







Machine Learning
Part 8:神经网络:表述(Neural Networks: Representation)
- Non-linear Hypotheses(非线性假设)
- Problems:
- 通过之前的学习发现,一般来说,特征的数量越多,高此项越多的假设模型越精确(联想过拟合问题),但是无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
-Idea:
- 我们需要强大的,灰常有用的 Neural Networks algorithm 解决掉features多的问题,拯救我们于水火之中。
- Neurons and the Brain(神经元与大脑)科普。。
- Idea:
- 神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。
- 你把几乎任何传感器接入到大脑中,大脑的学习算法都能自动找出学习数据的方法,并处理这些数据。大脑处理这些数据只需要一个单一的学习算法就可以了。
- 神经网络诞生的目的就是为了模仿大脑处理数据的方法,利用一种算法,处理各种机器学习问题。
- 简直强的没边了~
- Model Representation I(模型表示1)
在神经网络中,参数theta又被成为权重(weight)
Sigmoid(logistic)function == activation function(激活函数)
-
Idea:
- 简而言之,神经元就是一个计算单元,它从输入通道接受一定数量的信息,并做一些计算,然后将结果传输到其它的神经元
- 神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入,并且根据本身的模型提供一个输出。
- Single neural model:Logistic unit
- Neural Networks:a group of neurons
![在这里插入链描述(,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly912970637)]]](https://i-blog.csdnimg.cn/blog_migrate/5ba16a2eeb279a49719a5ceb3e235f6b.png)
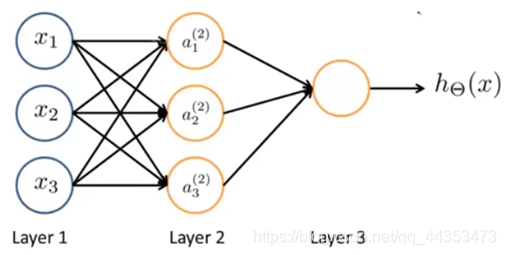
- 神经网络的第一层被称为输入层(Input Layer),因为我们在这一层输入特征(Input Features)
- 神经网络的最后一层被称为输出层(Output Layer),因为在这一层的神经元输出假设的最终计算结果。
- 中间层也被称为是隐藏层(Hidden Layer),隐藏层可以不只又一层,事实上除了输入输出层剩下的都可以被看作是隐藏层。
-
对于新模型的注释:

- theta^(j) 就是权重矩阵,它控制从第J层到第J+1层的映射。矩阵的行数==第J+1层激活单元的数量,矩阵的列数==第J层激活单元的数量+1。 例如,在上图的模型中, theta(1) 就是从第一层到第二层的映射,它的维度是3*4
-
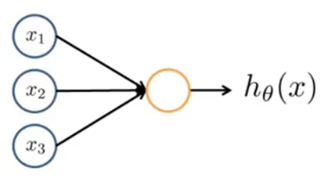
隐藏层激活单元值的计算:
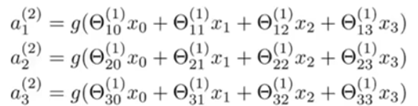
- 这也就是为什么说 activation function == Logistic function
- 我们再挑出来个权重详细的说说它具体表示啥:
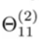
(2)表示这是从第二层向第三层的映射
底下的11:从第二层的第一个unit向第三层的第一个unit的feature。第一个1是指J+1层第n个unit,第二个1是指J层的第n个unit
-
假设最终输出结果的计算:
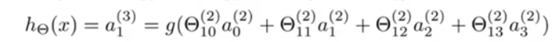
- 可以发现算法是一毛一样的,只是输入的features发生了改变。
-
上面进行的讨论中只是将特征矩阵中的一行(一个训练实例)喂给了神经网络,我们需要将整个训练集都喂给我们的神经网络算法来学习模型。我们可以知道:每一个都是由上一层所有的和每一个所对应的决定的。
- 我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION )
-
相对于使用循环来编码,利用向量化的方法更加适合快速处理大量的数据。
-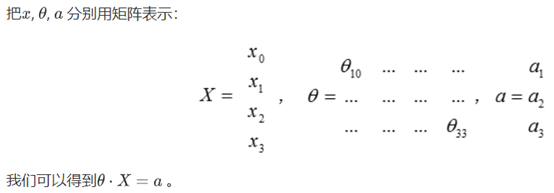
-
实例图片:
-
对于上图由第一层计算第二层的值:
- 大体过程:
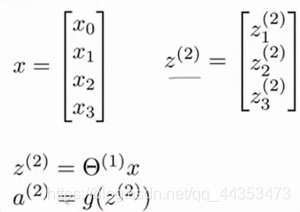
- 详细步骤:
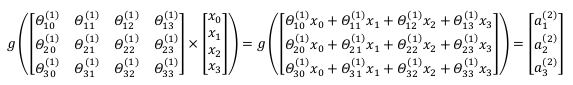
- 大体过程:
-
由第二层计算第三层的值:
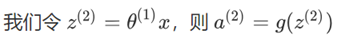
得到的结果为:

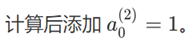
下一步:

详细步骤:
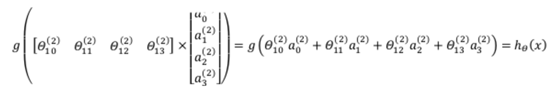
-
-
从这两步我们可以清晰的发现,事实上两步操作都是运行的 Logistic function 。只是在从第二层映射到第三层的时候,除了theta集换成了新的theta集之外,变量 X 也已经不是普通的 X 了,而是新的 a ,a 是由变量 x 经过 Logistic function 梯度下降后得到的,变得越来越厉害,所以这些更高级的特征值远比仅仅将x次方厉害,也能更好的预测新数据。 这就是神经网络相比于逻辑回归和线性回归的优势。

- Examples and Intuitions(实例和直观理解)
-
Idea:
- 从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征下X(1),X(2)···X(n) ,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
-
Examples
- 神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。
- 二元逻辑运算符(BINARY LOGICAL OPERATORS)当输入特征为布尔值(0或1)时,我们可以用一个单一的激活层可以作为二元逻辑运算符,为了表示不同的运算符,我们只需要选择不同的权重即可。
- 我们可以利用神经元来组合成更为复杂的神经网络以实现更复杂的运算。按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。这就是神经网络的厉害之处。
19
- Multiclass Classification(多类分类)
Part 9:神经网络的学习(Neural Networks: Learning)
在人工智能领域,每一个输入到神经网络的数据都被叫做一个特征。由这些特征组成的向量被称为特征向量。数据大部分都是以特征向量的形式输入到神经网络中的。
我们一直在讲的 learning 实际上是我们要找到特定的权重偏置,从而使得代价函数最小化。这样子才能做到预测的功能。
一个星期没学习,全玩了。。要不得要不得。 --19.8.11
- Cost Function(代价函数)
-
代价函数
- 在逻辑回归问题中我们的代价函数经过正则化之后已经发生了变化,变成了这样:
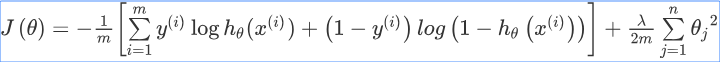
- 普通逻辑回归问题与神经网络的对比
- 输入的变量都可以是多个,即多个下x,多个权重
- 但是一般的逻辑回归问题只会有一个因变量y,并且这个y也就是最终要求得的结果
- 对于神经网络的逻辑回归问题,它的因变量的数量是不确定的,可以是一个更多的时候是多个。
- 在上面的式子中h(x)是一个多维度的向量,并且它产生的因变量是一个同样维度的向量。
注:
此处联想前面所学,h(x)是激活函数,它里面的就是变量是**z(x)是一个向量,产生的a(x)**注定是一个相同维度的向量。
- 在逻辑回归问题中我们的代价函数经过正则化之后已经发生了变化,变成了这样:
-
经过改进产生了神经网络的逻辑回归函数:
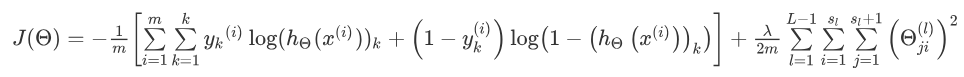
- 在最后面的正则化项所算的只是排除掉每一层的theta0之后的每一层的theta矩阵之和。最里层的循环j循环所有的行(由 s(l)+1 层的激活单元数决定),循环i则循环所有的列,由该层(**s(l)**层)的激活单元数所决定。即:**h(x)**与真实值之间的距离为每个样本-每个类输出的加和,对参数进行regularization的bias项处理所有参数的平方和。
- 至于内部的1~k的积分的作用是求出每一层各个激活单元的误差函数的和作为该层的 Cost function 的值
- Backpropagation Algorithm(反向传播算法)
- 前向传播算法:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









