







爬取某新闻
- 1 了解ajax加载
- 2 通过chrome的开发者工具,监控网络请求,并分析
- 3 用selenium完成爬虫
- 4 具体流程如下:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://news.qq.com/')
两秒垂直滚动一次
for i in range(1,100):
time.sleep(2)
driver.execute_script("window.scrollTo(window.scrollX, %d);"%(i*200))
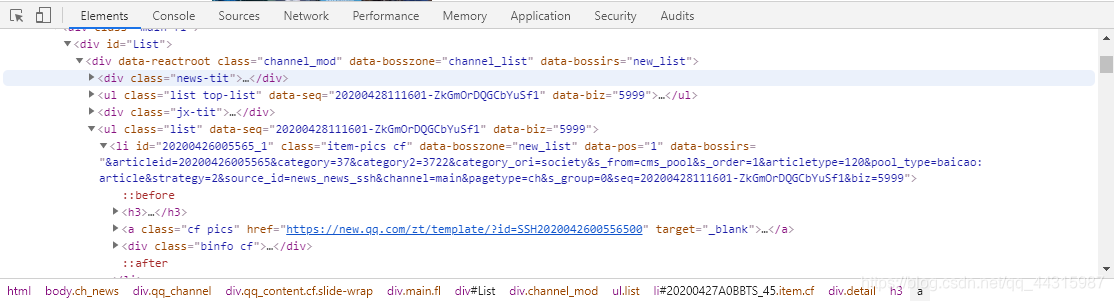
利用xpath定位标签(其中data-biz每天会变,如果爬出来为空的话记得修改xpath):
html=driver.page_source
from lxml import etree
tree = etree.HTML(html)
content = tree.xpath('//ul[@data-biz="5999"]/li') # data-biz每天会变
结果就不展示了,大家可以输出看看
for k, i in enumerate(content):
try:
url = i.xpath('./div/h3/a/@href')[0]
title = i.xpath('./div/h3/a/text()')[0]
print('序号:%d title:%s url:%s' % (k, title, url))
except:
url = i.xpath('./h3/a/@href')[0]
title = i.xpath('./h3/a/text()')[0]
print('序号:%d title:%s url:%s' % (k, title, url))
driver.close() # 关闭浏览器一个Tab
# or
driver.quit() # 关闭浏览器窗口














 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









