 Kafka集群搭建与配置
Kafka集群搭建与配置




Zookeeper kafka集群搭建
安装zookeeper
1. 解压后,修改名称为zookeeper
tar -xZvf filename
2. 下载java jdk 因为 zookeeper需要依赖他运行
yum install -y java-1.8.0-openjdk
java -version
3.创建配置文件
mkdir data logs
cp conf/zoo_sample.cfg conf/zoo.cfg
4.修改配置文件zoo.cfg
这里的格式(server.n=A:B:C),n服务器编号,可随便起,别重复就行(myid文件会用到此值),A表示服务器IP,B表示follower与leader通信的端口,C表示Leader选举端口
4.1 第一个节点(IP1的zookeeper)
dataDir=/root/zookeeper/data
clientPort=2181
- 以下代码在所有配置中都一样
server.1=IP1:PORT1:PORT2
server.2=IP1:PORT3:PORT4
server.3=IP2:PORT1:PORT2
4.2 第二个节点(IP1的zookeeper3)
cp -r dir1 dir2 //完整复制
dataDir=/root/dir2/data //注意地址修改
clientPort=2182 //要不一样的端口
- 以下代码在所有配置中都一样
server.1=IP1:PORT1:PORT2
server.2=IP1:PORT3:PORT4
server.3=IP2:PORT1:PORT2
4.3 第三个节点(IP2的zookeeper)
dataDir=/root/zookeeper/data //注意地址修改
clientPort=2181
- 以下代码在所有配置中都一样
server.1=IP1:PORT1:PORT2
server.2=IP1:PORT3:PORT4
server.3=IP2:PORT1:PORT2
5. 在新建的data文件夹里,新建myid文件,根据server的输入对号入座,写入一个数字
6.启动/停止/查看状态
看谁是follower和leader
bin/zkServer.sh stop
bin/zkServer.sh start
bin/zkServer.sh status
- 【error】Error contacting service. It is probably not running.
- 互相ping通
- 如果出现no route 就关闭两个机器的防火墙
- zookeeper必须至少三个节点
- 按myid从小到大依次重启zk机器
telnet ip 端口
systemctl stop firewalld
firewall-cmd --state

7.进入远程连接
- 远程连接,
bin/zkCli.sh -server 127.0.0.1:2181 - 看到所有节点
ls -s / quit可以退出连接,close就是关闭连接- create 节点名称 节点内容
create /a2 "aa bb cc" get /a1或者get -s /a1可以看到节点内容delete 节点路径只针对没有子节点的空节点stat 节点路径查看节点状态ls /brokers/ids查看有没有ids 然后get /brokers/ids/0get /controller- 配置用户名密码
getAcl /
addauth digest {account}:{password}
当kafka启动不成功,如果是broker/ids/0残留,先删除log-dir文件,然后delele /brokers/ids/0
安装kafka
kafka配置文件解读
kafka消费者配置文件详解(包含异步offset提交/重复消费等)
server.properties文件
broker.id=1
//列出kafka监听的URI列表
listeners=PLAINTEXT://0.0.0.0:9092
//对zookeeper发布的监听器
advertised.listeners=PLAINTEXT://172.16.3.2:9092
############################# Log Basics #############################
// log日志存储的目录,逗号分隔的多个路径,建议每个目录挂载到不同的磁盘上,能够提升读写性能,并且在1.1版本以及上可以支持故障转移
log.dirs=/data/kafka/data
//topic的默认分区数
num.partitions=3
//在kafka重启恢复数据时使用的线程数,默认值为1
num.recovery.threads.per.data.dir=2
// 默认的副本数量
default.replication.factor=3
//默认的分区数量
num.partitions=3
//定义数据的清理策略
//设置数据的保存时间
log.retention.hours=168
//限制在broker中保存的数据量,默认值为-1,不做限制
log.retention.bytes=1073741824
// 指定zookeeper的连接地址
zookeeper.connect=hostname-1:2181,hostname-2:2181,hostname-3:2181
//等待zookeeper连接的超时时间
zookeeper.connection.timeout.ms=6000
//是否自动创建topic,目前没有需要自动创建topic的场景,设置为false,便于管理topic
auto.create.topics.enable=false
//当acks设置为all或者-1时,这个配置将规定消息写入节点的数量,如果没有达到指定的数量,生产者将会收到一个exception
min.insync.replicas=2
//不允许不在ISR列表的副本节点选举为leader,否则可能导致数据丢失
unclean.leader.election.enable=false
//默认值为true,会定期自动对leader partition进行重新选举,进行不必要的消耗。
auto.leader.rebalance.enable=false
//broker能够接受消息的最大字节数,默认值为1000012字节,在低于0.10.2的版本中需要对应修改消费者的fetch size,允许消费者能够拉取数据
message.max.bytes=5242880
//要大于message.max.bytes的配置,否则broker之间无法同步数据
replica.fetch.max.bytes=10485760
log4j.properties文件,修改日志级别
# Change the line below to adjust ZK client logging
log4j.logger.org.apache.zookeeper=ERROR
# Change the two lines below to adjust the general broker logging level (output to server.log and stdout)
log4j.logger.kafka=ERROR
log4j.logger.org.apache.kafka=ERROR
# Change to DEBUG or TRACE to enable request logging
log4j.logger.kafka.request.logger=WARN, requestAppender
log4j.additivity.kafka.request.logger=false
# Uncomment the lines below and change log4j.logger.kafka.network.RequestChannel$ to TRACE for additional output
# related to the handling of requests
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.network.RequestChannel$=WARN, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
log4j.logger.kafka.controller=ERROR, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.kafka.log.LogCleaner=ERROR, cleanerAppender
log4j.additivity.kafka.log.LogCleaner=false
log4j.logger.state.change.logger=ERROR, stateChangeAppender
log4j.additivity.state.change.logger=false
# Access denials are logged at INFO level, change to DEBUG to also log allowed accesses
log4j.logger.kafka.authorizer.logger=ERROR, authorizerAppender
log4j.additivity.kafka.authorizer.logger=false
1. 解压
tar -xvf filename
2. 修改配置文件
ip需要和config/server.properties的保持一致
listeners = PLAINTEXT://IP:9092
advertised.listeners=PLAINTEXT://IP:9092
broker.id=1
log.dirs=/root/kafka/kafka-logs2
zookeeper.connect=10.19.200.151:2181,10.19.200.151:2182,10.19.200.152:2181
-
num.partitions=1,则主题的分区partitions数量将被限制为 1,而不会受到创建主题时指定的partitions分区数量的影响
-
也可以从kafka启动 zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties &三台机器都执行启动命令,查看zookeeper的日志文件,没有报错就说明zookeeper集群启动成功了。 -
防火墙配置(我现在是直接关了)
填上自己的zookeeper集群地址,保存完后就是开放端口了,记得三台服务器都要配置,
不同点在于 broker.id(每台机器的kafka id是唯一的,比如三台分别为1,2,3,host.name,listeners填上对应的虚拟机IP地址)
这里唯一开放的端口号就是9092
firewall-cmd --zone=public --add-port=2888/tcp --permanent
firewall-cmd --zone=public --add-port=2888/tcp --permanent
firewall-cmd --reload
firewall-cmd --list-all -
Zookeeper本身的Bug: FastLeaderElection - leader ignores the round information when joining a quorum
QuorumCnxManager@513] - Have smaller server identifier, so dropping the connection: (myId:2 --> sid:3)
4. 增加一个名为test的topic(ip需要和config/server.properties的保持一致)
bin/kafka-topics.sh --create --zookeeper IP:ZOOKEEPER的端口 --topic test --partitions 1 --replication-factor 1
删除topic
kafka-topics.sh --bootstrap-server ip:9092 --delete --topic t1
彻底删除topic: rmr /brokers/topics/【topic name】
删除topic,慎用,只会删除zookeeper中的元数据,消息文件须手动删除
-
--replication-factor
表示每个分区的数据应该被复制到多少个 Kafka brokers 中。在 Kafka 中,数据的持久性是通过数据的副本来实现的,每个分区的数据都会被复制到副本所在的多个 broker 上,以确保数据的高可用性和容错性。 -
如何确认分别复制在哪些broker上了?或者说如何指定区域复制?
如何确认分别复制在哪些broker上了?可以用查看topic的命令查看。
比如这里就是创建了一个叫做“test”的主题,他有1个分区,每个分区只有一个备份(其实就是分区本身)
消息是追加到分区的,所以多个分区顺序写磁盘(轮询策略)的总效率甚至比其他消息中间件随机写内存还要高,这也是Kafka高吞吐率的原因
在 Kafka 中,创建副本(replicas)时通常无法直接指定具体的 Broker。Kafka 会根据副本的分配策略(通常是基于副本的数量和分区的复制因子)自动将副本分配给适当的 Broker。
这种自动分配副本的方式有助于实现负载均衡和数据冗余。
5. 为topic划分更多分区partition(ip需要和config/server.properties的保持一致)
bin/kafka-topics.sh --zookeeper IP:ZOOKEEPER的端口 --alter --topic test --partitions 4
- 注意
端口号2181不是9092
6. 查看已创建的topic信息(ip需要和config/server.properties的保持一致)
bin/kafka-topics.sh --bootstrap-server ip:9092 --list
- 注意要写
ip而不是localhost,要保持一致否则报错
[2024-05-29 15:49:41,438] WARN [AdminClient clientId=adminclient-1] Connection to node -1 (localhost/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) - 注意
端口号9092不是2181 - 注意
--list放最后
7. 启动/关闭 kafka
bin/kafka-server-start.sh config/server.properties
bin/kafka-server-stop.sh
Broker 的 启动过程
Broker启动后先根据其ID在Zookeeper的 /brokers/ids/ids znode 下面创建临时子节点,
创建成功后 Contrller 的 ReplicaStateMachine 注册其上的 Broker Change Watch 会被触发, 从而通过回调 KafkaController.onBrokerStartup 方法,回调方法向所有新启动的Broker发送 UpdateMetadataRequest。
将新启动的 Broker上的所有副本设置为 OnlineReplica 状态, 同时这些Broker会为这些Partition 启动high watermark线程。通过partitionStateMachine 触发OnlinePartitionStateChange。
kafka和zookeeper 的关系
如果单个主机需要运行多个zookeeper的节点,需要把安装包复制。
如果单个主机需要运行多个kafka的broker,不需要把安装包复制,只需要添加
①新的server2.properties ②新的log-dir目录(新建文件夹)
broker.id=1
log.dirs=/root/kafka/kafka-logs2
zookeeper.connect=10.19.200.151:2181,10.19.200.151:2182,10.19.200.152:2181
- meta.properties 在配置文件log-dir的目录里,不需要特地修改
Partition 和 Broker 的 Leader 选举
Kafka Controller (控制器)(Broker)
Kafka 集群中会有一个或者多个Broker,有一个Broker会被选举为控制器 (Kafka Controller),它负责整个集群中所有分区和副本的状态。
- 选择Partition Leader(Partition选举) : 当某个分区副本出现故障时, 由Kafka Controller负责为该分区选举新的leader副本。
- 更新元数据 : 从Zookeeper中获取当前所有topic、 partition以及Broker相关信息进行相应的管理。
- 增/减/分配分区 : 当使用kafka-topics.sh 脚本为某个topic增加分区数量时, 同样还是由KafkaController负责新增分区的分配
- 选举过程
每个Broker在启动的时候都会去尝试读取 /controller 节点的brokerid的值get /controller ,如果ZK中不存在 /controller 节点, 或者这个节点值为 -1, 那么会尝试去创建 /controller 节点,在去创建 /controller 节点的时候,也有可能其他的broker同时尝试创建这个节点,只有创建成功的broker会成为控制器, 创建失败的则意味着竞选失败会在 /controller 上注册一个Watch。
如果读取到brokerid的值 不为-1, 则表示已经有其他broker节点成功竞选为控制器, 则该broker就会放弃竞选,并且会在 /controller 上注册一个Watch。
当Contoller挂掉时临时节点会自动消失, 这时Watch会被触发, 此时所有active的Broker都会去竞选成为新的Controller。
每个broker都会在内存中保存当前控制器的brokerid的值,这个值标识activeControllerId。
当/controller数据发生变化时,每个broker都会更新自身内存中保存activeControllerId。如果broker在数据变更前是控制器, 那么如果在数据变更后自身的brokerid值与新的activeControllerId值不一致的话,那么就需要"退位",关闭相应的资源,比如关闭状态机、注销相应的监听器等。有可能控制器由于异常而下线,造成/controller 这个临时节点会被自动删除;也有可能是其他原因将此节点删除了。
当/controller节点被删除时, 每个broker都会进行选举,如果broker在节点被删除前是控制器的话,在选举前还需要有一个"退位"的动作。如果有特殊需要,可以手动删除/controller节点来触发新一轮的选举。当然关闭控制器所对应的broker以及手动向/controller节点写入新的brokerid的所对应的数据同样可以触发新一轮的选举。
- /controller epoch 节点
get /controller epoch 节点是一个 持久化节点,它保存的是一个整型的controller epoch值。这个值用于记录控制器发生变更的次数。即记录当前的控制器是第几代控制器,当控制器发生变更时,每选出一个新的控制器都会在该值的基础上+1,每个和控制器交互的请求都会携带上controller epoch的值。
如果请求的 controller epoch 值小于内存中 controller epoch 的值, 则认为这个请求是向已经过期的控制器发送的请求,那么这个请求会被认定为无效请求。
如果请求的 contoller epoch 值大于内存中 contrller epoch 的值, 则说明已经有新的控制器当选了。由此可见, kafka通过contrller epoch 来保证控制器的唯一性, 进而保证相关操作的一致性。
Controller 选举成功后的操作
Broker成功竞选为Controller 后会触发 KafkaController.onControllerFailover 方法, 并在该方法中完成如下操作:
- 读取并在 /controller epoch 的值基础上+1。
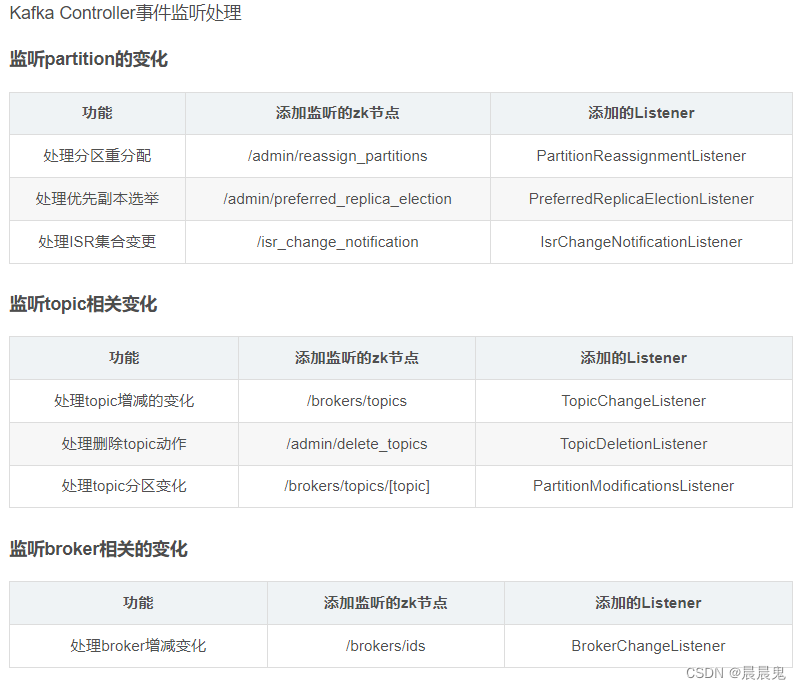
- 增加一系列监听用于处理集群环境的变化, 具体有哪些监听可以查看 Controller 事件监听章节。
- 初始化 Controller对象, 设置当前所有Topic、 Broker列表、 Partition的Leader以及ISR等
- 启动 replicaStateMachine 和 partitionStateMachine
- 将brokerState 状态设置为 partitionStateMachine
- 将每个Partition的Leadership 发送给所有active 的Broker
- 若auto.leader.rebalance.enable设置为true,则还会开启一个名为"auto-leader-rebalance-task"的
定时任务来负责维护分区的有限副本的均衡。 - 如果delete.topic.enable值为true, 且/admin/delete topics中有值, 则删除对应的topic
Controller 事件监听
在Kafka的早期版本中,并没有采用Kafka Controller这样一个概念来对分区和副本的状态进行管理,而是依赖于Zookeeper, 每个broker都会在Zookeeper上为分区和副本注册大量的监听器
(Watcher)。当分区或者副本状态变化时,会唤醒很多不必要的监听器,这种严重依赖于Zookeeper的设计会有脑裂、羊群效应以及造成Zookeeper过载的隐患。
羊群效应是指所有的客户端都尝试对一个临时节点去加锁,当一个锁被占有的时候,其他的客户端都会监听这个临时节点。一旦锁被释放,Zookeeper反向通知添加监听的客户。
在目前的新版本的设计中,只有Kafka Controller在Zookeeper上注册相应的监听器,其他的broker极少需要再监听Zookeeper中的数据变化,这样省去了很多不必要的麻烦。不过每个broker还是会对/controller节点添加监听器的,以此来监听此节点的数据变化(参考ZkClient中的IZkDataListener)。
控制器在选举成功之后会读取Zookeeper中各个节点的数据来初始化上下文信息
(ControllerContext),并且也需要管理这些上下文信息,比如为某个topic增加了若干个分区,控制器在负责创建这些分区的同时也要更新上下文信息,并且也需要将这些变更信息同步到其他普通的broker节点中。不管是监听器触发的事件,还是定时任务触发的事件,亦或者是其他事件(比如ControlledShutdown)都会读取或者更新控制器中的上下文信息,那么这样就会涉及到多线程间的同步,如果单纯的使用锁机制来实现,那么整体的性能也会大打折扣。
针对这一现象,Kafka的控制器使用单线程基于事件队列的模型,将每个事件都做一层封装,然后按照事件发生的先后顺序暂存到LinkedBlockingQueue中, 然后使用一个专用的线程 (ControllerEventThread) 按照先入先出顺序处理各个事件,这样可以不需要锁机制就可以在多线程间维护线程安全。
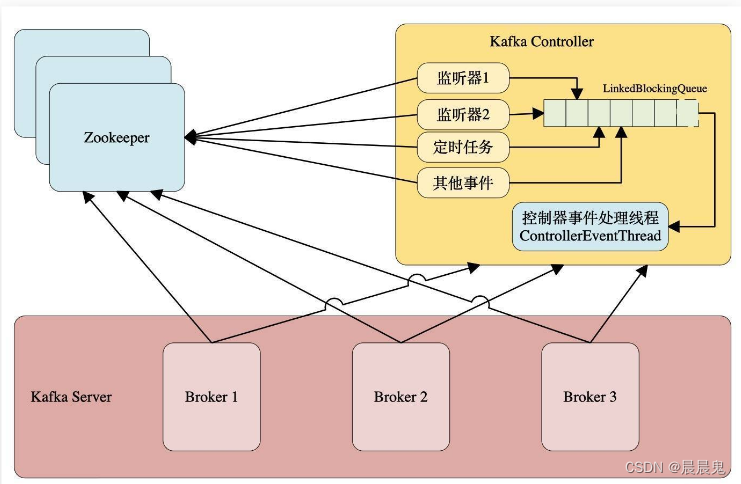
- Broker 响应请求的流程
Broker 通过 kafka.network.SocketServer及其相关模块接受各种请求并作出相应,整个网络通信模块基于Java NIO 开发,并采用 Reactor模式,其中包括1个Acceptor负责接受客户请求, N个Processor负责读写数据, M个Handle 处理业务逻辑。
Acceptor:主要负责监听并接受客户端发送的请求, 包括Producer、Consumer、Controller、Admin、Tool 等的请求,并建立和客户端的数据传输通道,然后为该客户端指定一个 Processor,至此它对该客户端的该次请求的任务就结束了,可以去响应下一个客户端的连接请求了。
Processor:主要负责从客户端读取数据并将响应返回给客户端,它本身并不处理具体的业务逻辑,并且其内部维护了一个队列来保存分配给它的所有 SocketChannel。
Processor 会循环调用run方法从队列中取出新的SocketChannel,并将其SelectionKey.OP READ 注册到selector 上,然后循环处理已就绪的读(请求)和写(响应)。Processor读完数据之后,将其封装成 Request对象,并将其交给RequestChannel。
RequestChannel 是Processor 和KafkaRequestHandler 交换数据的地方,它包含一个队列,requestQueue用来存放Processor 加入 Request 。Processor 会通过prosessNewReponses 方法依次将 requestChannel 中的ResponseQueue保存的Response取出,将其对应的SelectionKey.OP WRITE事件注册到selector 上。当selector的select 方法返回时,对检测到的可写通道,调用write方法,将Response返回给客户端。
Handler: KafkaRequestHandler 循环送 RequestChannel 中读取Request 并交给kafka.server.kafkaAPIs 处理具体业务逻辑。同时 这个Request还包含一个respondQueue,用来存放KafkaRequestHandler处理完Request后返还给客户端的Response.
Kafka 的 leader 选举(Partition)主要是为了保证数据的一致性和可用性,而 Zookeeper 的 leader 选举(Broker)是为了保证整个 Zookeeper 集群的一致性和可靠性。
Partition 中的 Leader:
在 Kafka 中,每个分区(partition)都有一个 leader 副本,负责处理该分区的读写请求。
- 当生产者发送消息到某个分区时,消息会被写入该分区的 leader 副本,然后再由 leader 副本负责将消息复制到其他副本。
- 如果 Kafka Broker 挂掉或出现故障,会触发 leader 选举机制,在副本列表中选择一个新的 leader 副本来接管分区的读写操作。
Zookeeper 中的 Leader:
Zookeeper 是 Kafka 集群中的一个关键组件,用于协调和管理 Kafka 集群的状态信息,比如 broker、topic、partition 的元数据信息等。
- 在 Zookeeper 中也存在一个 Leader,负责领导 Zookeeper 集群的状态同步和选举过程。
- 当 Zookeeper 集群中的 Leader 节点挂掉或出现故障时,会触发新一轮的 Leader 选举,选出一个新的 Leader 来继续领导 Zookeeper 集群。
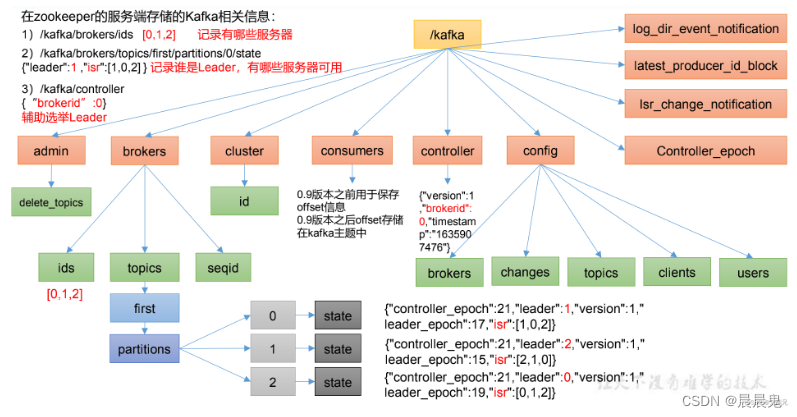
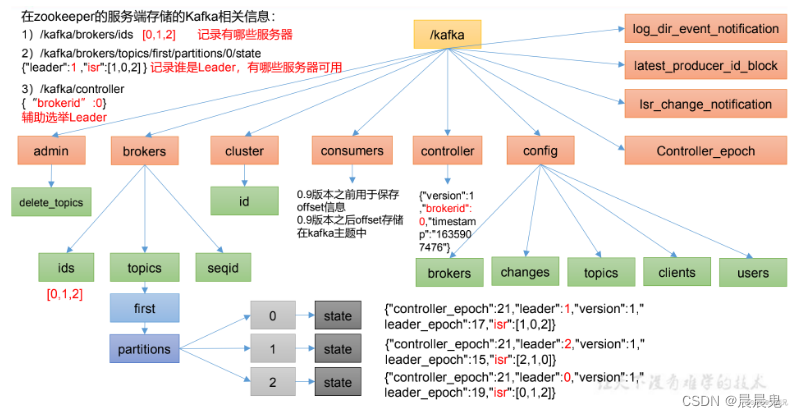
kafka和zookeeper的存储结构
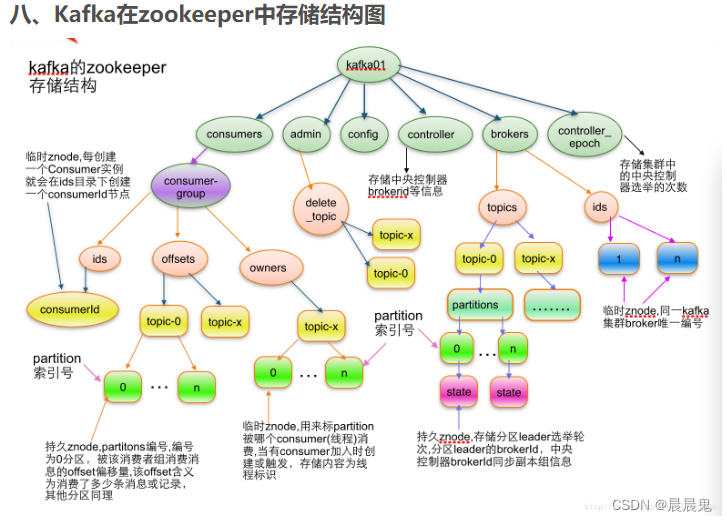
kafka操作
生产者消费者
- 点对点模式
消息生产者生产消息发送到消息队列(queue),消费者从queue中取出并且消费信息,而这条信息被消费后queue中就没有了这条信息,不存在重复消费
- 发布/订阅
发布者发布消息发送到消息队列(topic),订阅者从topic中取出并且消费信息,而这条信息被消费后topic中还存在这条信息,存在重复消费
在发布订阅模式下,发布者信息量很大时,显然单个订阅者的消费能力是不够的,在实际应用中往往是通过多个订阅者组成一个订阅组来负载均衡消费topic信息
也就是分组订阅,这样订阅者就可以较容易的实现消费能力的线性拓展。可以看做一个topic下有多个queue,每个queue都实现点对点的的消费模式,而Queue之间是发布/订阅模式
Kafka生产者为了避免高并发请求对服务端造成过大压力,增加了一个高速缓存,将消息集中到缓存后,批量进行发送。这种缓存机制也是高并发处理时非常常用的一种机制。
- 消息缓存机制
Kafka的消息缓存机制涉及到KafkaProducer中的两个关键组件: accumulator 和 sender
- RecordAccumulator
RecordAccumulator,就是Kafka生产者的消息累加器,分批发送给kafka broker。
RecordAccumulator中,会针对每一个Partition,维护一个Deque双端队列,这些Dequeue队列基本上是和Kafka服务端的Topic下的Partition对应的。每个Dequeue里会放入若干个ProducerBatch数据。KafkaProducer每次发送的消息,都会根据key分配到对应的Deque队列中。然后每个消息都会保存在这些队列中的某一个ProducerBatch中。而消息分发的规则,就是由上面的Partitioner组件完成的。
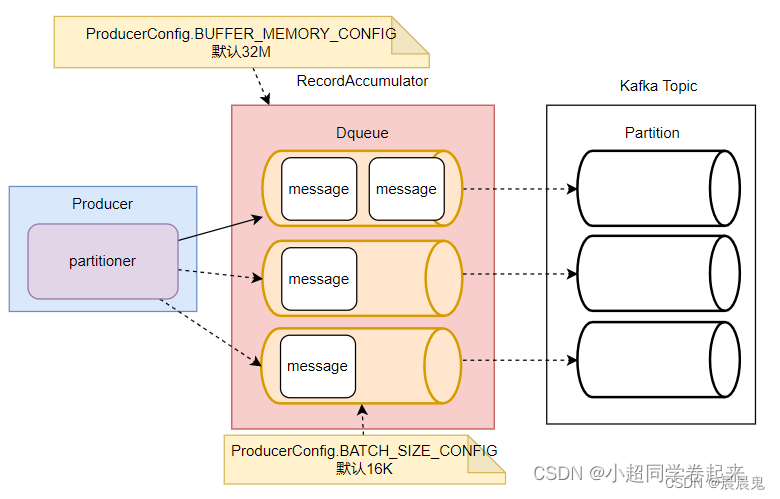
- Sender
是KafkaProducer中用来发送消息的一个单独的线程。从这里可以看到,每个KafkaProducer对象都对应一个sender线程。他会负责将RecordAccumulator中的消息发送给Kafka。
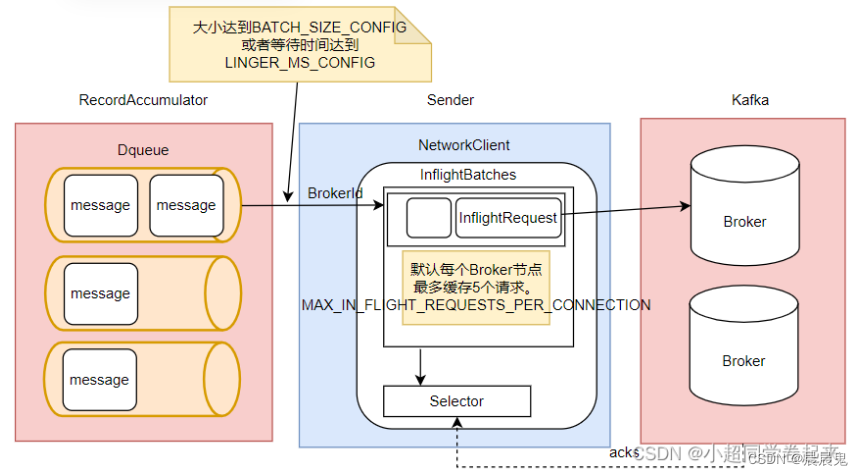
Sender也并不是一次就把RecordAccumulator中缓存的所有消息都发送出去,而是每次只拿一部分消息。他只获取RecordAccumulator中缓存内容达到BATCH_SIZE_CONFIG大小的ProducerBatch消息。当然,如果消息比较少,ProducerBatch中的消息大小长期达不到BATCH_SIZE_CONFIG的话,Sender也不会一直等待。最多等待LINGER_MS_CONFIG时长。然后就会将ProducerBatch中的消息读取出来。LINGER_MS_CONFIG默认值是0。
然后,Sender对读取出来的消息,会以Broker为key,缓存到一个对应的队列当中。这些队列当中的消息就称为InflightRequest。接下来这些Inflight就会一一发往Kafka对应的Broker中,直到收到Broker的响应,才会从队列中移除。这些队列也并不会无限缓存,最多缓存MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION(默认值为5)个请求
生产者缓存机制的主要目的是将消息打包,减少网络IO频率。所以,在Sender的InflightRequest队列中,消息也不是一条一条发送给Broker的,而是一批消息一起往Broker发送。而这就意味着这一批消息是没有固定的先后顺序的。
1. 生产者启动
生产者把消息指定在topic test1,等于用命令行执行–topic test1的生产者启动
bin/kafka-console-producer.sh --broker-list ip:9092 --topic test1
生产者拦截机制允许客户端在生产者在消息发送到Kafka集群之前,对消息进行拦截,甚至可以修改消息内容。
(需要自己写一个类,同时再配置文件中producer.properties里interceptor.classes=com.example.MyInterceptor最后在启动的时候--producer.config)
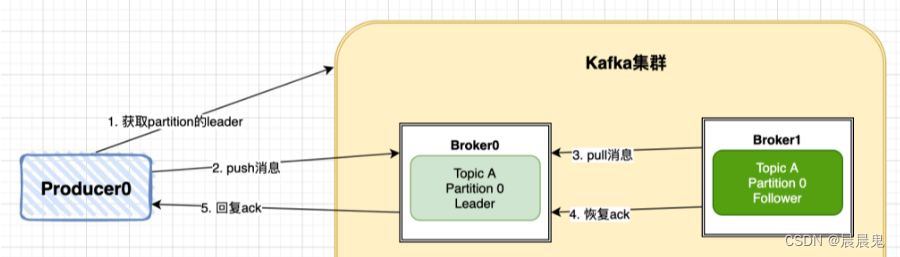
Kafka生产者生产消息后,会将消息发送到Kafka集群的Leader中,然后Kafka集群的Leader收到消息后会返回ACK确认消息给生产者Producer。主要拆解为以下几个步骤。
Producer先从Kafka集群找到该Partition的Leader。
Producer将消息发送给Leader,Leader将该消息写入本地。
Follwer从Leader pull消息,写入本地Log后Leader发送ACK。
Leader 收到所有 ISR 中的 Replica 的 ACK 后,增加High Watermark,并向 Producer 发送 ACK。
Kafka集群(其实是分区的Leader)最终会返回一个ACK来确认Producer推送消息的结果,这里Kafka提供了三种模式:
- NoResponse RequiredAcks = 0:这个代表的就是不进行消息推送是否成功的确认。Producer不进行消息发送的确认
- WaitForLocal RequiredAcks = 1:当local(Leader)确认接收成功后,就可以返回了。有可能 Follower 并没有接收到对应消息。此时如果 Leader 突然宕机,在经过选举之后,没有接到消息的 Follower 晋升为 Leader,从而引起消息丢失。
- WaitForAll RequiredAcks = -1:当所有的Leader和Follower都接收成功时,才会返回。可以很好的确认Kafka集群是否已经完成消息的接收和本地化存储,并且可以在Producer发送失败时进行重试。
生产端解决消息丢失方案:
- 通过设置RequiredAcks模式来解决,选用WaitForAll(对应值为-1)可以保证数据推送成功,不过会影响延时。
- 引入重试机制,设置重试次数和重试间隔。
Producer会重复发送多条消息到Broker中。Kafka如何保证无论Producer向Broker发送多少次重复的数据,Broker端都只保留一条消息,而不会重复保存多条消息呢?这就是Kafka消息生产者的幂等性问题。
分布式数据传递过程中的三个数据语义:
at-least-once可以保证数据不丢失(ack=1或-1),但是不能保证数据不重复。而at-most-once(ack=0)保证数据不重复,但是又不能保证数据不丢失。这两种语义虽然都有缺陷,但是实现起来相对来说比较简单。但是对一些敏感的业务数据,往往要求数据即不重复也不丢失,这就需要支持Exactly-once语义。
如果要支持Exactly-once语义怎么办呢?这就需要使用到idempotence幂等性属性了。
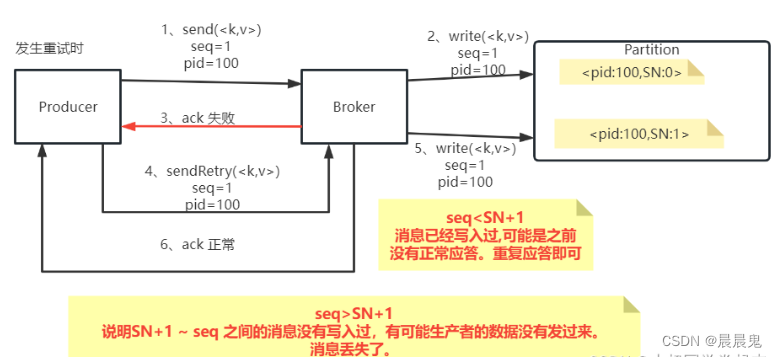
- PID:每个新的Producer在初始化的过程中就会被分配一个唯一的PID。这个PID对用户是不可见的。
- Sequence Numer: 对于每个PID,这个Producer针对Partition会维护一个sequenceNumber。这是一个从0开始单调递增的数字。当Producer要往同一个Partition发送消息时,这个Sequence Number就会加1。然后会随着消息一起发往Broker。
Broker端则会针对每个<PID,Partition>维护一个序列号(SN),只有当对应的SequenceNumber = SN+1时,Broker才会接收消息,同时将SN更新为SN+1。否则,SequenceNumber过小就认为消息已经写入了,不需要再重复写入。而如果SequenceNumber过大,就会认为中间可能有数据丢失了。对生产者就会抛出一个OutOfOrderSequenceException。
这样,Kafka在打开idempotence幂等性控制后,在Broker端就会保证每条消息在一次发送过程中,Broker端最多只会刚刚好持久化一条。这样就能保证at-most-once语义。再加上之前分析的将生产者的acks参数设置成1或-1,保证at-least-once语义,这样就整体上保证了Exactaly-once语义。
解决单生产者消息写入单分区的的幂等性问题。但是,如果是要写入多个分区Partition是分布在不同Broker上的呢?
这时候就需要有一个事务机制,保证这一批消息最好同时成功的保持幂等性。或者这一批消息同时失败,这样生产者就可以开始进行整体重试,消息不至于重复。
消息事务机制
可以先启动一个订阅了disTopic这个Topic的消费者,然后启动这个生产者,进行试验。在这个试验中,发送到第3条消息时,主动放弃事务,此时之前的消息也会一起回滚
实际上,Kafka的事务消息还会做两件事情:
1、一个TransactionId只会对应一个PID
如果当前一个Producer的事务没有提交,而另一个新的Producer保持相同的TransactionId,这时旧的生产者会立即失效,无法继续发送消息。
2、跨会话事务对齐
如果某个Producer实例异常宕机了,事务没有被正常提交。那么新的TransactionId相同的Producer实例会对旧的事务进行补齐。保证旧事务要么提交,要么终止。这样新的Producer实例就可以以一个正常的状态开始工作。
生产者的事务消息机制保证了Producer发送消息的安全性,但是,他并不保证已经提交的消息就一定能被所有消费者消费。
- 最后就是使用Kafka的多副本机制保证Kafka集群本身的可靠性,确保当Leader挂掉之后能进行Follower选举晋升为新的Leader。
2. 消费者启动
bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --topic test1 --from-beginning
--from-beginning 选项用于从指定主题(topic)的起始位置开始消费消息
--topic test1,test2 就可以同时订阅两个生产者
3. 查看topic详细信息
--bootstrap-server 是一个逐渐盛行的选项参数,这一点毋庸置疑。而 --broker-list 已经被淘汰,–zookeeper 这个选项参数也逐渐被替代,在目前的 2.0.0 版本中,kafka-console-consumer.sh 中已经完全没有了它的影子,但并不意味着这个参数在其他脚本中也被摒弃了。在 kafka-topics.sh 脚本中还是使用的 --zookeeper 这个选项参数,并且在未来的可期版本中也不见得会被替换,因为 kafka-topics.sh 脚本实际上操纵的就是 ZooKeeper 中的节点,而不是 Kafka 本身,它并没有被替代的必要。
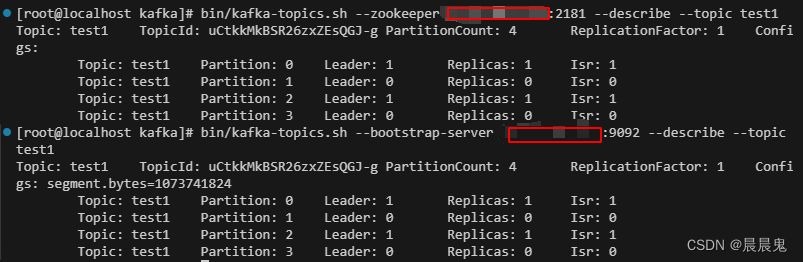
bin/kafka-topics.sh --zookeeper ip:2181 --describe --topic test1
bin/kafka-topics.sh --bootstrap-server ip:9092 --describe --topic test1
Leader: 存放该分区副本的 broker 编号为 1。
Replicas: 该分区的副本在 broker 1 上。
Isr: 1 表示当前备份的 in-sync 副本在此。
Partition 0 的副本存放在 Broker 1 上。
Partition 1 的副本存放在 Broker 0 上。
replica.lag.time.max.ms =10000
replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中
-
Kafka 的主题可以配置多个副本(replicas),每个分区(partition)有一个 leader 副本和多个 follower 副本。
当 leader 所在的 Broker 出现故障时,Kafka 会自动将 leader 移除,并从其他可用的副本中选举一个新的 leader,以确保数据可靠性和服务的持续性。
停掉集群中一台broker之前,查看topic信息
再次将该broker启动后,该节点原先leader分片不能够再次恢复leader角色 -
增加分区备份可以提供集群的吞吐量和可用性,但是也要注意集群的总分区数过多,会增加不可用及延迟的风险(人数越多,选举越慢;分组越多,leader挂掉的次数越多)
-
Kafka分区选举机制不是常见的
多数选举,而是会在zookeeper上针对每一个Topic维护一个称为ISR(已同步可用副本)集合,只有这个ISR列表里面的副本才有资格称为leader(直接使用Replicas里面第一个,以次类推) -
新增加的broker没有参与Topic分区,需要通过分区重新分配来分配数据
新增分区3和分区0的leader都是borker节点0上,导致压力过大。
现在我们新增一台broker,加入kafka集群,使得上一步新增节点均匀分布到每一个broker。但现集群新增broker并没有改变现在的分片分布状态
(还未实践过的方案)
#我们需要对分片重新进行分配
#1)、声明那些topic需要重新分区
vim reset.json
{
"topics":[{"topic":"test"}],
"version":1
}
#执行kafka-reassign-partitions.sh脚本生成分配规则候选项:
./bin/kafka-reassign-partitions.sh --zookeeper ip:2181 --topics-to-move-json-file reset.json --broker-list "0,1,2,3" --generate
{"version":1,"partitions":[
{"topic":"test","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]},
{"topic":"test","partition":1,"replicas":[2,0,1],"log_dirs":["any","any","any"]},
{"topic":"test","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},
{"topic":"test","partition":3,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[
{"topic":"test","partition":1,"replicas":[2,1,3],"log_dirs":["any","any","any"]},
{"topic":"test","partition":3,"replicas":[0,3,1],"log_dirs":["any","any","any"]},
{"topic":"test","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]},
{"topic":"test","partition":2,"replicas":[3,2,0],"log_dirs":["any","any","any"]}]}
#2)、定义一个分片规则
#根据上一步候选分片规则选择进行重新分片,输入分片规则json数据
vim result.json
{"version":1,"partitions":[
{"topic":"test","partition":1,"replicas":[2,1,3],"log_dirs":["any","any","any"]},
{"topic":"test","partition":3,"replicas":[0,3,1],"log_dirs":["any","any","any"]},
{"topic":"test","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]},
{"topic":"test","partition":2,"replicas":[3,2,0],"log_dirs":["any","any","any"]}]}
#重新分片:
/bin/kafka-reassign-partitions.sh --zookeeper ip:2181 --reassignment-json-file result.json --execute
{"version":1,"partitions":[
{"topic":"test","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]},
{"topic":"test","partition":1,"replicas":[2,0,1],"log_dirs":["any","any","any"]},
{"topic":"test","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},
{"topic":"test","partition":3,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
4. 查看consumer group
- 设置consumer分组
--group kafkaconsumer
bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --topic test1 --from-beginning --group kafkaconsumer
- 查看group列表
bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --list test2
- 查看特定consumer group 详情,使用–group与–describe参数(包含OFFSET)
bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --group console-consumer-83307 --describe
console-consumer-83307换成consumer的group分组名也是一样的

- tes1的生产者给test2的消费者发消息他收不到。
如果不分组,那么创建两个消费者,都订阅同一个test1生产者,那么两边consumer都可以收到消息。
消费者组
Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制。
Consumer Group特性:
- Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
- 在一个 Kafka 集群中,Group ID 标识唯一的一个 Consumer Group。
- Consumer Group 下所有实例订阅的主题topic的单个partition分区,只能分配给组内的某个 Consumer 实例消费。这个分区当然也可以被其他的 Group 消费。消费组订阅的主题每个分区只能分配给消费组一个消费者。
Kafka 仅仅使用 Consumer Group 这一种机制,同时实现了传统消息引擎系统的两大模型:
- 如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;
- 如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
消费组状态机
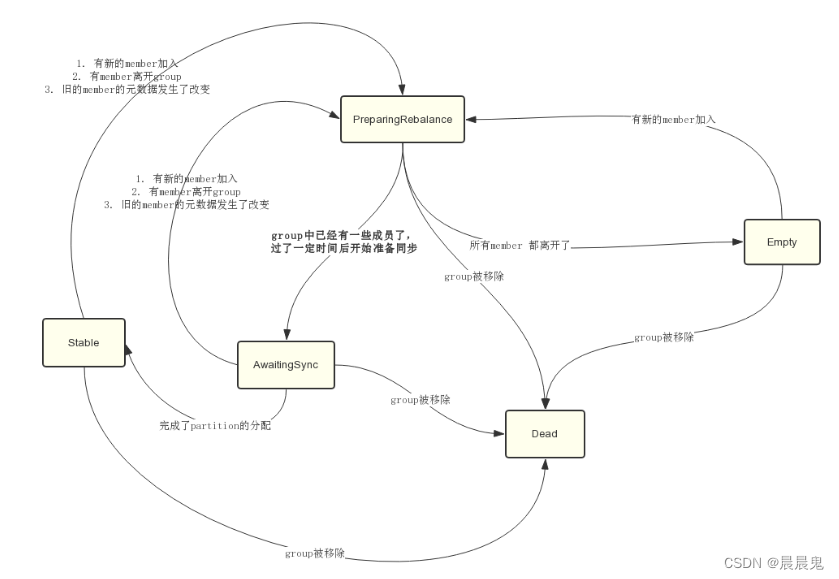
Consumer在加入Group后,会开启一个线程,不断的向GroupCoordinator发送心跳请求,报告自己还活着。GroupCoordinator会管理group中所有Consumer的心跳,如果发现有一个Consumer超过一定时间没有发送心跳过来,GroupCoordinator会认为这个Consumer已经离开group。这时GroupCoordinator会将该group的状态重新置为PreparingRebalance,开启新一轮的partition分配。
心跳的发送频率和Consumer的配置 heartbeat.interval.ms有关,默认是3000,也就是每3s发送一次心跳。
GroupCoordinator判断member是否过期和consumer的配置session.timeout.ms有关,默认为10000,也就是超过10s没收到心跳请求,就移除该member。
- Dead:组内已经没有任何成员的最终状态,组的元数据也已经被组协调器移除了。这种状态响应各种请求都是一个response: UNKNOWN_MEMBER_ID
- Empty:组内无成员,但是位移信息还没有过期。这种状态只能响应JoinGroup请求
- PreparingRebalance:组准备开启新的rebalance,等待成员加入
- AwaitingSync:正在等待leader consumer将分配方案传给各个成员
- Stable:再均衡完成,可以开始消费。
协议(protocol)
kafka提供了5个协议来处理与消费组协调相关的问题:
- Heartbeat请求:consumer需要定期给组协调器发送心跳来表明自己还活着
- LeaveGroup请求:主动告诉组协调器我要离开消费组
- SyncGroup请求:消费组Leader把分配方案告诉组内所有成员
- JoinGroup请求:成员请求加入组
- DescribeGroup请求:显示组的所有信息,包括成员信息,协议名称,分配方案,订阅信息等。通常该请求是给管理员使用
组协调器在再均衡的时候主要用到了前面4种请求。
Rebalance 重平衡
Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区。
Kafka 使用分区机制来确定将消息发送给消费者组中的哪个消费者
重平衡是指在以下情况下 Kafka 消费者组内的消费者之间重新分配分区的过程
所有成员都向消费组协调器发送JoinGroup请求,先重新选出leader,再重新分区策略。
在协调器收集到所有成员请求前,它会把已收到请求放入一个叫purgatory(炼狱)的地方。然后是分发分配方案的过程,即SyncGroup请求。
也就是触发下文的消费规则
Consumer Group 何时进行 Rebalance 呢?Rebalance 的触发条件有 3 个。
- 组成员数发生变更。比如有新的 Consumer 实例加入组或者离开组,抑或是有 Consumer 实例崩溃被“踢出”组。
- 订阅主题数发生变更。Consumer Group 可以使用正则表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile(“t.*c”)) 就表明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主题。在 Consumer Group 的运行过程中,你新创建了一个满足这样条件的主题,那么该 Group 就会发生 Rebalance。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
消费规则
因此,ip2 的机器上的 Kafka 实例可以查看到整个 Kafka 集群中的主题列表,包括在其他机器上存储的主题,比如之前提到的主题 topic1。这样,不同的 Kafka 实例可以共享同一份主题元数据信息,并保持一致性,以便进行消息的发布和订阅。
Kafka 中,消费者订阅的是主题(topic),而不是直接订阅主题所在的特定机器。因此,即使主题在一个机器上,消费者也可以通过网络连接到 Kafka 集群中的任何 Kafka 实例,并订阅该主题并消费消息。
消息分配给消费者是通过消费者组内的消费者来完成的,而不是通过不同机器上的 Kafka 实例来分配的。消费者组内的消费者在不同的机器上运行,但它们通过网络连接到同一个 Kafka 集群。
- 分区策略
消费组的分区分配方案在客户端执行。Kafka交给客户端可以有更好的灵活性。Kafka默认提供三种分配策略:range和round-robin和sticky。可以通过消费者的参数:partition.assignment.strategy 来实现自己分配策略。
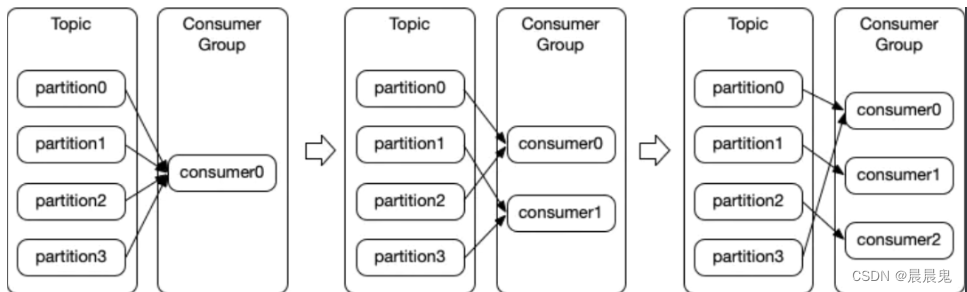
一个消费者订阅多个主题时,它会同时从这些主题中接收消息,并按照订阅顺序对消息进行处理。消费者可以有不同的订阅策略,比如平均分配,轮询订阅等。
- Range 范围分区(默认的)
假如有10个分区,3个消费者,把分区按照序号排列0,1,2,3,4,5,6,7,8,9;消费者为C1,C2,C3,那么用分区数除以消费者数来决定每个Consumer消费几个Partition,除不尽的前面几个消费者将会多消费一个 最后分配结果如下
C1:0,1,2,3 C2:4,5,6 C3:7,8,9
如果有11个分区将会是:
C1:0,1,2,3 C2:4,5,6,7 C3:8,9,10
假如我们有两个主题T1,T2,分别有10个分区,最后的分配结果将会是这样:
C1:T1(0,1,2,3) T2(0,1,2,3) C2:T1(4,5,6) T2(4,5,6) C3:T1(7,8,9) T2(7,8,9)
在这种情况下,C1多消费了两个分区
- RoundRobin 轮询分区
把所有的partition和consumer列出来,然后轮询consumer和partition,尽可能的让把partition均匀的分配给consumer
假如有3个Topic T0(三个分区P0-0,P0-1,P0-2),T1(两个分区P1-0,P1-1),T2(四个分区P2-0,P2-1,P2-2,P2-3)
有三个消费者:C0(订阅了T0,T1),C1(订阅了T1,T2),C2(订阅了T0,T2)
那么分区过程如下图所示
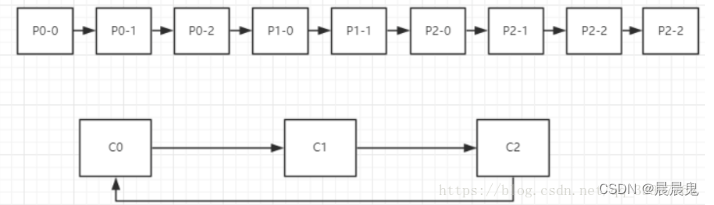
分区将会按照一定的顺序排列起来,消费者将会组成一个环状的结构,然后开始轮询。 P0-0分配给C0 P0-1分配给C1但是C1并没订阅T0,于是跳过C1把P0-1分配给C2, P0-2分配给C0 P1-0分配给C1, P1-1分配给C0, P2-0分配给C1, P2-1分配给C2, P2-2分配给C1, p2-3分配给C2
C0: P0-0,P0-2,P1-1 C1:P1-0,P2-0,P2-2 C2:P0-1,P2-1,P2-3
- Sticky
StickyAssignor黏性分区,是0.11.x版本引入的新分配策略,它主要有两个目的:
分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个;
分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分区。最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
这样看上去似乎与采用RoundRobinAssignor策略所分配的结果相同,但实际并非如此
此时假设消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobin策略,那么此时的分配结果如下:
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobin策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用的是StickyAssignor策略,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中,保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1消费的分区,分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
那么在哪些场景下我们可以自己来定义分区器呢?
例如如果在部署消费者时,如果我们的服务器配置不一样,就可以通过定制消费者分区器,让性能更好的服务器上的消费者消费较多的消息,而其他服务器上的消费者消费较少的消息,这样就能更合理的运用上消费者端的服务器性能,提升消费者的整体消费速度。
订阅模式主要关注消费者订阅哪些主题,而分区策略关注如何将订阅的主题的分区分配给不同的消费者实例。
订阅模式是订阅行为的描述,而分区策略是消费者群体内的工作分配规则。
- 订阅模式
在 Kafka 中,消费者(Consumer)可以使用不同的订阅模式来订阅主题(topic)。KafkaConsumer#poll()方法拉取最新的日志。这个方法执行:
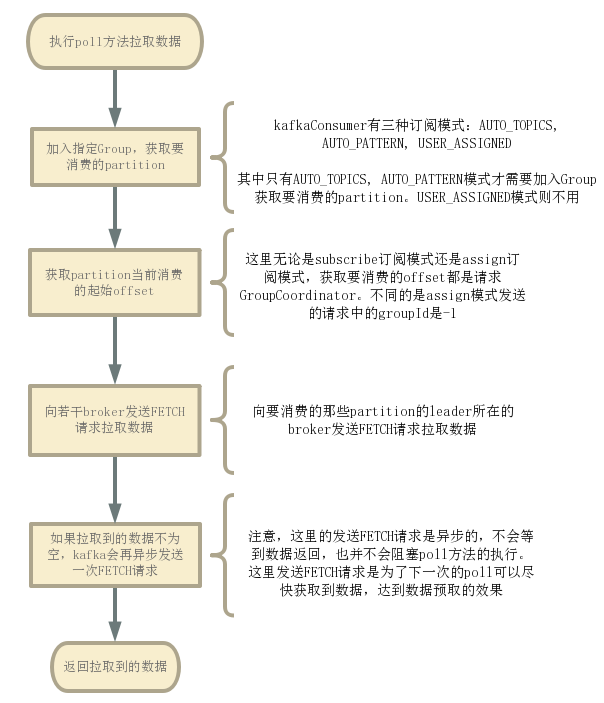
AUTO TOPICS:使用 AUTO TOPICS 订阅模式时,消费者会自动订阅 Kafka 集群中的所有主题。这意味着一旦某个主题被创建或者消费者启动时,消费者会自动订阅所有的topic,无需手动指定。通过订阅相关topic,加入到指定Group后,由GroupCoordinator来分配要消费的partition。AUTO_TOPICS模式是topic粒度级别的订阅
AUTO PATTERN:消费者可以通过指定一个正则表达式(pattern)来订阅符合该正则表达式的主题。consumer需要去获取所有topics,然后去匹配parttern,匹配上的那些topic就是要消费的那些topic,之后和AUTO_TOPICS模式一样,加入Group获取要消费的partition。AUTO_PATTERN模式是topic粒度级别的订阅
我们可以指定一个topic列表,或者直接指定要消费topic的pattern。
如果是AUTO_TOPICS模式,Consumer会去broker拉取指定topics的元数据。如果是AUTO_PATTERN,Consumer就会将所有topics的元数据拉取下来,然后去匹配获取真正要消费的topics是哪些。
获取到topics的元数据后,在执行poll方法拉取数据的时候,consumer就会自动帮我们加入Group,然后获取要消费的partition。
Consumer如何加入和离开Group的:
Consumer 加入&离开 Group详解
USER ASSIGNED:使用 USER ASSIGNED 订阅模式时,消费者需要手动指定要订阅的主题列表。消费者可以根据自己的需求选择订阅的主题,这种方式适用于需要精确控制订阅主题的情况。直接执行KafkaConsumer#assign()方法来指定要消费的topic-partition。USER_ASSIGNED模式是parition粒度级别的订阅 。
由于该模式是用户自己指定要消费哪些topic-partition,因此,当topic的partition数量发生改变时,程序不会做通知,用户需要自行去处理。
该模式下Consumer就不会执行加入Group的那些操作。
获取到要消费哪些partition后,就要知道要从partiton的哪个offset开始消费。也就是要确定commitedOffset。
kafka 的OFFSET
consumer消费的offset情况是存储在zookeeper中的,后来kafka设计者将consumer的commitedoffset写到内部的一个topic中,也就是__consumer_offsets。
Kafka中的每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息。
Offset记录着下一条将要发送给Consumer的消息的序号。
Kafka集群中offset的管理都是由Group Coordinator中的Offset Manager完成的。该分区leader所在的broker就是被选定的coordinator.
对于每一个Consumer Group,Group Coordinator都会存储以下信息:
- 订阅的topics列表
- Consumer Group配置信息,包括session timeout等
- 组中每个Consumer的元数据。包括主机名,consumer id
- 每个Group正在消费的topic partition的当前offsets
- Partition的ownership元数据,包括consumer消费的partitions映射关系

offset获取
Kafka在生产者消费者的运作过程中,突然断电后,重启,会从哪里继续读起?从配置文件或者命令行中可以设置吗?
Consumer在消费时,会在内存中保存各个partition的commitedOffset。
但是在刚刚获取到要消费的parititon是哪些的时候,还并没有partition的commitedOffset数据。这时候就需要向GroupCoordinator发送OFFSET_FETCH请求来获取对应partition的commitedOffset。
不过,只有AUTO_TOPICS 和 AUTO_PATTERN模式才可能可以从GroupCoordinator获取到commitedOffset记录(如果指定的Group是新建的,则也获取不到)。USER_ASSIGNED模式由于不归GroupCoordinator管理,所以GroupCoordinator无法知道其commitedOffset。
如果无法从GroupCoordinator获取消费过的offset,Consumer就会通过auto.offset.reset配置定义的策略设置一个新的offset作为commitedOffset。auto.offset.reset有三种策略:(见kafka消费者配置文件)
latest:默认策略。获取partition中最新的一条offset。也就是LEO
earliest:获取partition的最早的一条offset。
none:配置了该策略的话,如果没有从GroupCoordinator获取到commitedOffset,就会抛异常。
Consumer根据策略的获取offset的方式是向broker发送LIST_OFFSETS请求。broker就会根据策略返回指定partition的offset
消费过程(分区策略)
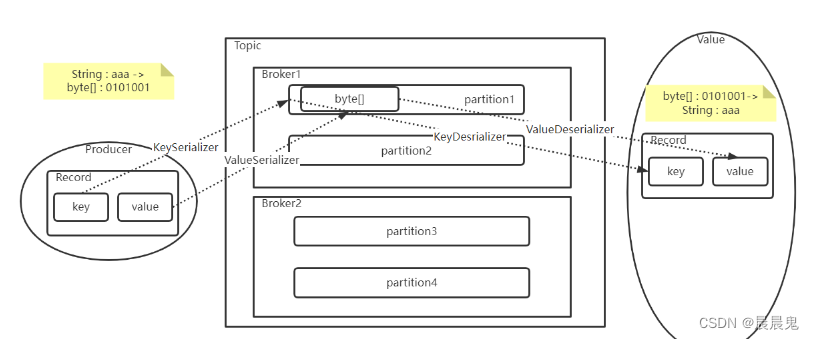
- 反序列化
Kafka的broker中所有的消息都是字节数组,消费者获取到消息之后,需要先对消息进行反序列化处理,然后才能交给用户程序消费处理。
消费者的反序列化器包括key的和value的反序列化器。
Consumer会遍历要消费的partition,找出要往哪些broker发送FETCH请求(根据partition的leader所在的broker)。之后遍历这些broker,逐个发送FETCH请求(分区策略),leader在同一个broker的partition的FETCH请求会一起发送。
- 序列化
将Value转换成byte[]数组,这样才能比较好的在网络上传输Value信息,以及将Value信息落盘到操作系统的文件当中。
生产者要对消息进行序列化,那么消费者拉取消息时,自然需要进行反序列化。所以,在Consumer中,也有反序列化的两个配置
- 定长的基础类型,比如Integer,Long,Double等。这些基础类型转化成二进制数组都是定长的。这类属性可以直接转成序列化数组,在反序列化时,只要按照定长去读取二进制数据就可以反序列化了。
- 不定长的浮动类型,比如String,或者基于String的JSON类型等。这种浮动类型的基础数据转化成二进制数组,长度都是不一定的。对于这类数据,通常的处理方式都是先往二进制数组中写入一个定长的数据的长度数据(Integer或者Long类型),然后再继续写入数据本身。这样,反序列化时,就可以先读取一个定长的长度,再按照这个长度去读取对应长度的二进制数据,这样就能读取到数据的完整二进制内容。
offset提交(保证offset安全性)

消费完数据之后,offset的提交方式非常重要。offset提交早了可能导致消息丢失,offset提交晚了可能导致消息重复消费。enable.auto.commit = true分为手动和自动提交。另外kafka会定期把group消费情况保存起来,做成一个offset map,如下图所示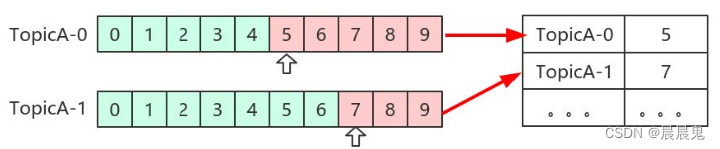
- 同步和异步提交
同步提交和异步提交其实底层都是向broker发送OFFSET_COMMIT请求。不同的是同步的会等待请求返回,异步的不会等待请求返回。
-
异步提交。就是消费者在处理业务的同时,异步向Broker提交Offset。这样好处是消费者的效率会比较高,但是如果消费者的消息处理失败了,而offset又成功提交了,这就会造成消息丢失。
-
同步提交。消费者保证处理完所有业务后,再提交Offset。这样的好处自然是消息不会因为offset丢失了。因为如果业务处理失败,消费者就可以不去提交Offset,这样消息还可以重试。但是坏处是消费者处理信息自然就慢了。另外还会产生消息重复。因为Broker端不可能一直等待消费者提交。如果消费者的业务处理时间比较长,这时在消费者正常处理消息的过程中,Broker端就已经等不下去了,认为这个消费者处理失败了。这时就会往同组的其他消费者实例投递消息,这就造成了消息重复处理。
其实这类问题的根源在于Offset反映的是消息的处理进度。而消息处理进度跟业务的处理进度又是不同步的。所有我们可以换一种思路,将Offset从Broker端抽取出来,放到第三方存储比如Redis里自行管理。这样就可以自己控制用业务的处理进度推进Offset往前更新。
- 自动提交offset
如果partition是由GroupCoordinator分配并管理的,并且Consumer配置enable.auto.commit为true,则在每次poll拉取数据之前,kafka都会自动异步提交已经拉取过的offset。该配置默认是开启的,自动提交的频率和auto.commit.interval.ms有关,该配置的默认值是5000。
-
客户端流程总结
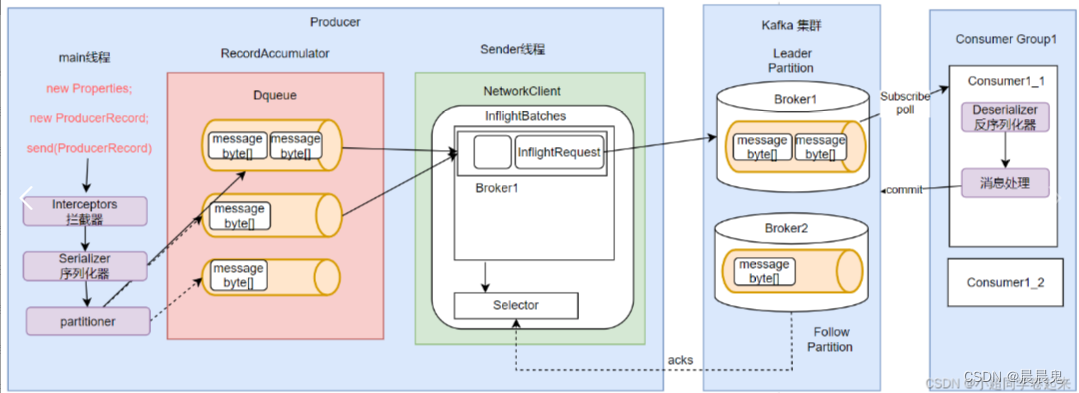
客户端 KafkaProducer1与 Kafka Cluster 直连,这是客户端给我们的既定印象,而事实上客户端连接 Kafka 集群要经历以下3个过程. -
客户端 KafkaProducer 与 bootstrap.servers 参数所指定的 Server 连接,并发送 MetadataRequest 请求来获取集群的元数据信息。
-
Server 在收到 MetadataRequest 请求之后,返回 MetadataResponse 给 KafkaProducer,在 MetadataResponse 中包含了集群的元数据信息。
-
客户端 KafkaProducer 收到的 MetadataResponse 之后解析出其中包含的集群元数据信息,然后与集群中的各个节点建立连接,之后就可以发送消息了。

生产者从KafKa集群中获取分区leader信息
生产者将消息发送到leader上
leader将消息写入到本地磁盘中
follower从leader处拉取消息数据
follower将消息写入到本地磁盘中,完成后发送ACK给leader
leader收到所有follower的ACK后向生产者发送ACK
报错记录
- ERROR [ListenerHandler-/10.19.200.177:3881:QuorumCnxManager L i s t e n e r Listener ListenerListenerHandler@1093] - Exception while listening java.net.BindException: 无法指定被请求的地址 (Bind failed)
添加 quorumListenOnAllIPs=true
- [2024-05-30 15:29:55,666] ERROR Error while creating ephemeral at /brokers/ids/0, node already exists and owner ‘72057608683585536’ does not match current session ‘72057614825357316’
- 进入zkcli.sh后删除brokers/ids/0的残余内容
- 删除kafka-logs里面的残余内容
- ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING
重启,然后删除残余的kafka内容。
- 记得
/etc/resolv.conf配置DNS
集群监控
使用kafka做消息队列中间件时,为了实时监控其性能时,免不了要使用jmx调取kafka broker的内部数据,不管是自己重新做一个kafka集群的监控系统,还是使用一些开源的产品,比如yahoo的kafka manager, 其都需要使用jmx来监控一些敏感的数据
这种严重依赖于Zookeeper的设计会有脑裂、羊群效应以及造成Zookeeper过载的隐患。
假死: 由于心跳超时 (网络原因导致的) 认为master死了,但其实master还存活着。
脑裂:由于假死会发起新的master选举,选举出一个新的master,但旧的master网络又通了,导致出现了两个master,有的客户端连接到老的master 有的客户端链接到新的master。
Zookeeper的解决方案
要解决Split-Brain的问题,一般有3种方式:
-
Quorums ('kworem 法定人数):比如3个节点的集群,Quorums =2, 也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。比如4个节点的集群,它的Quorums =3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的
-
Redundant communications:冗余通信的方式,集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
-
Fencing, 共享资源的方式:比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是Leader,看不到共享资源的,就不在集群中。
ZooKeeper默认采用了Quorums这种方式,即只有集群中超过半数节点投票才能选举出Leader。这样的方式可以确保leader的唯一性,要么选出唯一的一个leader,要么选举失败。
在ZooKeeper中Quorums有2个作用:
- 集群中最少的节点数用来选举Leader保证集群可用:通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch,这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。那有没有follower不知道新的leader存在呢,有可能,但肯定不是大多数,否则新leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧leader即使各种认为自己是leader,依然没有什么作用。
总结一下就是,通过Quorums机制(过半机制)来防止脑裂和假死,当leader挂掉之后,可以重新选举出新的leader节点使整个集群达成一致;当出现假死现象时,通过epoch大小来拒绝旧的leader发起的请求,在前面也已经讲到过,这个时候,重新恢复通信的老的leader节点会进入恢复模式,与新的leader节点做数据同步,perfect。
报错 id 不匹配 且broker里不存在
[2024-07-09 13:41:15,470] ERROR Error while creating ephemeral at /brokers/ids/0, node already exists and owner '216172782622605312' does not match current session '72057998844166144' (kafka.zk.KafkaZkClient$CheckedEphemeral)
[2024-07-09 13:41:15,476] ERROR [KafkaServer id=0] Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
org.apache.zookeeper.KeeperException$NodeExistsException: KeeperErrorCode = NodeExists
at org.apache.zookeeper.KeeperException.create(KeeperException.java:126)
at kafka.zk.KafkaZkClient$CheckedEphemeral.getAfterNodeExists(KafkaZkClient.scala:1904)
at kafka.zk.KafkaZkClient$CheckedEphemeral.create(KafkaZkClient.scala:1842)
at kafka.zk.KafkaZkClient.checkedEphemeralCreate(KafkaZkClient.scala:1809)
at kafka.zk.KafkaZkClient.registerBroker(KafkaZkClient.scala:96)
at kafka.server.KafkaServer.startup(KafkaServer.scala:308)
at kafka.Kafka$.main(Kafka.scala:109)
at kafka.Kafka.main(Kafka.scala)
解决方法就是把kafka-logs删除重建。但此时只会删除一个broker的log,也就是把broker 0 的log落盘清除了。但是其他broker依然保存了offset在他们自己的logs里面,会导致消费者消费卡顿。

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









