






Redis
简介
Redis是基于Key-value模式的高性能NoSql(Not Only Sql)数据库,NoSql是为了解决性能问题而产生的技术,主要是解决CPU、内存、IO的压力。
问题:为什么Redis是单线程,但性能高?
- 基于内存操作
- 使用IO多路复用模型
- 高效的数据存储结构
- 不同数据类型底层有多种数据结构
整个Redis底层的数据存储机构,是一张全局的Hash表(Hash表:由一维数组 + 二维链表组成,时间复杂度是常量级别)

分析两条命令底层的操作
set k1 v1
get k1
set k1 v1 底层执行过程:
- Hash(k1):对K1进行hash运算,得到散列值
- Hash(k1) % 一维数组Size,得到取模值
- 根据模值定位到一维数组中的元素,将K1、V1存到该元素后面指针的链表上
get k1 底层执行过程:
- Hash(k1):对K1进行hash运算,得到散列值
- Hash(k1) % 一维数组Size,得到取模值
- 根据模值定位到一维数组中的元素,在链表上比对key值,取出value
键操作命令
| 命令 | 注释 |
|---|---|
| type key | 查看当前key对应值的数据类型 |
| object encoding key | 查看当前key对应值的底层数据结构 |
数据类型(针对Value而言)
常见的数据类型
String字符串
常用命令
| 命令 | 注释 | 备注 |
|---|---|---|
| set k1 v1 | ||
| get k1 | ||
| incr/decr k1 | value±1 | 原子性操作,只针对数字值 |
| incrby/decrby k1 10 | value±N |
Redis 是用 C 语言开发的,Redis 的字符串并非使用 C字符串
为什么不使用C字符串?
C语言中字符串的表示:
char str[] = "abcd";// 系统自动加上'\0',作为字符串结束的标志
// 存储"ab\0cd"
char str[] = "ab";
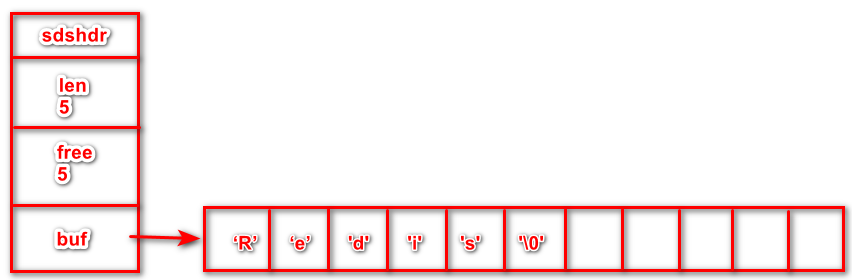
简单动态字符串SDS
Redis 自定义一种被称为 简单动态字符串SDS 的结构体来保存字符串,SDS全称:Simple Dynamic String
// 结构体
struct sdshdr{
// 记录字符数组中已使用字节的数量,即字符串长度,作为字符串结束的标志
int len;
// 记录buf数组中未使用字节的数量,即剩余空间的大小
int free;
// 字符数组,用于保存字符串
char buf[];
}
SDS结构图示:
Redis字符串相较于C字符串的优点:
-
常数时间内获得字符串长度
C字符本身不记录长度信息,遍历整个字符串获取长度,时间复杂度未O(n)
Redis字符串通过len属性,可直接获取字符串的长度,时间复杂度是O(1),(获取命令为:strlen key)
-
二进制安全(可以转换成String存储的,还可以转换回来)

原因:C字符串以’\0’作为字符串结束的标志,Redis字符串根据len来判断字符串有没有结束(图片等二进制文件,内容可能包括’\0’字符) -
采取预分配冗余空间、惰性空间释放的方式,减少字符串修改时的内存分配
例如:s1= “abcd” —“abcdef”
C字符串修改时,会重新分配一块内存空间
空间预分配:
Redis字符串扩容时:
-
len值 < 1M:
- 计算len、分配与len相同长度的未使用空间
- buf长度 = len + free(len) + 1byte

-
len值 > 1M:
- 分配1M未使用空间
- buf长度 = len + free(1M) + 1byte
注:一个Redis中的字符串value值最多存512M
惰性空间释放:
对字符串进行缩短操作时,程序不会回收多余的内存空间
-
-
兼容C语言、函数库(数据存储以’\0’空字符结尾,以兼容C语言)
底层数据结构
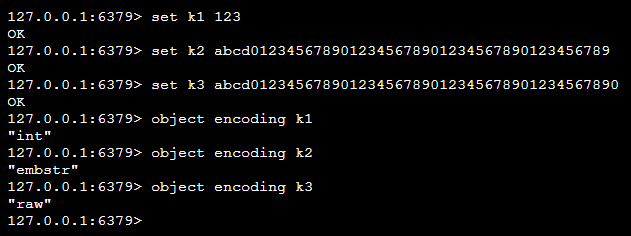
- int:使用整数值实现的字符串对象
- embstr:使用embstr编码的SDS实现的字符串对象
- raw:使用SDS实现的字符串对象
编码转化
对于String类型的键值,根据存储值的不同,Redis底层采用不同的编码
-
整型,采用 int 类型的编码
-
非整型,且value ≤ 44字节,采用 embstr 编码
-
非整型,且value > 44字节,采用 raw 编码
List列表
常用命令
| 命令 | 注释 | 备注 |
|---|---|---|
| lpush/rpush k1 v1 v2 v3 | 从左/右边插入一/多个值 | |
| lrange k1 0 -1 | 按索引下标查询元素(从左向右) | |
| lpop/rpop k1 | 从左/右边吐出一个值 |  吐完就消失 |
底层数据结构
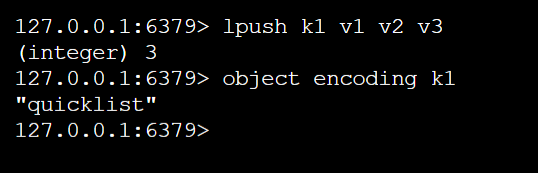
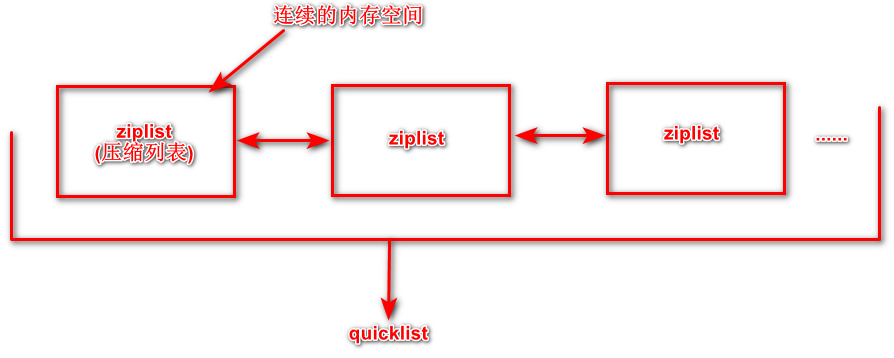
- quicklist:使用快速链表实现的列表对象
quicklist(快速链表)是由多个ziplist(压缩列表)使用双向指针串起来构成
快速链表的优点:
- 具有压缩列表的优点,内存利用率高
- 具有双向链表的优点,方便插入、删除操作
- 相较于普通链表而言更节省空间,普通链表有附加指针,prev、next
Set集合
常用命令
| 命令 | 注释 | 备注 |
|---|---|---|
| sadd k1 v1 v2 v3 | 添加多个member元素到集合key | 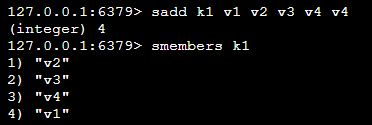 已存在的member元素会被忽略 |
| smembers k1 | 取出该集合的所有值 | |
| sismember k1 v1 | 判断集合中是否含有指定value值 | 有返回1、没有返回0 |
| scard k1 | 返回集合中元素的个数 | |
| spop k1 | 随机从集合中吐出一个值 | 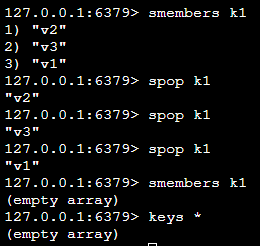 吐完就消失 |
底层数据结构
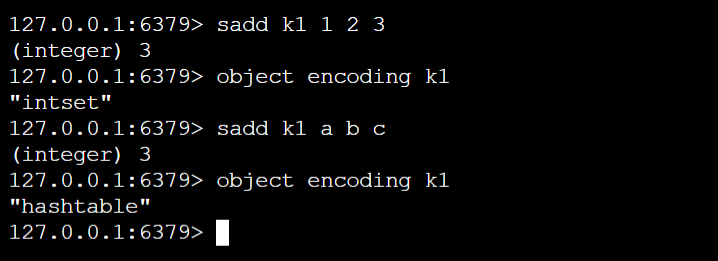
- intset:使用整型数组实现的集合对象
typedef struct intset {
// 编码方式:决定contents数组的类型
uint32_t encoding;
// 集合中包含的元素数量,即contents数组的长度
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
- hashtable:使用哈希表实现的集合对象
编码转化
对于Set类型的键值,根据存储值的不同,Redis底层采用不同的编码
-
当 Set 对象同时满足以下两个条件时,对象采用 intset 编码
- 存储的所有元素均为整型
- 存储的元素个数 < 512个
第二个条件可在配置redis.conf中进行修改
set-max-intset-entries 512 -
否则,采用hashtable类型的编码
Zset有序集合
常用命令
| 命令 | 注释 | 备注 |
|---|---|---|
| zadd k1 100 v1 90 v2 80 v3 70 v4 | 将一/多个元素及scroe值加入有序集合中 | |
| zrange k1 0 -1 | 取出指定下标之间的值(从小到大排序) | 0代表第一个值,-1代表倒数第一个值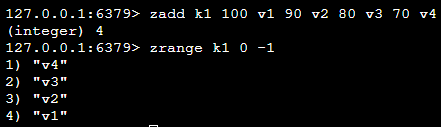 |
| zrangebyscore k1 70 90 | 取出指定评分之间的值(从小到大排序) | 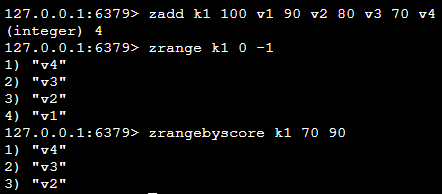 |
| zrevrangebyscore k1 90 70 | 取出指定评分之间的值(从大到小) | 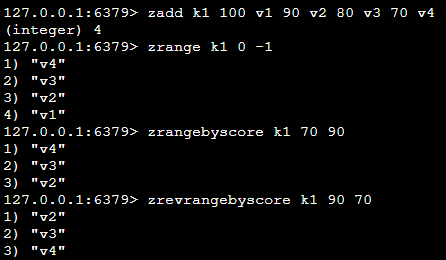 |
| zinrby k1 10 v4 | 针对指定value增加指定值 | 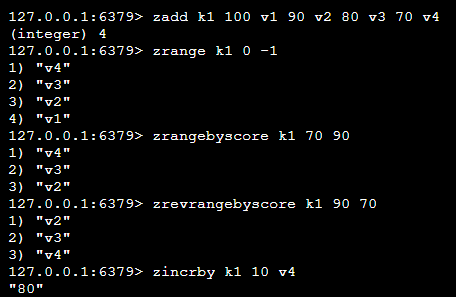 |
| zrem k1 v4 | 删除集合中指定value | |
| zcount k1 70 90 | 统计集合中在指定评分之间的元素个数 | |
| zrank k1 v1 | 返回指定value在该集合中的排名 | 排名从0开始 |
底层数据结构
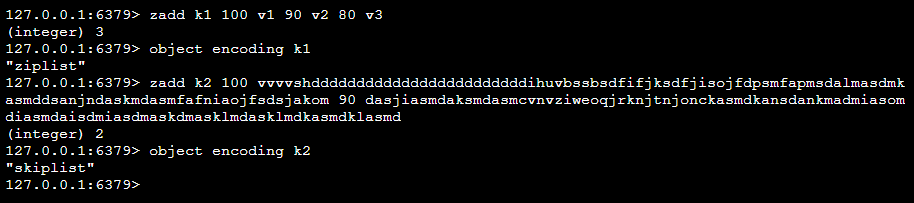
-
ziplist:使用压缩列表实现的有序集合对象
ziplist(压缩列表)是由一系列特殊编码的连续内存块组成的顺序存储结构,类似于数组
ziplist在内存中是连续存储的,ziplist中的每个元素(称为节点entry)所占的内存大小可以不同,每个节点可以用来存储一个整数或者一个字符串
ziplist是为了提高内存的存储效率而设计的
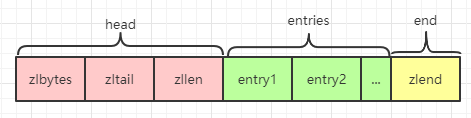
属性 长度 描述 zlbytes 4字节 记录压缩列表占用的内存字节数(包括本身所占用的4个字节) zltail 4字节 记录压缩列表尾节点距离压缩列表的起始地址有多少个字节(通过这个值可以计算出尾节点的地址) zllen 2字节 记录压缩列表中包含的节点数量 entry - 压缩列表中的各个节点,长度由存储的实际数据决定 zlend 1字节 特殊字符0xFF(十进制255),用来标记压缩列表的末端 -
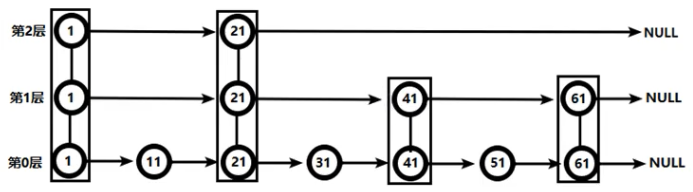
skiplist:使用跳跃表实现的有序集合对象
有序链表:

跳跃表:选取有序链表一半的节点用来建索引
编码转化
对于Zset类型的键值,根据存储值的不同,Redis底层采用不同的编码
-
当 Zset 对象同时满足以下两个条件时,采用 ziplist 编码
-
存储的元素个数 < 128 个
-
所有元素的长度均 < 64 字节
注:这二个条件可在配置redis.conf中进行修改
zset-max-ziplist-entries 128 zset-max-ziplist-value 64 -
-
否则,采用 hashtable 编码
Hash哈希表
常用命令
| 命令 | 注释 | 备注 |
|---|---|---|
| hset k1 f1 v1 f2 v2 f3 v3 | 给key集合中的filed键赋值(可以批量) |  |
| hsetnx k1 f4 v4 | 给key集合中的filed键赋值(不可以批量) | 仅当filed(域)不存在时,可插入成功 |
| hkeys k1 | 取出该hash集合的所有field | |
| hvals k1 | 取出该hash集合的所有value | |
| hget k1 f1 | 取出hash集合中指定field的value | |
| hexists k1 f1 | 判断hash集合中指定field的value是否存在 |
底层数据结构
-
ziplist:使用压缩列表实现的哈希对象
-
hashtable:使用哈希表实现的哈希对象
编码转化
对于Hash类型的键值,根据存储值的不同,Redis底层采用不同的编码
-
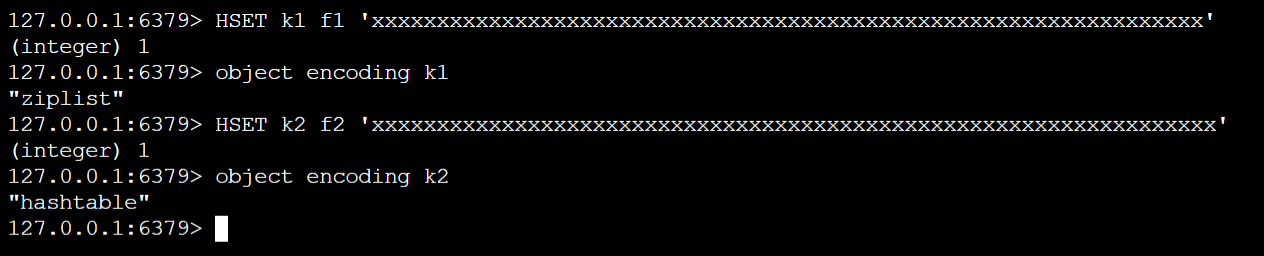
当 Hash 对象同时满足以下两个条件时,采用 ziplist 编码
-
Hash 对象保存的键值对数量 < 512 个
-
Hash 对象保存的所有键值对的键和值的字符串长度均 < 64 字节
注:这二个条件可在配置redis.conf中进行修改
hash-max-ziplist-entries 512 hash-max-ziplist-value 64 -
-
否则,采用 hashtable 编码

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









