编码改成utf8, 校对规则改为utf8_bin alter database test character set utf8 collate utf8_bin;
选择数据库
一个MySQL系统中, 管理多个数据库。 我们只有进入对应的数据库中, 才能进一步操作数据库中的数据。
选择数据库 USE <数据库名>; eg: 选择test数据库 use test;
表操作
常见的数据类型
(1) 整数
| MySQL的整数类型 | 占用字节 | 有符号 | 无符号 | 说明 |
|---|---|---|---|---|
| TINYINT(M) | 1 | -128 ~ 127 | 0 ~ 255 | 很小的整数 |
| INT/INTEGER(M) | 4 | -231 ~ 231-1 | 0 ~ 232-1 | 普通整数 |
| BIGINT(M) | 8 | -263 ~ 263-1 | 0 ~ 264-1 | 大整数 |
注意1:
int和integer在MySQL中并无区别(完全等价), 仅是缩略写法.link。
注意2: 关于
整数设置’长度/宽度’问题。 int(4) 第一原则:无论给整数设置什么长度都不违背上述’有/无符号’表示的存储范围(上述范围表示是一切基本标准)。
第二原则: 设置长度之后, 如果存储的整数长度小于指定长度, 会默认在数字位前自动补空格, 也可以选择设置使用0填充(zerofill: 填充0,效果:0001),以满足指定长度(但是这是不可见的); 设置长度之后, 如果存储的整数长度大于指定长度, 如果在表示范围内, 不做切割/不做处理, 直接存储。
CREATE TABLE `tb_test` ( `id` int NOT NULL, `age` int ZEROFILL NULL, -- zerofill: 填充0 PRIMARY KEY (`id`) );
esc键下面的上点 “`”表示将圈起来的字符串作为普通字符串,与关键字区分
(2) 浮点数
| MySQL的浮点数 | 占用字节 | 说明 |
|---|---|---|
| FLOAT(M, D) | 4 | 单精度 |
| DOUBLE(M, D) | 8 | 双精度 |
M: 精度, 表示总数据位数。 取值范围为(1~255)。
D: 标度, 表示小数位的位数。 取值范围为(1~30,且不能大于 M-2)。
FLOAT 和 DOUBLE 在不指定精度时,默认会按照实际的精度(由计算机硬件和操作系统决定)。
-- FLOAT 类型的取值范围如下: 有符号的取值范围:-3.402823466E+38~-1.175494351E-38。 无符号的取值范围:0 和 -1.175494351E-38~-3.402823466E+38。 -- DOUBLE 类型的取值范围如下: 有符号的取值范围:-1.7976931348623157E+308~-2.2250738585072014E-308。 无符号的取值范围:0 和 -2.2250738585072014E-308~-1.7976931348623157E+308。
(3) 日期
| MySQL日期 | 字节 | 日期格式 | 表示范围 |
|---|---|---|---|
| YEAR | 1 | YYYY | 1901 ~ 2155 |
| TIME | 3 | HH:MM:SS | -838:59:59 ~ 838:59:59 |
| DATE | 3 | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| DATETIME | 8 | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP | 4 | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
- YEAR范围: 1901~ 2155包含255个年份, 对应一个字节表示范围。
- TIME范围: 11111111111111111111111(23位剩余一位符号位)–> 8388607(十进制)
8388607: 838(小时位) xx(描述分钟) xx(描述秒)。- TIMESTAMP范围: (时间戳)
1970年1月1日作为UNIX TIME的纪元时间(开始时间)。
231-1 = 2147483647 --> 24855(day)3(h)14(m)07(s)
24855(day)3(h)14(m)07(s) + 1980-01-01 00:00:01 -> 2038-01-19 03:14:07。
(4) 字符串: 非常重要
在MySQL中, 字符串,分为两种类型, 定长 和 变长
| MySQL字符串 | 内存占用 | 说明 |
|---|---|---|
| CHAR(M) | (M * 单个字符占用字节) | 固定长度字符串 |
| VARCHAR(M) | L+1字节 or L+2字节 (L=M*单个字符占用字节) | 变长字符串 |
| TEXT(M) | L+2字节 。 L: 0~216 (L=M*单个字符占用字节) | 变长文本字符串 |
| LONGTEXT(M) | L+4字节 。 L: 0~232(L=M*单个字符占用字节) | 变长大文本字符串 |
注意: 如果给这个字符串指明了长度 (eg: name varchar(3), => 要求name最长是3 ), 要存储数据的时候, 必须遵照这个定义长度(这不同于int类型, 因为int类型即使定义了长度, 也是可以超过的, 只要是在int类型的合法表示范围内), 不可以超过.
L: 存储字符的实际长度。
M: 列的指定长度。
- CHAR (M不设置默认为1) 范围可以设置最大255 。
- VARCHAR最大长度为 65,535
- TEXT 最大长度为 65535字符
- LONGTEXT 最大长度长度为 4294967295 字符。
- L+1字节 or L+2字节 的1和2表示用一个字节记录变长字符串的长度,方便读取。一个字节可以记录255以内长度,超过255使用两个字节记录长度。
eg: 定长字符串: CHAR(10) utf8(utf8mb3: 子一个字符占据三个字节 ) --> 固定字节:30字节 char(2) utf8(一个字符3个字节) -->固定字节:2*3=6个字节 变长字符串: VARCHAR(10): utf8(utf8mb3: 一个字符占据3个字节 ) --> 不是30字节 "zs" -> 2*3=6个 + 1个 = 7 VARCHAR(10): utf8mb4(utf8mb4: 一个字符占据4个字节 ) --> 不是40字节 "zs" -> 2*4=8个 + 1个 = 9 TEXT(100) : utf8(utf8mb3: 一个字符占据3个字节 ) "zs" -> 2*3=6个 + 1个 = 7
查看表
查看该数据库中所有表 SHOW TABLES; 查看表的创建语句 SHOW CREATE TABLE <表名>; 查看表结构 DESCRIBE <表名>; 查看表结构 DESC <表名>;
创建表
CREATE TABLE <表名> ( <列名1> <类型1> , […] , <列名n> <类型n> ) [表选项] [分区选项]; eg1: create table employee( id int , name varchar(20), gender char, birthday date, job varchar(20), salary double(10,2) )character set utf8 collate utf8_bin;
主键和自增问题
主键(PRIMARY KEY)又被称为’‘主键约束’'。
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在有相同主键值的两行数据。这是唯一性原则。
- 如果用户没有定义主键,也没有定义索引,那么InnoDB引擎会在创建表的时候, 自动生成一个不可见的ROW_ID的列名的聚簇索引,该列是一个6字节的自增数值,随着插入而自增, 来起到主键的作用。
主键分为单字段主键和多字段联合主键 -- 单字段主键: 既将表中的一个字段设置主键; 通过 PRIMARY KEY 关键字来指定主键. CREATE TABLE table_primary1( id INT(11) PRIMARY KEY , -- 主键 name VARCHAR(25), job VARCHAR(25),, salary FLOAT ); CREATE TABLE table_primary2( id INT(11), name VARCHAR(25), job VARCHAR(25), salary FLOAT, PRIMARY KEY(id) );自增问题 AUTO_INCREMENT
AUTO_INCREMENT 的初始值是 1,数据增加一条,该字段值自动加 1。
AUTO_INCREMENT 字段应该要设置 NOT NULL 属性。
AUTO_INCREMENT 约束的字段只能是整数类型。
AUTO_INCREMENT 上限为所约束的类型的数值上限。CREATE TABLE table_primary1( id INT(11) PRIMARY KEY AUTO_INCREMENT , -- 主键 name VARCHAR(25), job VARCHAR(25), salary FLOAT );
修改表
ALTER TABLE <表名> ADD COLUMN <列名> <类型>; # 添加列 ALTER TABLE <表名> ADD <新字段名> <数据类型> FIRST; # 头位置添加列 ALTER TABLE <表名> ADD <新字段名> <数据类型> AFTER <已经存在的字段名>; # 指定位置添加列 ALTER TABLE <表名> MODIFY COLUMN <列名> <类型>; # 修改某列类型 ALTER TABLE <表名> CHANGE COLUMN <旧列名> <新列名> <新列类型>; # 修改列及类型 ALTER TABLE <表名> ALTER COLUMN <列名> SET DEFAULT <默认值>; # 修改某列默认值 ALTER TABLE <表名> ALTER COLUMN <列名> DROP DEFAULT; # 删除某列默认值 ALTER TABLE <表名> DROP COLUMN <列名>; # 删除某列 ALTER TABLE <表名> RENAME TO <新表名>; # 修改表名 ALTER TABLE <表名> RENAME AS <新表名>; # 修改表名 ALTER TABLE <表名> RENAME <新表名>; # 修改表名 RENAME TABLE <表名> TO <新表名>; # 修改表名 ALTER TABLE <表名> CHARACTER SET <字符集名>; # 修改表字符集 ALTER TABLE <表名> COLLATE <校对规则名>; # 修改表排序规则 ALTER TABLE <表名> [DEFAULT] CHARACTER SET <字符集名> [DEFAULT] COLLATE <校对规则名>; eg: alter table employee add column height float(5,2); alter table employee add column height float(5,2) first; alter table employee add column height float(5,2) after name; alter table employee modify column age float(5, 0); alter table employee change column age age1 float(5, 0); alter table employee alter column age set default 20; alter table employee alter column age drop default; alter table employee drop column height; alter table employee rename to aaa; alter table aaa rename as employee; alter table employee rename aaa; rename table aaa to employee; alter table employee character set utf8mb4; alter table employee collate utf8mb4_unicode_ci; alter table employee character set gbk collate gbk_bin;
删除表
DROP TABLE [IF EXISTS] 表名1 [ ,表名2, 表名3 ...] eg: drop table if exists table_a, table_b, table_c;
数据操作
添加数据
- 如果values中包含数据和表列数据一一对应(列值无省略), 那么在插入语句中可以省略表名之后表列的一一列举。eg: insert into 表名 values (值1, … 值n);
- 一次添加多条数据: insert into 表名 values (值1, … 值n),(值1, … 值n),(值1, … 值n),(值1, … 值n) ;
- values中的内容应该要与对应插入字段对应。
- 数据中字符串和日期应该包含在引号中。
INSERT INTO <表名> [ (<列名1>, … <列名n> )] VALUES (值1, … 值n), … (值1, … 值n); INSERT INTO <表名> SET <列名1>=<值1>, … <列名n>=<值n>; eg: insert into employee1 (id, name, gender, graduate_year, birthday, job, salary, create_time) values(1, 'zs', '男', 2022, '1999-01-01', '程序员', 100.2, '2022-09-09 16:51:49'); insert into employee1 (id, name, gender, graduate_year, birthday, job, salary, create_time) values(1, 'zs', '男', 2022, '1999-01-01', '程序员', 100.2, '2022-09-09 16:51:49'), (2, 'ls', '男', 2020, '1997-01-01', '程序员', 10000.2, '2022-09-09 16:51:50'); insert into employee1 set id=4, name='ls', gender='男', graduate_year=2022, birthday='1999-01-01', job='程序员', salary=220.05, create_time='2022-09-09 16:55:49';
查询数据
- 查询的结果是一个新的临时表。
- 在MySQL中
select * from 表名 where 1;表示查询所有数据。SELECT * FROM <表名字> [ WHERE <条件> ]; SELECT <列名1>, …<列名n> FROM <表名字> [ WHERE <条件> ]; eg: select * from employee1; select * from employee1 where id<20; select name from employee1 where id>1; select name, job, salary from employee1 where salary> 200;
修改数据
- 注意如果没有where子句指明条件, 那么修改就是对所有行的修改。
- 修改一行数据的多个列值时,SET 子句的每个值用逗号分开即可。
UPDATE <表名> SET 列1=值1 [, 列2=值2 … ] [WHERE <条件> ] eg: update employee1 set job='老程序员'where salary >10000;
删除数据
- 如果没有where以及条件, 默认删除是表中所有数据。
- delete不能单独只删除某一列数据, delete删除数据的最小单元为行。
- delete语句仅删除数据记录, 删除的不是表, 如果要删除表需要使用drop table语句。
DELETE FROM <表名> [WHERE <条件>] ag: delete from employee; delete from employee where id=4;
特殊关键字
Where
使用 WHERE 关键字并指定
查询/删除/修改条件, 操作满足条件的数据内容。
1、算术运算符:+ - * / %SELECT <查询内容|列等> FROM <表名字> WHERE <查询条件|表达式> eg: select id, name from students where id > 10; select * from students where (chinese + english + math) < 180; select * from students where (chinese - math) > 30; select *, (chinese*0.5 + english*0.1 + math *0.4) from students; select *, (chinese*0.5 + english*0.1 + math *0.4) from students where (chinese*0.5 + english*0.1 + math *0.4) <= 60 ; select *, (chinese + english + math) /180 from students ; select *, (chinese + english + math) /180 from students where (chinese + english + math) /180 < 1.2;2、比较和逻辑运算符
运算符 作用 运算符 作用 = 等于 <=> 等于(可比较null) != 不等于 <> 不等于 < 小于 > 大于 <= 小于等于 >= 大于等于 is null 是否为null is not null 是否不为null between and 在闭区间内 in 是否在列表内 not in 不在列表内 like 通配符匹配(%:通配, _占位) and 与 && 与 or 或 || 或 注意:
like问题: 一般用来做模糊查询
_ 这个下划线也是在like中使用的通配符, 代表一个字符
这个% 代表在like通配0个到多个字符select * from students where chinese = 60; select * from students where chinese <=> 60; select * from students where chinese != 60; select * from students where chinese <=> 60; select * from students where chinese < 60; select * from students where chinese > 90; select * from students where chinese <= 60; select * from students where chinese >= 90; select * from students where chinese is null; select * from students where chinese is not null; select * from students where chinese between 60 and 90; select * from students where chinese in (60 , 90); select * from students where chinese not in (60 , 90); select * from students where name = '曹操'; select * from students where name like '曹操'; select * from students where name like '曹%'; select * from students where name like '曹%' and chinese = 90; select * from students where name like '曹%' && chinese = 90; select * from students where name like '曹%' or chinese = 90; select * from students where name like '曹%' || chinese = 90;
Distinct
使用
DISTINCT对数据表中一个或多个字段重复的数据进行过滤,重复的数据只返回其一条数据给用户.SELECT DISTINCT <字段名> FROM <表名>; eg: select distinct chinese from students; select distinct chinese, english from students;注意:
– DISTINCT 只能在SELECT语句中使用 (对select的查询结果做去重处理)。
– 当对一个或多个字段去重时,DISTINCT 要写在所有字段的最前面。
– 如果 DISTINCT 对多个字段去重时,只有多个字段组合起来完全是一样的情况下才会被去重。
Limit
使用
LIMIT对数据表查询结果集大小进行限定.
- 数据(默认下标从0开始)
- LIMIT 记录数目: 从第一条开始, 限定记录数目
- LIMIT 初始位置,记录数目: 从起始位置开始, 限定记录数目
- LIMIT 记录数目 OFFSET 初始位置: 从起始位置开始, 限定记录数目
SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目 SELECT <查询内容|列等> FROM <表名字> LIMIT 初始位置,记录数目; SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目 OFFSET 初始位置; eg: select * from students limit 3; select * from students limit 4, 3; select * from students limit 3 offset 4;
As
AS关键字用来为表和字段指定别名.<内容> AS <别名> eg: select name from students; select * from students as s where s.chinese < 60; select s.name from students as s ; select s.name from students as s where s.chinese < 60; select name as username from students; select * from students; select *, (chinese + english + math) from students; select *, (chinese + english + math) as sum from students;
Order By
ORDER BY对查询数据结果集进行排序.
- ASC: 升序排序(默认排序规则)
- DESC: 降序排序.
- 当进行多字段排序的时候, 会先满足第一个列的排序要求, 如果第一列一致的话, 再按照第二列进行排序, 以此类推.
SELECT <查询内容|列等> FROM <表名字> ORDER BY <字段名> [ASC|DESC]; eg: select * from students order by chinese; select * from students order by chinese asc; select * from students order by chinese desc; select * from students order by chinese, english; select * from students order by chinese desc, english desc, math desc;
Group By
使用
GROUP BY关键字,对数据进行分组
- 单独使用 GROUP BY 关键字时,查询结果会只显示每个分组的第一条记录。旧版本可以select * from students group by class 产生结果, 结果是每个分组的第一条数据
- 多个字段分组查询时,会先按照第一个字段进行划分组。按照第一个字段划分组之后,再组内按照第二个字段进行划分组。
GROUP_CONCAT()函数会把每个分组的字段值都拼接显示出来HAVING可以对分组后的各组数据过滤 (分组的条件, 专门给分组用的, 相当于给分组一个where条件,一般和分组+聚合函数配合使用)SELECT <查询内容|列等> FROM <表名字> GROUP BY <字段名...> eg: select class, group_concat(name), group_concat(chinese) from students group by class; select class, group_concat(name) from students where chinese > 90 group by class; select class, group_concat(name), avg(chinese) from students group by class; select class, group_concat(name) from students group by class having count(*) > 3; select class, group_concat(name), avg(chinese) from students group by class having avg(chinese) > 60;
聚合函数
聚合函数一般用来计算列相关的指定值.
通常和分组一起使用
函数 作用 函数 作用 COUNT 计数 SUM 和 AVG 平均值 MAX 最大值 MIN 最小值
COUNT: 计数
- COUNT(*): 表示表中总行数
- COUNT(列): 计算除了列值为NULL以外的总行数
SELECT <查询内容|列等> , COUNT <列|*> FROM <表名字> GROUP BY HAVING COUNT <表达式|条件> eg: select count(*) from students select count(name) from students select class, group_concat(name), count(*) from students group by class; select class, group_concat(name), count(*) from students group by class having count(*) > 2;
SUM: 求和SELECT <查询内容|列等> , SUM<列> FROM <表名字> GROUP BY HAVING SUM<表达式|条件> eg: select sum(chinese) from students; select sum(chinese), sum(english), sum(math) from students; select class, group_concat(name), sum(chinese) from students group by class; select class, group_concat(name), sum(chinese) from students group by class having sum(chinese)>200; select class, group_concat(name), sum(chinese), sum(math) from students group by class; select class, group_concat(name), sum(chinese), sum(math) from students group by class having sum(chinese)>200 and sum(math) > 200;
AVG: 平均值SELECT <查询内容|列等> , AVG<列> FROM <表名字> GROUP BY HAVING AVG<表达式|条件> eg: select avg(chinese) from students; select avg(chinese), avg(english), avg(math) from students; select class, group_concat(name), avg(chinese) from students group by class; select class, group_concat(name), avg(chinese) from students group by class having avg(chinese)>=60; select class, group_concat(name), avg(chinese), avg(math) from students group by class; select class, group_concat(name), avg(chinese), avg(math) from students group by class having avg(chinese)>=60 and avg(math) >=60;
MAX: 最大值SELECT <查询内容|列等> , MAX<列> FROM <表名字> GROUP BY HAVING MAX<表达式|条件> eg: select max(chinese) from students; select max(chinese), max(english), max(math) from students; select class, group_concat(name), max(chinese) from students group by class; select class, group_concat(name), max(chinese) from students group by class having max(chinese)>90; select class, group_concat(name), max(chinese), max(math) from students group by class; select class, group_concat(name), max(chinese), max(math) from students group by class having max(chinese)>=90 and max(math) >=70;
MIN: 最小值SELECT <查询内容|列等> , MIN<列> FROM <表名字> GROUP BY HAVING MIN<表达式|条件> eg: select min(chinese) from students; select min(chinese), min(english), max(math) from students; select class, group_concat(name), min(chinese) from students group by class; select class, group_concat(name), min(chinese) from students group by class having min(chinese)>60; select class, group_concat(name), min(chinese), min(math) from students group by class; select class, group_concat(name), min(chinese), min(math) from students group by class having min(chinese)>=60 and min(math) >=60;
SQL执行顺序
- 小括号中的数字代表执行顺序
- having和select的执行顺序收到优化器(数据库服务, 会对我们写的sql代码, 先检测语法, 优化编译, 执行)的影响,可能会改变执行顺序
(5) SELECT column_name, ... (1) FROM table_name, ... (2) [WHERE ...] (3) [GROUP BY ...] (4) [HAVING ...] (6) [ORDER BY ...]; (7) [Limit ...] eg: select class, group_concat(name), avg(chinese) as chineseA, avg(math) from students where chinese >= 60 group by class having avg(math)>=40 order by chineseA desc limit 0, 1;
数据库中表和数据的设计规范:数据完整性
在数据库表和数据的设计中,数据完整性(Data Integrity)是一个非常重要的方面。
按照数据完整性对数据库中的表和数据进行设计,可以有效地提高数据库的数据质量和可靠性,避免数据损坏、丢失或不一致的情况。同时,良好的数据完整性设计也有助于提高数据库查询性能和安全性。
数据完整性通常包括以下几个方面:
实体完整性
保证
表中的每一行数据都是表中唯一的实体。确保表中的每一行都具有唯一标识符,并防止重复数据的出现。可以通过设置主键或唯一约束来实现实体完整性。CREATE TABLE `students` ( `id` int(11) PRIMARY KEY AUTO_INCREMENT, `name` varchar(255) , `class` varchar(255) , `chinese` float , `english` float , `math` float ) ;
PRIMARY KEY
域完整性/属性完整性
指确保每一列中的数据符合指定的数据类型、约束条件和默认值。可以通过设置数据类型、检查约束、默认值等属性来实现属性完整性。
域完整性表示保证表中数据的字段的取值在有效范围之内或者符合特定的数据类型约束CREATE TABLE `students` ( `id` int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT, `name` varchar(10) NOT NULL DEFAULT "张飞", `class` varchar(5) NULL DEFAULT NULL, `chinese` float NOT NULL, `english` float NOT NULL, `math` float NOT NULL );
float,varchar,NULL,NOT NULL
参照完整性
确保表与表之间的关联关系有效和正确,防止无效的外键值。可以通过设置外键约束来实现参照完整性。
参照完整性用于确保相关联的表间的数据应该要保持一致
避免因为一个表的数据/记录修改, 造成另一个表的内容变为无效的值. 一般来讲, 参照完整性是通过外键和主键来维护的.CREATE TABLE `class` ( `id` int NOT NULL PRIMARY KEY, `name` varchar(255) NULL ); INSERT INTO `class` (`id`, `name`) VALUES (1, '一班'); INSERT INTO `class` (`id`, `name`) VALUES (2, '二班'); INSERT INTO `class` (`id`, `name`) VALUES (3, '三班'); alter table `students` add column `class_id` int null after `math`, add constraint `班级` foreign key (`class_id`) references `class` (`id`); -- CONSTRAINT 外键名 FOREIGN KEY(要作为外键字段名) REFERENCES 主表名(主表中关联的字段); -- ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>;删除外键
FOREIGN KEY
外键 优缺点
- 优点:能够限制数据的增加、删除或者是修改操作,来保证数据的一致性。
- 缺点:
- 在插入/修改子表(student)的数据的时候,需要去父表(class)中找对应的数据
- 在删除/修改父表(class)的数据的时候,需要去检查子表(student)中是否有对应的数据
- 有了外键之后,影响了增加、删除、修改的性能
在公司中,大家觉得应不应该使用外键呢?看具体的情况 1. 假如公司表中的数据量不大(外键对效率的影响比较小,甚至可以忽略),可以考虑使用外键 2. 假如公司数据库表中的数据很多,(外键对于效率的影响就会很大),不应该使用外键 3. 人为使用习惯
用户定义规则
指根据特定业务需求设定的数据管理规则,这些规则可以通过触发器、存储过程或函数等方式实现。
多表设计/多表理论
一对一
指两个表(或多个表之间)的数据存在一一对应的关系。
所有的一一对应的表(一对一情况),在逻辑上,都可以合并为一个表。eg: 用户和用户详情 商品和商品详情 IP表和电脑表
一对多
指两个表(或多个表之间)的数据,存在表A中的一条数据对应表B中的多条数据,表B中的一条数据对应表A中的一条数据.
eg: 用户和订单 班级和学生
多对多
存在两个表表A和表B,存在表A中的一条数据对应表B中的多条数据,表B中的一条数据对应表A中的多条数据。
eg: 订单和商品 一个产品中可能有多个订单, 一个订单中可能买了多个商品 剧本和演员 一个演员可能出演了多个剧本, 一个剧本中可能包含多个演员
数据库设计范式
数据库设计范式(Normalization)是一种常用的关系型数据库设计方法,主要是为了规范数据库中的表和列之间的关系,提高数据存储和查询的效率、可靠性和灵活性。
数据完整性谈的是整个数据库的数据设计的相关规范;而数据库设计范式, 谈的是表设计的一些规范.
目前,常见的数据库设计范式主要有以下几个:
第一范式(1NF): 原子性
每列(属性)应该保持原子性。每个属性不能再分解成更小的数据项。如果数据库中的所有字段都是不可分割的原子值,则说明该数据库满足第一范式。
eg:地址 不满足原子性,可以再分割 address:“河南省信阳市固始县” 满足原子性 Province:“河南省”, City:“信阳市”, County:“固始县”第一范式:我们在设计表的时候,应该考虑之后业务的变化,来尽量让每一列的数据保持原子性。
第二范式(2NF): 唯一性
数据的唯一性。 要求表中数据有唯一标识,不存在部分依赖
确保数据表中的每个非主属性都完全依赖于主键,也就是每个非主属性必须依赖于主键才能存在。eg: 通过name+nickname+province+city+county组合标识一个用户(不满足唯一性) 通过id唯一标识一个用户(满足唯一性) id int(10) primary key
第三范式(3NF): 不冗余
字段不要冗余。在满足第二范式的基础上,排除了非主属性对其他非主属性的传递依赖,也就是不存在冗余字段的情况。
eg: dept表中存储了部门名称dname create table dept( id int(10) primary key, dname varchar(10) ); emp表中也存储了部门名称dname create table emp( id int(10) primary key, deptno int(10) dname varchar(10) );
巴斯-科德范式(BCNF)
在满足第三范式的基础上,排除了主键对其他非主属性的部分函数依赖。
多表查询
交叉链接
交叉连接其实就是求多个表的笛卡尔积。
- 两个表的笛卡尔积,返回结果数量就是两个表的数据行相乘。
- 如果每个表有1000行,那么返回结果的数量就有1000×1000=1000000行。
SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句] SELECT <字段名> FROM <表1>, <表2> [WHERE子句] eg: select * from t_stu cross join t_staff; select * from students cross join equip where students.id = equip.user_id;
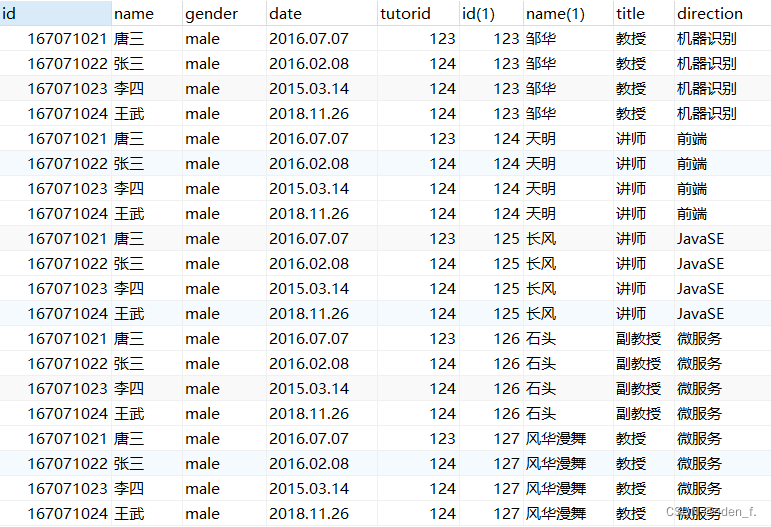
自然连接
自然连接用处不是很大
- 自然连接是基于两个表之间的共同列来自动匹配并组合数据。
- 自然连接将结果集限制为只包括两个表中
具有相同值的列(并且在结果集中把重复的列去掉)。在使用自然连接时,不需要指定连接条件,而是根据两个表中具有相同名称和数据类型的列进行匹配。 (注意: 有些数据库不支持自然连接, 比如SQLServer )eg: 相同的class属性 select * from students natural join class
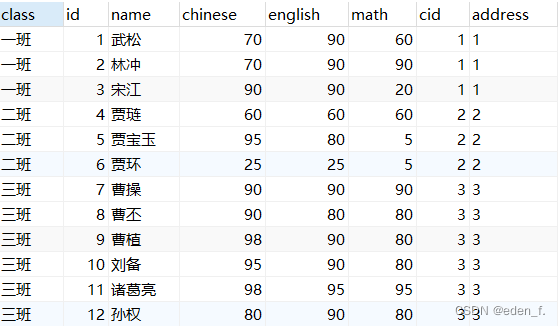
内连接: 必须会用
内连接SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句] eg: -- 显示内连接 select * from students inner join equip on students.id = equip.user_id; -- 隐式内连接 select * from students , equip where students.id = equip.user_id;
外连接: 左右外连接: 必须会用
外连接SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2> <ON子句> SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2> <ON子句> eg: select * from students left outer join equip on students.id = equip.user_id; select * from students right outer join equip on students.id = equip.user_id; select * from equip right outer join students on students.id = equip.user_id; select * from equip left outer join students on students.id = equip.user_id; -- outer可省略 select * from students left join equip on students.id = equip.user_id; select * from students right join equip on students.id = equip.user_id;注: 主副表的问题
假设A和B表进行连接,AB两张表一个表示主表,另一个是副表; 查询数据的时候, 以主表中的数据为基准,匹配副表对应的数据; 当副表中的数据没有能和主表对应数据相互匹配的数据,副表匹配位置自动填充null。
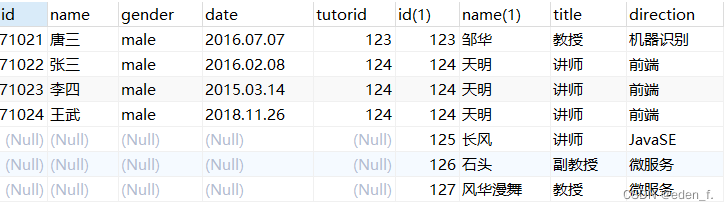
自连接
自连接
自连接是指在同一个表中,使用不同的别名将它们连接到一起。eg: select t1.* from students t1,students t2 where t2.name='刘备' and t1.chinese < t2.chinese
子查询: 必须会用
子查询也叫嵌套查询.( 在某个操作中(删除/添加/查找), 用到了另外一个查询的结果. )
是指在WHERE子句或FROM子句中又嵌入SELECT查询语句.
SELECT <字段名> FROM <表|子查询> WHERE <IN| NOT IN | EXISTS | NOT EXISTS > <子查询> eg: select * from students where id in (select user_id from equip); select * from students where id not in (select user_id from equip where user_id != ""); select * from students where exists (select * from equip where user_id = 10); select * from students where not exists (select * from equip where user_id = 10); select * from students where exists (select * from equip where user_id = 10) and id = 11; -- 在MySQL每次查询数据的结果集都是一个新的临时表。
联合查询
联合查询合并两条查询语句的查询结果.
联合查询去掉两条查询语句中的重复数据行,然后返合并后没有重复数据行的查询结果。SELECT <字段名> FROM <表> UNION SELECT <字段名> FROM <表> eg: select * from students where chinese >= 90 union select * from students where math >= 90;
数据库备份和恢复
命令行操作
通过命令行操作
-- 数据库备份:cmd命令下 mysqldump -u root -p 数据库名称>文件名.sql -- tips: 文件不建议放到c盘,不然可能由于权限问题无法访问 -- 数据库恢复: -- 1. 创建数据库并选择该数据库 create database dbName; use dbName; -- 2. 恢复数据 source 文件名.sql


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









