







redis概括
2019年11月14日
15:27
1.什么是redis
nosql,key-value,基于内存,实现缓存,可持久化,非关系型,数据库(数据库读写)
nosql: not only structrued query language 不支持结构化查询语句,redis存储的是数据结构不是表格
key-value: redis存储的数据基本结构,value数据类型5种,String,hash,set,list,zset
基于内存: redis 运行速度快,最大支持上限每秒万条数据,在内存处理数据
实现缓存:

较少了调用层次的是数量,提升线程的处理速度,系统的并发能力提高,可持久化
memorycache,类似于redis缓存数据库
| redis | memoryCache |
| 支持五种value | String |
| 支持持久化(容灾雪崩) | 不支持(容易造成容灾雪崩) |
| redis单实例,单线程 | 多线程,稍快于redis |
网络访问redis 的瓶颈不是限制在技术上,而是限制在网络传输通道上
雪崩:
如果从一个长期运行的系统,使用redis,缓存数据过多,如果突然缓存故障(内存数据丢失,down机),导致海量访问的请求涌向数据库,数据库承受不住----宕机----重启,海量请求并未消失,所以在缓存技术数据恢复之前,系统宕机不可用----雪崩(并发请求)
持久化:
缓存使用数据在内存,为了保证宕机数据不丢失,在运行期间使用持久化机制将内存数据存储在磁盘上,可以在技术启动时重新加载磁盘数据.
雪崩,持久化,数据未命中(缓存数据丢失时)
非关系型;
关系型数据库: oracle mysql sqlserver
非关系型数据库: redis memoryCache MongoDB
处理的数据结构: key---value(map对象存储)
2.redis可以做什么
五种数据类型有关,可以实现缓存,可以实现分布式锁,其他负载功能(计步器,共同好友,排行榜)
redis的安装
2019年9月22日
9:45
1.获取安装包解压
1.1安装包redis-3.2.11.tar.gz在/home/resources
操作习惯 /home/software文件夹安装所有的软件
[root@10-9-39-13 ~]# mkdir /home/software
1.2将安装包解压到指定目录
将安装包拷贝到software等待解压
[root@10-9-39-13 ~]# cp /home/resources/redis-3.2.11.tar.gz /home/software/
将software下的tar包使用tar命令解压
[root@10-9-39-13 software]# tar -xf redis-3.2.11.tar.gz

2.编译安装
redis包中大量了src源码,需要编译,并且执行编译安装使用脚本文件,否则必须到src中寻找脚本命令
2.1运行make插件
在redis的根目录执行/home/software/redis-3.2.11
[root@10-9-39-13 redis-3.2.11]# pwd
/home/software/redis-3.2.11
执行编译和编译安装命令
[root@10-9-39-13 redis-3.2.11]# make && make install

redis的安装就完毕了
3.默认方式的启动和登录使用
结构和数据库的服务,客户端登录一样的
3.1通过命令脚本运行一个redis服务
默认占用的端口6379
[root@10-9-39-13 /]# redis-server
3.2使用脚本实现客户端登录
默认访问6379
[root@10-9-39-13 ~]# redis-cli
127.0.0.1:6379>
显示默认登录的服务器是127.0.0.1:6379
3.3关闭服务端和退出客户端
127.0.0.1:6379>shutdown 关闭服务
127.0.0.1:6379>quit 退出客户端
redis基础命令和五种数据类型
2019年11月14日
16:15
1.五种数据类型
redis支持内存中的hashMap处理数据,在value的结构中存在不同情况,不同功能准备的5中不同的类型
String : 字符串
Hash: 面向对象的结构
List: 双向链表
Set: 集合
zSet: 有序集合
2.操作命令
基础命令: 对key值的管理,才能实现对数据的增删查改(记住exists del expire ttl)
- key pattern(*)
查看想要的匹配到的所有的key值,如果pattern=*,查看当前redis内存中所有的key数据
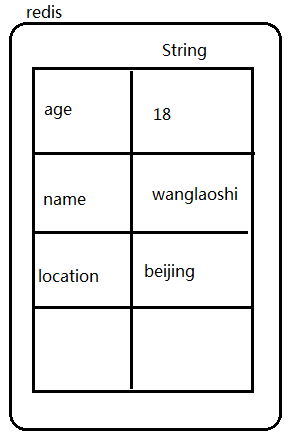
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> get age
"18"
127.0.0.1:6379> set name wanglaoshi
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379>
127.0.0.1:6379> keys na*
1) "name"
127.0.0.1:6379>
- del key值 根据key删除任意类型的value数据
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> keys *
1) "age"
127.0.0.1:6379>
- exists key值 判断一个key是否存在
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379>
判断一个key-value中的key是否存在于内存数据,也可以使用get
127.0.0.1:6379> get age
"18"
127.0.0.1:6379> get alfasld
(nil)
127.0.0.1:6379>
exists判断一个key是否存在时,没有对key的value进行读取,只是使用类似contain方法,但是get是将key的value读取过来的,redis最新版本中可以支持value最大存储数据的1GB,exists判断效率更高
- save
将内存数据以rdb持久化模式存储到一个rdb文件中,默认情况这个持久化文件dump.rdb在redis根目录
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> save
OK
127.0.0.1:6379>
日志文件中出现数据持久化的提示
28822:M 20 Aug 17:14:33.215 * DB saved on disk
默认情况是根目录一个dump.rdb文件保存持久化数据
[root@10-9-39-13 redis-3.2.11]# ll dump.rdb
-rw-r--r-- 1 root root 93 Aug 20 17:20 dump.rdb
默认大小是77字节,保持了一个基本结构;
只要存在dump.rdb,server启动时会自动加载,从中恢复磁盘数据
设计一种结构,定时的调用save命令保证数据的完整
- flushall
将内存数据中的数据,和dump文件的数据全部清空,在测试环境旧
数据不影响新数据测试的情况下可以使用,测试环境/生产环境决不允许执行
127.0.0.1:6379> set name haha
OK
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> save
OK
127.0.0.1:6379>
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379>
- flushdb
select 0-15整数:redis默认情况下,会在内存中划分16个数据库区域,相互之间数据是隔离的,可以通过select 整数选择使用不同的区域,默认的是0号库
127.0.0.1:6379[15]> select 1
OK
127.0.0.1:6379[1]> set name haha
OK
127.0.0.1:6379[1]> set location shanghai
OK
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379>
3.0版本之前,没有redis-cluster的结构,这种隔离的分库常用来做数据分片操作,不同的分片可以实现分布式存储,redis-cluster技术结构出现后,全部默认使用0号库就足够了;
flushdb:db指的就是0-15号分库,清空分库中内存数据,dump持久化文件不受影响(flushall>>flushdb)
很多环境中不确定要不要清除数据(flushall),又要实现数据的不冲突,就可以使用flushdb,如果清除错误,可以通过持久化文件恢复
- expire key值 时间值(秒)
对一个已有的key-value进行超时的处理.永久数据超时时间-1,过期数据超时时间-2.时间灵敏度秒,保持对内存的合理使用127.0.0.1:6379> set name haha
OK
127.0.0.1:6379> ttl name
(integer) -1
127.0.0.1:6379> expire name 50
(integer) 1
127.0.0.1:6379> ttl name
(integer) 46
127.0.0.1:6379> ttl name
(integer) 45
127.0.0.1:6379>
- ttl key值
查看一个key的超时时间剩余时间,秒为单位
127.0.0.1:6379> ttl name
(integer) 1
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379>
- pexpire key值 时间值(毫秒)
- pttl key值
查看一个key的超时时间剩余,毫秒为单位
- type key值
127.0.0.1:6379> type name
string
127.0.0.1:6379> lpush list01 1
(integer) 1
127.0.0.1:6379> type list01
list
127.0.0.1:6379>
- help 命令:查看一个redis命令的usage
127.0.0.1:6379> help set
SET key value [EX seconds] [PX milliseconds] [NX|XX]
summary: Set the string value of a key
since: 1.0.0
group: string
一般命令的使用到官网查看
String类型
- set: 新增/覆盖(写操作)
- get: 读取数据(读取操作)
- incr/decr : 自增自减 可以对String类型中数字的数据进行自增自减操作(+1,-1)
127.0.0.1:6379> set num 100
OK
127.0.0.1:6379> incr num
(integer) 101
127.0.0.1:6379> decr num
(integer) 100
应用场景: 程序中变动的数字,上下变动+1,-1,投票软件操作
- incrby/decrby: 自增,自减,自己定义增加家减少的量
127.0.0.1:6379> incrby num 10
(integer) 110
127.0.0.1:6379> decrby num 20
(integer) 90
127.0.0.1:6379>
应用场景: 在线人数
- append: 追加,修改的一种; set可以修改,覆盖数据,将已有的数据重新覆盖写了一遍,追加速度比覆盖高
127.0.0.1:6379> set location beijing
OK
127.0.0.1:6379> append location yizhuang
(integer) 15
127.0.0.1:6379> get location
"beijingyizhuang"
127.0.0.1:6379>
- mset/mget : 批量操作,批量新增/批量获取
127.0.0.1:6379> mset name1 wang name2 liu name3 wu
OK
127.0.0.1:6379> keys *
1) "name3"
2) "name1"
3) "name2"
127.0.0.1:6379> mget name1 name2 name3 name4
1) "wang"
2) "liu"
3) "wu"
4) (nil)
127.0.0.1:6379>
效果和多次执行set/get相同,但是速度快,只占用带宽传输一次
String类型的应用场景就是实现缓存,通过对象的json字符串作为String类型的value,提供数据读写工作缓存
Hash类型(记住hget,hset,hexists)
是面向数据结构,面向对象的处理数据的结构方式

hset key field value

利用hash结构存储一个数据,可以使用hset key值,属性值,属性value
127.0.0.1:6379> hset user age 18
(integer) 1
127.0.0.1:6379> hset user name wang
(integer) 1
127.0.0.1:6379>
- hget key field 读取一个hash结构中某个属性的值
127.0.0.1:6379> hget user name
"wang"
127.0.0.1:6379> hget user age
"29"
127.0.0.1:6379> hget user location
(nil)
127.0.0.1:6379>
- hmset/hmget 批量操作
127.0.0.1:6379> hmset student age 18 studentNum 25536 studentName wang
OK
127.0.0.1:6379> hmget student age studentNum studentName
1) "18"
2) "25536"
3) "wang"
127.0.0.1:6379>
- hkeys/hvals 分别获取属性名称的返回集合,与属性值的返回集合
127.0.0.1:6379> hkeys student
1) "age"
2) "studentNum"
3) "studentName"
127.0.0.1:6379> hvals student
1) "18"
2) "25536"
3) "wang"
127.0.0.1:6379>
- hlen 获取一个hash类型数据中所有属性的个数
127.0.0.1:6379> hlen user
(integer) 2
127.0.0.1:6379> hlen student
(integer) 3
127.0.0.1:6379>
- hdel(del的区别: 一个是删除key-value,一个是删除hash中属性) 删除某个属性和属性值
127.0.0.1:6379> hdel user age name
(integer) 2
127.0.0.1:6379> keys *
1) "name3"
2) "name1"
3) "name2"
4) "student"
- hincrby key field 步数
对于hash数据中纯数字的数据做内存操作的自增(没有自减)
hash的应用场景,也可以实现对象的缓存处理,但是代码和结构比String复杂,如果偏向于对数据存储的结构紧密(hash),造成编码调用命令的复杂
List(lpush/rpush,lpop.rpop,lrange)
双向链表,特点,头尾操作速度快,中间的操作速度慢,有排序,分为上(左)(头)/下(右)(尾)
- lpush/rpush list的key值,元素值 从头或者为插入数据
127.0.0.1:6379> lpush list01 100 200 300 400 500
(integer) 5
127.0.0.1:6379> rpush list01 one two three four five
(integer) 10
- lrange list的key值,起始下标 结束下标(如果查看全部 0 -1)
127.0.0.1:6379> lrange list01 0 -1
1) "500"
2) "400"
3) "300"
4) "200"
5) "100"
6) "one"
7) "two"
8) "three"
9) "four"
10) "five"
127.0.0.1:6379>
- linsert Linsert key before|After pivot value
对一个list数据做插入元素操作.只能从上到下对比数据,pivot参数元素,value插入的数据,before|after在参数元素的前面还是后面进行数据写入
127.0.0.1:6379> lrange list02 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> linsert list02 after one 100
(integer) 4
127.0.0.1:6379> linsert list02 before one 200
(integer) 5
127.0.0.1:6379>
127.0.0.1:6379> lrange list02 0 -1
1) "three"
2) "two"
3) "200"
4) "one"
5) "100"
- lrem 删除 lrem key count value
由于List链表中元素的值可以重复,删除元素时需要携带删除的个数,
count=正整数,0,负整数
正整数: 从头向尾部循环找相同元素个数删除
负整数: 从尾到头寻找相同元素个数删除
0:全删
127.0.0.1:6379> lrange list03 0 -1
1) "200"
2) "100"
3) "200"
4) "100"
5) "200"
6) "100"
127.0.0.1:6379> lrem list03 2 100
(integer) 2
127.0.0.1:6379> lrange list03 0 -1
1) "200"
2) "200"
3) "200"
4) "100"
127.0.0.1:6379> lpush list04 100 200 100 200 100 200
(integer) 6
127.0.0.1:6379> lrem list04 -2 100
(integer) 2
127.0.0.1:6379> lrange list04 0 -1
1) "200"
2) "100"
3) "200"
4) "200"
127.0.0.1:6379> lrem list04 0 200
(integer) 3
127.0.0.1:6379> lrange list04 0 -1
1) "100"
127.0.0.1:6379>
- ltrim 保留一定范围内的元素值,其他都删除
127.0.0.1:6379> lrange list01 0 -1
1) "500"
2) "400"
3) "300"
4) "200"
5) "100"
6) "one"
7) "two"
8) "three"
9) "four"
10) "five"
127.0.0.1:6379> ltrim list01 0 4
OK
127.0.0.1:6379> lrange list01 0 -1
1) "500"
2) "400"
3) "300"
4) "200"
5) "100"
127.0.0.1:6379>
- lpop/rpop
从头部/尾部删除一个元素,将删除的数据返回,作用是取得List头和尾的数据
127.0.0.1:6379> lrange list01 0 -1
1) "500"
2) "400"
3) "300"
4) "200"
5) "100"
127.0.0.1:6379> lpop list01
"500"
127.0.0.1:6379>
- llen 查看元素的个数(List长度)
127.0.0.1:6379> lrange list01 0 -1
1) "400"
2) "300"
3) "200"
4) "100"
127.0.0.1:6379> llen list01
(integer) 4
127.0.0.1:6379>
- lset 按照下标,修改元素的值
127.0.0.1:6379> lrange list01 0 -1
1) "400"
2) "300"
3) "200"
4) "100"
127.0.0.1:6379> lset list01 2 two
OK
127.0.0.1:6379> lrange list01 0 -1
1) "400"
2) "300"
3) "two"
4) "100"
127.0.0.1:6379>
两个list之间的操作(用来做消息队列确认机制)
- rpoplpush list1 list2 从第一个list尾部删除一个元素并且把删除的元素插入到第二个list 头部
127.0.0.1:6379> lrange list01 0 -1
1) "400"
2) "300"
3) "two"
4) "100"
127.0.0.1:6379> lrange list02 0 -1
1) "three"
2) "two"
3) "200"
4) "one"
5) "100"
127.0.0.1:6379> rpoplpush list01 list02
"100"
127.0.0.1:6379> lrange list02 0 -1
1) "100"
2) "three"
3) "two"
4) "200"
5) "one"
6) "100"
127.0.0.1:6379>
set类型(sisremember)
没有排序,不允许元素重合,一个集合的数据结构

- sadd key 元素值 向集合中添加数据
127.0.0.1:6379> sadd favor math english
(integer) 2
- srem key member 删除元素
127.0.0.1:6379> sadd favor math english history
(integer) 3
127.0.0.1:6379> srem favor math
(integer) 1
127.0.0.1:6379> srem favor math
(integer) 0
- scard key 返回集合中的元素个数
127.0.0.1:6380> scard favor
(integer) 2
- sismemeber key element 判断元素是否在指定的集合中
127.0.0.1:6380> sismember favor histroy
(integer) 0
127.0.0.1:6380> sismember favor math
(integer) 1
127.0.0.1:6380>
- srandmember key 在结合中随机抽取几个元素
127.0.0.1:6380> sismember favor math
(integer) 1
127.0.0.1:6380> srandmember favor 1
1) "math"
127.0.0.1:6380> srandmember favor 1
1) "english"
- smember key 获取指定集合的所有元素
127.0.0.1:6380> sadd favor english histry
(integer) 2
127.0.0.1:6380> smembers favor
1) "english"
2) "histry"
3) "math"
127.0.0.1:6380>
集合间的操作
- sinter set1 set2 交集
127.0.0.1:6380> sadd favor1 english histroy math
(integer) 3
127.0.0.1:6380> sadd favor2 english math chinese
(integer) 3
127.0.0.1:6380> sinter favor1 favor2
1) "english"
2) "math"
127.0.0.1:6380>
- sunion set1 set2 并集
127.0.0.1:6380> sunion favor1 favor2
1) "english"
2) "chinese"
3) "histroy"
4) "math"
127.0.0.1:6380>
- sdiff set1 set2 差集 属于set1属于set2的的元素为差集
127.0.0.1:6380> sdiff favor1 favor2
1) "histroy"
127.0.0.1:6380> sdiff favor2 favor1
1) "chinese"
127.0.0.1:6380>
ZSet结构(sorted set)
在集合的基础上绑定了一个score作为排序依据,比较典型的适用场景就是排行榜系统,如视频网站需要对用户上传的视频做排行榜

单集合(集合内)
- zadd key score member 添加成员
127.0.0.1:6380> zadd result 10 xiaolaoshi
(integer) 1
127.0.0.1:6380> zadd result 20 wanglaoshi
(integer) 1
127.0.0.1:6380> zadd result 30 chenlaoshi
(integer) 1
127.0.0.1:6380>
- zcard key 计算成员个数 同set
- zscore key member 获取某个成员的分数
127.0.0.1:6380> zadd result 30 chenlaoshi
(integer) 1
127.0.0.1:6380> zscore result chenlaoshi
"30"
127.0.0.1:6380> zadd result 40 chenlaoshi
(integer) 0
127.0.0.1:6380> zscore result chenlaoshi
"40"
127.0.0.1:6380>
- zrank key member 计算成员的排序(升序,数值越大,排序越高)
127.0.0.1:6380> zrank result xiaolaoshi
(integer) 0
127.0.0.1:6380> zrank result wanglaoshi
(integer) 1
127.0.0.1:6380>
- zrem key memeber 删除成员
127.0.0.1:6380> zrem result wanglaoshi
(integer) 1
127.0.0.1:6380> zrank result wanglaoshi
(nil)
127.0.0.1:6380>
- zincrby key increment member 增加成员的分数
127.0.0.1:6380> zincrby result 50 xiaolaoshi
"60"
127.0.0.1:6380>
- zrange key start end 返回指定排名范围的成员
127.0.0.1:6380> zrange result 0 1
1) "chenlaoshi"
2) "xiaolaoshi"
127.0.0.1:6380>
- zrange key min max 返回指定分数范文的成员
- zcount key min max 返回指定分数范围的成员个数
- zremrangebyrank key start end 删除指定排名内的升序元素
集合间的操作
zset数据中所有的交集并集的操作,是将结果输出到一个新的集合中

交集: zinsterstore destinationtion numkeys key
destination: 新的zset集合
numkeys : 求交集,并集的个数
key: 所有的zset集合
127.0.0.1:6380> zadd result1 10 xiao
(integer) 1
127.0.0.1:6380> zadd result1 20 wang
(integer) 1
127.0.0.1:6380> zadd result2 30 xiao
(integer) 1
127.0.0.1:6380> zadd result2 40 wang
(integer) 1
127.0.0.1:6380> zinterstore out1 2 result1 result2
(integer) 2
127.0.0.1:6380> zrange out1 0 -1 withscores
1) "xiao"
2) "40"
3) "wang"
4) "60"
127.0.0.1:6380>
并集: zunionstore destionation numkeys key
java的redis客户端jedis
2019年9月22日
14:50
1.搭建redis的3个节点的分布式集群
1.1默认的redis-server不允许外界访问
开启外界的访问,使用window客户单连接redis节点
1.2单机使用的优化
如果作为redis节点,只在一个服务器启动一个进程
单进程 单线程的软件不足以使用到服务器的有效资源上限,一般都会在一个服务器3-10个redis节点
1.3redis的配置文件
配置文件模板 redis的根目录 redis.conf
通过配置这个文件,启动redis服务,加载这个文件(redis服务就会按照我们在文件中配置的内容启动,例如端口号 6379,6380,6381)
vim 编辑器打开文件(备份一份)
- 16行

不区分大小写,可以在redis配置文件中使用的单位
- 61行

bind 127.0.0.1 客户端只能通过127.0.0.1访问当前redis服务端(外界不能访问),注释掉,只要外界能访问当前服务器(不管使用什么ip)都允许访问
- 80行

关闭保护模式,除了本机客户端,对外界客户端访问一旦开启保护模式,即使能连接redis服务也不能操作,推荐你配合一个登陆密码来设置(关闭保护模式,开启访问密码) requirepass
- 84行

当前redis服务端启动使用的端口号
- 128行

开启,后台守护进程,redis-server启动就会在后台运行,所有日志将会输出到一个自定义的日志文件中
- 150行

记录了server运行程序的pid值的文件,与端口号有关
- 163行

会在redis根目录在启动server时生成该名称的log文件,记录的就是后台守护运行时输出的所有日志(一旦出现任何启动运行的问题,查看日志文件)
- 202行

持久化的执行save策略.数据变动(写)越频繁,存储持久化的时间短.
900秒内,数据至少变动一次
300秒内,数据至少变动10次
60秒内,数据至少变动1万次
- 237行

对应的save调用命令的输出持久化文件,不同redis节点对应不同的持久化文件,数据不互通
- 546行淘汰策略
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# noeviction -> don't expire at all, just return an error on write operations
数据在redis中可以指定使用的淘汰策略:mysql数据库中2000万条数据,redis能存储200万条,如何保证redis中200万条绝大多数都是热点数据(经常被访问的数据).
答案:使用redis中数据淘汰策略为lru (最近最久未使用)
volitle-**:对设置了超时时间的数据
random:对设置了超时的数据达到内存上限使用的情况下进行随机删除
ttl:到达上限时,把将要过期的数据删除(谁剩余的时间越少,删除的可能性越大)
lru:在超时数据中设置内部的时间戳,根据时间戳判断最近最久未使用(热点保留,冷点删除)
allkeys-**:对永久数据的淘汰策略
random:随机淘汰
lru:最近最久未使用淘汰
内存上限需要redis中配置


1.5配置启动3个节点
6379 6380 6381
- 拷贝redis.conf 生成三个配置文件
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6379.conf
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6380.conf
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6381.conf
- 修改6380 6381的与端口有关的配置
port
pid文件
log文件
dump文件
vim的替换命令
:%s/替换原值/替换值/g

:%s/6379/6380/g
:%s/6379/6381/g
- 各自启动redis6370 6380 6381
redis-server 配置文件名称
[root@10-9-39-13 redis-3.2.11]# redis-server redis6379.conf
[root@10-9-39-13 redis-3.2.11]# redis-server redis6380.conf
[root@10-9-39-13 redis-3.2.11]# redis-server redis6381.conf
- ps查看进程
ps -ef|grep redis
[root@10-9-39-13 redis-3.2.11]# ps -ef|grep redis
root 22595 1 0 15:55 ? 00:00:00 redis-server *:6379
root 22607 1 0 15:55 ? 00:00:00 redis-server *:6380
root 22625 1 0 15:55 ? 00:00:00 redis-server *:6381
root 22653 4538 0 15:56 pts/1 00:00:00 grep redi
2 jedis客户端
依赖redis的jedis客户端依赖资源maven工程
(springboot的简化依赖)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
EASYMALL-USER子工程实现redis测试代码
2.1如何使用jedis连接redis操作命令(api方法)
/*使用jedis创建一个连接对象,操作6379
*/
@Test
public void connection(){
Jedis jedis=new Jedis("10.9.39.13", 6379);
//jedis可以连接到10.9.39.13:6379
//redis-cli -h(host) 10.9.39.13 -p(port)6379
/*jedis.hset(key, field, value);
jedis.hmset(key, hash);
jedis.sadd(key, members);*/
jedis.set("name", "王老师");
System.out.println(jedis.get("name"));
}
常见问题:
1 提示connection refused
原因:host,port填错了/redis-server没启动
2 提示connection denied
redis.clients.jedis.exceptions.JedisDataException: DENIED Redis is running in protected mode because protected mode is enabled
解决办法:
确定启动加载的配置文件中的protected-mode no
重新确定,重新启动
2.2实现登录逻辑
当可以用jedis连接redis的某个节点实现set get方法时,就相当于代码已经可以将数据读写从redis
登录结构图:

- 登录身份校验
接收到参数user对象(userName.userPassword)
业务层处理逻辑
- 读取数据库数据(select * from t_user where user_name=#{name} and user_password=#{password})
- 判断返回值existUser
- null:说明登录失败 按失败处理
- 不是null;
- 生成即将存储在redis的key(计算逻辑,保证不同用户key值不一样.保证同一个用户登录时间不同key值也不一样.)
- jedis setex(ticket,60*60*2,userJson)
- 返回使用过的ticket值
- 控制层使用ticket 放到cookie中返回浏览器
- 接口文件
| 后台接收 | /user/manage/login |
| 请求方式 | Post |
| 请求参数 | User user 只有用户名和密码,查询需要加密password |
| 返回数据 | 返回SysResult对象的json,其结构: Integer status; 200表示成功,其他表示失败 String msg;成功返回 “ok”,失败返回其他信息 Object data;根据需求携带其他数据 |
| 备注1 | 需要使用redis存储查询到的user数据,并且利用cookie传递回浏览器,以便下次访问携带cookie完成用户状态的请求 COOKIE的名称EM_TICKET |
| 备注2 | Redis存储的用户数据,ticket生成公式:”EM_TICKET”+currentTime+userId;value就是userJson |
| 备注3 | 可以利用这里的登录逻辑,控制一个用户最多的登录个数 |
UserController
//登录功能
@RequestMapping("login")
public SysResult doLogin(User user,HttpServletRequest
req,HttpServletResponse res){
//通过业务层返回的数据 ticket是否为空判断
//登录逻辑是否正常 "" 正常值
String ticket=userService.doLogin(user);
if("".equals(ticket)){
//登录失败
return SysResult.build(201, "", null);
}else{
//ticket不为空,说明登录成功
//返回成功信息之前,要在cookie中定义一个携带ticket的key值
//的头信息 EM_TICKET
CookieUtils.setCookie
(req, res, "EM_TICKET", ticket);
return SysResult.ok();
}
}
UserService
public String doLogin(User user) {
//判断登录权限校验 select where user_name and password
//加密
user.setUserPassword(
MD5Util.md5(user.getUserPassword()));
User exist=
userMapper.selectUserByUserNameAndPassword(user);
String ticket="";
//判断对象是否存在
if(exist==null){
//登录失败
return ticket;
}else{
//登录成功
//生成ticket redis的key,生成value userJson
//ticket生成公式:”EM_TICKET”+currentTime+userId;
ticket="EM_TICKET"
+System.currentTimeMillis()+exist.getUserId();
Jedis jedis =new Jedis("10.9.39.13",6379);
try{
String userJson=
MapperUtil.MP.writeValueAsString(exist);
//设置超时存储
jedis.setex(ticket, 60*60*2, userJson);
}catch(Exception e){
e.printStackTrace();
return "";
}finally{
jedis.close();
}
//存储在redis,将ticket返回
return ticket;
}
}
- 登录的信息获取
浏览器客户端访问了一次登录的接口,浏览器保存了返回的cookie EM_TICKET js会在每次访问easymall系统时从cookie中判断ticket值是否为空,不为空说明至少曾经登录过一次,都会发起请求到用户系统的第二个接口访问
获取ticket值,业务层用jedis 读取userJson按照要求的格式返回给ajax,判断是否超时,null /不null
- 接口文件
| 后台接收 | /user/manage/query/{ticket} |
| 请求方式 | Get |
| 请求参数 | String ticket 就是用户登录时生成的rediskey值 |
| 返回数据 | 返回SysResult对象的json,其结构: Integer status; 200表示成功,其他表示失败 String msg;成功返回 “ok”,失败返回其他信息 Object data;封装从redis获取的userJson |
| 备注 | 可以在这个逻辑中完成续租用户登录状态的逻辑的续租 |
UserController
@RequestMapping("query/{ticket}")
public SysResult queryTicket(@PathVariable
String ticket){
String userJson=userService.queryTicket(ticket);
if(userJson==null){//超时2个小时
return SysResult.build(201, "用户超时", null);
}else{
//登录状态可用
return SysResult.build(200,
"登录状态可用", userJson);
}
}
UserService
jedis对象直接去redis获取数据
public String queryTicket(String ticket) {
Jedis jedis=new Jedis("10.9.39.13",6379);
try{
return jedis.get(ticket);
}catch(Exception e){
e.printStackTrace();
return null;
}finally{
jedis.close();
}}
3.登录功能的业务逻辑缺陷
3.1登录能顶替?
顶替逻辑的数据结构
3.2登录突然超时
续约
jedis客户端测代码
2019年11月15日
19:21
1.数据分片的计算
1.1user功能正在使用的redis的结构
单节点的redis提供了user系统的数据处理能力
- 物理瓶颈上限很有限: 一个节点的内存是不够的
- 一旦宕机: 用户登录逻辑彻底完蛋
1.2内存容量上限
可以通过横向扩展解决实现总体容量的扩容

再使用一定的计算逻辑处理数据的切分存储的过程后,每个节点都会保存整体数据的一部分

数据分片: 当使用分布式结构处理数据时,最终形成多个节点处理的数据是整体的一部分------这一部分就是数据的分片
数据分片切分逻辑: 来第一条给第一个节点,第二条给第二个节点,第三条给第三个节点,第四条给第一个及诶到哪(物理平均的切分算法),这种形成切分目的的计算逻辑就是数据分片算法;与hash取余/hash取模有关 在jedis中使用的hash一致性
1.3hash取余的分片计算方法
模拟系统生成大量的key-value
hash取余的计算公式: (hash.hashCode()&Integer.MAX_VALUE)%N
key : 生成的业务逻辑对应的redis的key
key.hashCode() : Object的方法hashCode() , 结果是可正可负,int范围内的整数
key.hashCode()&Integer.MAX_VALUE : 一个整数(可正可负)和31个1做位的与运算(保真31位预算),会将前面的可正可负的整数二进制保留后31位.第一位永远是0,导致取正运算,计算结果是正整数
(key.hashCode()&Integer.MAX_VALUE)%N : N为节点个数
最后结果:
0---> 第一个节点
1---->第二个节点
2----->第三个节点
n-1 ------> 第n个节点
结论:
- key的取值只要是java的Object类型就可以对应一个[0,n-1]区间的整数
- key值不变(equals方法判断条件不变),取值结果不变
测试代码
@Test
public void hashN(){
//模拟生成大量的数据,存储6379 6380 6381
//准备3个连接对象
Jedis jedis1=new Jedis("10.9.39.13",6379);
Jedis jedis2=new Jedis("10.9.39.13",6380);
Jedis jedis3=new Jedis("10.9.39.13",6381);
for(int i=0;i<100;i++){
String key="key_"+i;
String value="value_"+i;
int result=(key.hashCode()&Integer.MAX_VALUE)%3;
if(result==0){//6370
jedis1.set(key, value);
}else if(result==1){
//6380
jedis2.set(key, value);
}else{
//6381
jedis3.set(key, value);
}}}
2.jedis客户端封装的数据分片的对象ShardedJedis
jedis客户端可以通过传递的所有节点信息,封装一个分片对象,这个分片对象对底层jedis实现了set,get,exists,expire的分片计算方法的封装
测试代码:
@Test
public void shardedJedis(){
//使用jedis客户端实现将大量数据存储在6379 6380 6381
//收集的所有节点
List<JedisShardInfo> list=new ArrayList<JedisShardInfo>();
list.add(new JedisShardInfo("10.9.39.13", 6379));
list.add(new JedisShardInfo("10.9.39.13", 6380));
list.add(new JedisShardInfo("10.9.39.13", 6381));
//通过节点信息 创建分片对象
ShardedJedis sJedis=new ShardedJedis(list);
sJedis.set("name", "liulaosih");
System.out.println(sJedis.get("name"));
}
3.hash一致性
分布式结构中常用的分片计算方法,
3.1hash取余分片计算redis当前结构中的问题
导致集群扩容,缩容时数据的迁移量过大,不迁移就会造成数据未命中过大(雪崩---缓存崩溃,海量请求涌向数据库)

当集群节点越多的时候,hash取余算法的结果: 扩容,缩容时数据未命中的概率范围越大
3.2hash一致性
- hash一致性是目前分布式分片计算方法中比较流行的一种算法,基于一种hash散列计算(CRC16计算),将内存数据映射到整个区间 0-43(2^31-1)亿
- hash一致性能够解决hash取余在扩展时扩容缩容时的数据迁移量过大的问题
3.3hash一致性的具体原理
- hash环
基于hash散列算法得到的0-43亿整数区间 ------hash环

- jedis实现的hash一致性
利用提供的节点信息做hash环的对应整数映射,利用节点信息"10.9.39.13:6379"

- key值和节点对应寻找原则
key值做hash散列计算得到整数映射结果

key值的整数顺时针寻找最近的节点整数做对应关系,上图映射结果
6379 : key 2,4,6
6380 : key 1,5
6381: key 3
- hash环的扩容

本来应设在6379处理的数据,key6由于扩容10001,迁移到10001,当节点越多时,映射切分的整数环弧线越小,导致迁移的数据越少
hash取余扩容: 节点越多,迁移量越大
hash一致性: 节点越多迁移量越小,小到一定程度是,这种未命中微不足道
- 数据平衡性权重
jedis通过引入虚拟节点概念10.9.39.13:6379:真实节点信息,模拟生成大量的虚拟节点,与真实的节点有相关关系
10.9.39.13:6379#1:6379第一个虚拟节点(虚拟出一个与真实节点字符串有关的不同字符串
)
10.9.39.13:6379#2
10.9.39.13:6379#3
10.9.39.13:6379#4

key值在引入虚拟节点的hash环上依然顺时针寻找对应的节点整数,一旦对应虚拟节点,就会将虚拟节点的真实节点作为处理者绑定key-node的对应关系
- 如何使用虚拟节点完成权重
jedis在创建分片对象封装hash一致性时,将虚拟节点设置为160*weight; weight默认值是1
总结点:
基础: hash散列计算,把内存数据映射到0-43整数区间,对象不变,结果不变
key-node对应关系:
node映射整数,key映射的整数,key的整数顺时针寻找最近节点整数平衡性和权重
虚拟节点 : 与真实节点信息有关的假的节点(可以实现hash一致性的计算)
jedis实现160*9weight权重个虚拟节点
4.分片连接池测试代码
@Test
public void pool(){
//收集节点信息
List<JedisShardInfo> list=new ArrayList<JedisShardInfo>();
list.add(new JedisShardInfo("10.9.39.13", 6379));
list.add(new JedisShardInfo("10.9.39.13", 6380));
list.add(new JedisShardInfo("10.9.39.13", 6381));
//使用连接池的配置对象,配置连接池的各种属性
//最大空闲,最小空闲,最大连接数量...
GenericObjectPoolConfig config=
new GenericObjectPoolConfig();
config.setMaxIdle(8);
config.setMinIdle(3);
config.setMaxTotal(200);
//list config 构造一个包装了多个分片连接对象的连接池对象
ShardedJedisPool pool=
new ShardedJedisPool(config, list);
//从池子中获取连接资源
ShardedJedis sJedis = pool.getResource();
sJedis.set("location", "北京");}
5.springboot整合分片连接池
使用spring框架维护当前连接池对象的ioc,注入到需要的位置使用,一个框架容器只存在一个连接池对象
5.1做一个配置类
@configuration 所在的类相当于一个xml配置文件
import org.springframework.context.annotation.Configuration;
@Configuration
public class PoolConfigRedis {
}
5.2读取属性
配合配置类,使用@configurationProperties(prefix="redis.1906"),配置类自动读取application.properties文件已redis.1906开头的属性的值,并把值传入到对应的属性中
@Configuration
@ConfigurationProperties(prefix="redis.1906")
public class PoolConfigRedis {
private List<String> nodes;
//10.9.39.13:6379,10.0.39.13:6380,10.9.39.13:6381
private Integer maxTotal;
private Integer maxIdle;
private Integer minIdle;
getter&&setter
}
application.properties文件
#集群节点信息
redis.1906.nodes=10.9.39.13:6379,10.9.39.13:6380,10.9.39.13:6381
#最大连接数
redis.1906.maxTotal=200
#最大空闲数
redis.1906.maxIdle=8
#最小空闲数
redis.1906.minIdle=3
5.3初始化对象(ShardedJedisPool)
利用@configurationProperties读取的属性创建一个分片连接池对象
@Bean 返回值对象交给spring管理
public ShardedJedisPool initShardPool(){
//收集节点信息
List<JedisShardInfo> list=
new ArrayList<JedisShardInfo>();
for (String node : nodes) {
//node="10.9.39.13:6379"
String host=node.split(":")[0];
int port=Integer.
parseInt(node.split(":")[1]);
list.add(new JedisShardInfo(host,port));
}
//配置连接池对象
GenericObjectPoolConfig config=new
GenericObjectPoolConfig();
config.setMaxIdle(maxIdle);
config.setMaxTotal(maxTotal);
config.setMinIdle(minIdle);
return new ShardedJedisPool(config,list);
}
5.4user登录功能版本二
注入分片连接池对象
@Autowired
private ShardedJedisPool pool;
public *** 方法(){
ShardedJedis jedis = pool.getResource();
try{
****
}catch(Exception e){
e.printStackTrace();
return null;
}finally{
pool.returnResource(jedis);
}
}
高可用集群
2019年11月15日
20:56
1.单个节点分布式集群的问题.
存在单个节点故障,导致集群不可用的问题,当前分布式结构,单节点结构不是高可用
2.哨兵机群
2.1高可用结构

- 主从结构的故障转移: 主节点宕机,从节点顶替
- 主从的数据备份: 主从关系一旦搭建,从节点时刻备份主节点的数据(高可用的基础 mycat,es均是)
2.2redis的主从数据复制
redis支持一主多从.支持多级主从

主从结构过于复杂会导致数据备份的不稳定.建议一级主从,一个主节点多个从节点
2.3实现一主二从的主从结构
- 准备一主二从的配置文件
- 6382主节点
- 6383,6384从节点
拷贝redis.conf的模板文件,修改与端口有关的相关内容
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6382.conf
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6383.conf
[root@10-9-39-13 redis-3.2.11]# cp redis.conf redis6384.conf
批量更改端口
:%s/6379/6382/g
:%s/6379/6383/g
:%s/6379/6384/g
- 启动三个从节点,观察主从状态
[root@10-9-39-13 redis-3.2.11]# redis-server redis6382.conf
[root@10-9-39-13 redis-3.2.11]# redis-server redis6383.conf
[root@10-9-39-13 redis-3.2.11]# redis-server redis6384.conf
ps-ef|grep redis查看是否启动成功
调用:
info replication
- 调用命令挂接主从
登录到节点,执行挂接命令: slaveof 主节点ip 主节点端口号
127.0.0.1:6384> slaveof 10.9.39.13 6382
- 测试验证:
- 数据同步
主节点中新增数据,观察从节点是否能读取数据
- 从节点写入数据
默认情况从节点是只读 read-only
- 故障转移
杀掉主节点进程,观察两个从节点状态
- 结论: 主节点,从节点只关心主从的任务,没有故障转移替换的机制,高可用结构单独使用主从复制无法完成
2.4哨兵进程
- 介绍: 哨兵进程是一个单独的,特殊的redis进程,和redis-server相互独立运行,可以实现对主从结构的监听和管理,实现主从的故障转移
- 原理
- 监听原理: 初始化访问主节点,调用info命令从主节点获取所有的从节点信息,维护在内存中进行监控管理,所有节点的状态都会通过哨兵机制进行维护
- 心跳机制: 每秒钟通过rpc(远程通信协议)心跳检测访问集群的所有节点,一旦发现细条响应是空的,达到一定时间判断节点故障宕机
- 投票机制: 主节点宕机,选举一个从节点为新的主节点,通过管理的权限,将这个节点转换为master,将集群中其他节点挂接到这个新的主节点,必须通过投票完成(哨兵也是集群),必须过半,投票结果才能被执行,否则将会进入到重新判断循环

3.哨兵集群
三个哨兵节点,监控一个一主二从的主从结构
3.1哨兵的配置文件
- 17行关闭保护模式
- 21行26379 26380 26381
- 69行配置监听的主节点和哨兵相关内容
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel monitor:哨兵监控主节点的关键字
mymaster:自定义的字符串,表示监听的一个主从结构的代号
ip:主节点的ip(外界访问的ip)
port:主节点的端口
2:主观下限票数.哨兵集群中的有效节点最少2个

3.2启动三个哨兵进程
前提: 主从结构正常运行
- 拷贝模板文件为三分
[root@10-9-39-13 redis-3.2.11]# cp sentinel.conf sentinel01.conf
[root@10-9-39-13 redis-3.2.11]# cp sentinel.conf sentinel02.conf
[root@10-9-39-13 redis-3.2.11]# cp sentinel.conf sentinel03.conf
- 修改各自的端口26380 26381
略
- 启动哨兵进程观察日志
redis-sentinel sentinel01.confg
31075:X 23 Sep 16:25:38.208 # Sentinel ID is 190f21c802fceceba93288c422c1c7ddd249f6f9
31075:X 23 Sep 16:25:38.208 # +monitor master mymaster 10.9.39.13 6382 quorum 2
31075:X 23 Sep 16:25:38.209 * +slave slave 10.9.39.13:6384 10.9.39.13 6384 @ mymaster 10.9.39.13 6382
31075:X 23 Sep 16:25:38.216 * +slave slave 10.9.39.13:6383 10.9.39.13 6383 @ mymaster 10.9.39.13 6382
3.3故障转移测试
- 宕掉主节点6382观察哨兵日志
发现宕机的从节点
发起投片选举6383,6384中的一人为新主节点顶替工作
剩余的其他节点重新挂接到新的主节点上
- 原主节点服务挂机到从节点执行主从功能,
6382节点的配置文件决定了它的角色是master,哨兵会对6382做监控管理
将其转换为从节点
3.4jedis可以连接哨兵访问主从集群
@Test
public void sentinel(){
//收集哨兵节点信息,连接哨兵获取集群master-slave的使用信息
//给一个哨兵,指定多个,会从中挑选一个可连接的节点使用
Set<String> sentinels = new HashSet<String>();
sentinels.add(new HostAndPort("10.9.39.13",26379).toString());
sentinels.add(new HostAndPort("10.9.39.13",26380).toString());
//哨兵连接池
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels);
System.out.println("现役master:" + pool.getCurrentHostMaster());
Jedis jedis = pool.getResource();
jedis.set("name", "刘老师");
System.out.println(jedis.get("name"));
pool.returnResource(jedis);
pool.destroy();
System.out.println("ok");
}
3.5哨兵集群的分布式结构
jedis无法实现哨兵的分布式,因为hash一致性计算已经固定(但是可以基于它结构的修改hash一致性算法)

redis-cluster结构和特性
2019年11月16日
16:37
1.redis-cluster结构
哨兵集群redis技术只能负责解决高可用问题,但是实现分布式比较浪费资源,分布式计算比较复杂,需要根据搭建的结构实现不同的分布式hash一致性的重写过程
redis3.0版本reids出现了最终支持高可用分布式同时存在redis-cluster

2.特性
2.1基础-两两互联
集群中节点与节点,部分角色两两互联,底层内部二进制通信协议,优化传输速度(同步集群相关信息的速度)
2.2 哨兵逻辑整合到master
集群中最小的master数量是3,哨兵的进程逻辑被整合到master节点中,集群的高可用监听逻辑由master执行,投票由过半的master决定,因为基础两两互联,master才能实现相互监听管理
2.3客户端连接一个节点获取集群所有的信息
客户端基于两两互联,实现一个从节点,获取集群所有节点的内容(可以实现jedisCluster代码高可用)
2.4槽道实现key和节点的松耦合
- hash slot: redis-cluster集群中有新分片计算的逻辑,hash槽,底层计算(key.CRC16()%16384)key值会对应到一个槽道号[0,16383],master可以管理一批不同 的槽道,实现key-->slot-->node
- 槽道使用特性: 客户端连接集群任意一个节点,发送处理数据的命令,会计算key值对应的槽道号,找到管理槽道号的节点,通知客户端转发redirect
redis-cluster的搭建
星期日,2019年8月25日
10:13
1.集群搭建的最终结构

三个主节点,最终各自有一从的cluster高可用分布式结构
2.搭建的环境
初步搭建cluster集群,需要使用ruby的语言编写的脚本redis-trib.rb 在redis根目录src文件夹中;需要配置ruby语言的环境(tomcat运行,需要在jdk环境),镜像中,ruby环境是安装完成的.
[root@10-9-104-184 ~]# ruby -v
ruby 2.3.1p112 (2016-04-26 revision 54768) [x86_64-linux]
[root@10-9-104-184 ~]#
如果使用的是自行购买的云主机环境,不需要ruby环境也可以将集群搭建完毕
插入
yum -y install make cmake tcl* gcc
ruby() ruby-gems gem-redis
2.1准备配置文件(过程和我一致,我会提供重启,重搭脚本)
- 将模板文件redis.conf拷贝成redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# cp redis.conf redis-cluster.conf
- 将redis-cluster.conf(6379为端口信息填写配置,后续修改端口)
之前配置的protected-mode bind daimonize dump logfile都报纸原样
- 593行/597行配置第二种持久化方式

| rdb | aof | 对比 |
| 记录的数据是key-value name wanglaoshi | 开启的日志文件记录的整个执行的命令 set name wanglaoshi | 运行模式:set name wanglaoshi |
| 比较小 | 比较大 | 文件大小 |
| 单独开启rdb才加载 | aof优先级比rdb大 | redis-server加载顺序 |
| 缺点: 会在宕机时造成数据的丢失更多 优点: 批量操作,效率更高,小数据量时使用rdb效率比aop高 2倍以上的效率 | 优点 数据同步时间接近实时(默认每秒同步);数据备份可靠性高,丢失数据少 缺点: 同步的实时性,增加redis-server的压力 | 优点和缺点 |
| 需要一定的数据恢复能力,不要求数据可靠性极强(数据恢复时,越全可靠性越高);数据量不大的情况可以选择rdb | 对数据的可靠性要求极高,可以使用aof,在aof模式下,最多丢失2秒的数据. | 使用场景 |

总结rdb aof
- 存储数据结构,rdb 存数据 aof 日志命令
- 优先级加载 aof高(数据恢复更全面)
- 使用场景:优缺点 aof 可靠性(恢复的越全面,持久化的可靠性约到)
- 721行开启集群模式
在集群模式的节点中才会引入槽道的逻辑,普通的redis节点不具备计算槽道的原理的.无法实现集群的搭建

- 729行集群节点的状态记录文件

- 启动查看是否是以集群形式启动
2.2 准备启动的文件夹
- 创建文件夹
将3主定义为8000 8001 8002 ,三从 8003 8004 8005,为了维护每个启动的配置文件redis-cluster.conf,在redis的根目录创建一批文件夹
[root@10-9-104-184 redis-3.2.11]# mkdir 8000 8001 8002 8003 8004 8005
- 将模板文件拷贝到给子的文件夹中redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8000
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8001
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8002
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8003
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8004
[root@10-9-104-184 redis-3.2.11]# cp redis-cluster.conf 8005
[root@10-9-39-13 redis-3.2.11]# ls -R 800*
8000:redis-cluster.conf
8001:redis-cluster.conf
8002:redis-cluster.conf
8003:redis-cluster.conf
8004:redis-cluster.conf
8005:redis-cluster.conf
- 修改端口号为8000-8005
:%s/6379/8000/g
:%s/6379/8001/g
:%s/6379/8002/g
:%s/6379/8003/g
:%s/6379/8004/g
:%s/6379/8005/g
- 启动验证查看
[root@10-9-104-184 redis-3.2.11]# redis-server 8000/redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# redis-server 8001/redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# redis-server 8002/redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# redis-server 8003/redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# redis-server 8004/redis-cluster.conf
[root@10-9-104-184 redis-3.2.11]# redis-server 8005/redis-cluster.conf

2.2集群的简单命令
- 登录集群节点
以cluster的模式登录,才能支持一些cluster的命令执行
#redis-cli -c -p 8000
- 8000>cluster info
查看集群的信息,包含状态,大小size(分片个数),节点个数,信息,逻辑时钟值 epoch
127.0.0.1:8000> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:0
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
127.0.0.1:8000>
- 8000>cluster nodes
查看当前集群所有节点信息;
127.0.0.1:8000> cluster nodes
1e3137131e66c31ef18ec0ea63faf6be5591b4ee :8000 myself,master - 0 0 0 connected
- 结论
启动的6个节点,各自认为自己在一个集群中,而且集群只有自己一个节点,最终集群的两两通信的结构没有搭建
2.3创建第一个集群
8000 8001 8002作为主节点实现一个没有高可用的最小集群创建,需要调用src/redis-trib.rb的脚本文件
- usage使用脚本的结构
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb
Usage: redis-trib.rd <command> <options> <arguments ...>
redis-trib.rb开始的
common:子命令,使用脚本具体要干什么,通过子命令定义,比如CREATE创建集群,reshard重新分片,del-node,add-node
options:子命令选项
arguments:子命令的参数

- 创建集群
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb create 10.9.104.184:8000 10.9.104.184:8001 10.9.104.184:8002

- 登录集群任意一个节点
8000>cluster info
8000>cluster nodes
127.0.0.1:8000> cluster nodes
e485b873945eca28d724e0416bd5b043c326bbf2 10.9.104.184:8002 master - 0 1566703735696 3 connected 10923-16383
ef9ecfffae0cb7e5a707897f1a8ac249aace3b04 10.9.104.184:8001 master - 0 1566703733691 2 connected 5461-10922
1e3137131e66c31ef18ec0ea63faf6be5591b4ee 10.9.104.184:8000 myself,master - 0 0 1 connected 0-5460
127.0.0.1:8000>
节点相关信息会在更新配置后,记录在每一个node文件中,所有的节点启动都会加载这个配置文件node获取集群节点状态
- 体验一下槽道的逻辑
登录8000 [0-5460],set name wanglaoshi
name计算槽道号 5798 不在这个范围
找到8001[5461-10922],redirect到8001
name计算槽道号 5798 在管理范围
直接处理数据 get set
2.4 动态添加主节点
将8003作为一个新增的节点进程添加到集群(8003必须先启动)
add-node的子命令

参数:新节点ip:新节点port 已经存在于集群中的任意节点ip:port
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb add-node 10.9.104.184:8003 10.9.104.184:8002

登录集群查看集群的info和nodes
127.0.0.1:8000> cluster nodes
e485b873945eca28d724e0416bd5b043c326bbf2 10.9.104.184:8002 master - 0 1566704626602 3 connected 10923-16383
ef9ecfffae0cb7e5a707897f1a8ac249aace3b04 10.9.104.184:8001 master - 0 1566704624598 2 connected 5461-10922
1e3137131e66c31ef18ec0ea63faf6be5591b4ee 10.9.104.184:8000 myself,master - 0 0 1 connected 0-5460
3bd8b77749f7a57afa92bd92cdc366767e07ecb0 10.9.104.184:8003 master - 0 1566704627605 0 connected
127.0.0.1:8000>
| 节点id值 | 节点ip:port | 角色(登录人) | 主节点id | 与操作时间有关的值 | 序号 | 连接状态 | 槽道范 围
|
| e485b873945eca28d724e0416bd5b043c326bbf2 | 10.9.104.184:8002 | master | 没有主节点- | 0 1566704624598 | 1 | connected disconnected | 0-5460 |
2.5动态添加一个从节点
8004添加8001成为从节点--add-node,需要2个选项
--slave :表示底层将新节点转化为从节点
--master-id <args>:表示新节点挂接到哪个主节点成为主从关系
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb add-node --slave --master-id ef9ecfffae0cb7e5a707897f1a8ac249aace3b04 10.9.104.184:8004 10.9.104.184:8003
登录查看cluster nodes
7462101c97dbde6ffd75e83b20118266f255ef23 10.9.104.184:8004 slave ef9ecfffae0cb7e5a707897f1a8ac249aace3b04 0 1566713263524 2 connected 作为从节点成为,8001节点的备份使用

2.6高可用能力
数据的备份,主从的故障转移亦然存在,将8001宕机
8004确实作为8001的从节点顶替角色,成为了master
2.7槽道的重新分配(空槽道,5798 7307)
8003作为主节点,可以管理槽道,但是目前8003的槽道是空的.
通过槽道的重新分片定义一部分槽道转交给8003(搭建集群时做的,如果是在运行的集群中,就需要迁移数据了)
reshard 重新分片

执行完命令回答问题,实现槽道的迁移(空)
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb reshard 10.9.104.184:8000
- 迁移槽道数量
How many slots do you want to move (from 1 to 16384)? 200
- 接收槽道200个的节点id是什么
What is the receiving node ID? 8003的id
- 槽道来源节点有哪些
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
第一种:来自所有其他有槽道的节点,200平均分配
Source node #1:all
第二种:自定义指定来自于多个/单个节点
Source node#1:第一个节点id
Source node#2:第二个节点id
Source node#3:done
- 同意计算结果
Do you want to proceed with the proposed reshard plan (yes/no)? yes
2.8节点删除
- 删除节点
redis-trib.rb调用底层del-node命令删除集群中的节点,只能删除从节点,和没有槽道管理权的主节点,这两种节点都不涉及到数据的使用,删除8001,8001本身的节点进程并不知道自己被删除了,所以在删除节点后,立刻将节点关闭,防止8001的计算逻辑继续连接集群造成数据的混乱.
del-node 已存在集群的节点ip:port 删除节点的id
[root@10-9-104-184 redis-3.2.11]# src/redis-trib.rb del-node 10.9.104.184:8003 ef9ecfffae0cb7e5a707897f1a8ac249aace3b04
- 恢复节点出现的问题(当做重启集群的提示)
将8001恢复到集群中--add-node不可以

提示信息两点:
- 8001这个节点非空,database 0里有数据(dump文件多个节点读取同一个),需要将数据清空(删除),删除dump文件重启
- 8001这个节点已经被集群所知道了,就是删除节点之后,想重新添加,8001的node文件中记录了集群信息;
槽道原理
2019年11月18日
10:29
1.槽道原理
2.1集群启动时创建的内存数据
- 启动单个节点(相互之间谁也不与谁通信)

- 将使用ruby调用create两两通信,对象信息相互同步(cluster最大的横向扩展空间)

所以在集群创建后,登录任何一个节点,都可以通过cluster nodes查看整个集群所有节点的信息
2.2槽道结构
集群的槽道结构由2部分组成
- 16384位的二进制(byte[2048]形式驻留在内存)
- 16384个元素的数组(数组中保存的是所有节点对象的引用变量)
每个节点中,都会管理一个2048个元素的byte数组(16384为的二进制),从头到尾赋予下标(位移计算)0-16384,每个下标对应一个槽道号,可以利用槽道号从二进制获取下标对应的二进制的值,1/0,如果是1,表示当前槽道归属true,0表示不归属false

当前集群的主节点创建之初的二进制

16384个元素的数据可以记录0-16384下标的元素值,每个下标对应槽道号,每个节点中通过通信获取二进制,整理使用这个数组,每个元素内容,记录了引用当前槽道号管理者的对象数据

客户端传输命令到节点中,计算分布式hash取模处理数据数据:
- 客户端连接节点发送命令set name haha
- 8000(第一个节点)接收到请求
- 计算槽道(key.CRC16()%16384) ------5798
- 二进制判读对应 下标值是1/0,结果0 false
- 找到数组拿到5798下标元素 8001节点对象变量引用
- ip:port返回客户端重定向
- 8001接收命令set name haha
- 计算槽道 ----5798
- 二进制判断对应下标值1/0 1 true
- redis服务端接收set命令处理
redis补充操作
2018年7月13日 星期五
下午 2:46
1.集群重新搭建
将已经创建的集群.恢复到初始状态
1.1停(停止redis集群的进程)
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8000 shutdown
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8001 shutdown
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8002 shutdown
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8003 shutdown
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8004 shutdown
[root@10-9-100-26 redis-3.2.11]# redis-cli -c -p 8005 shutdown
1.2删(删除持久化文件和配置记录文件)
node文件,dump文件,append文件
[root@10-9-100-26 redis-3.2.11]# rm -f appendonly800*
[root@10-9-100-26 redis-3.2.11]# rm -f dump800*
[root@10-9-100-26 redis-3.2.11]# rm -f nodes-800*
1.3启(启动所有节点)
[root@10-9-100-26 redis-3.2.11]# redis-server 8000/redis-cluster.conf
[root@10-9-100-26 redis-3.2.11]# redis-server 8001/redis-cluster.conf
[root@10-9-100-26 redis-3.2.11]# redis-server 8003/redis-cluster.conf
[root@10-9-100-26 redis-3.2.11]# redis-server 8002/redis-cluster.conf
[root@10-9-100-26 redis-3.2.11]# redis-server 8004/redis-cluster.conf
[root@10-9-100-26 redis-3.2.11]# redis-server 8005/redis-cluster.conf
1.4建(ruby语言脚本创建集群)
使用rb命令脚本直接创建一个三主各自有一从的结构
#src/redis-trib.rb create --replicas 1 六个节点ip:端口
--replicas 1:根据提供的节点,创建一个可用的集群,每个主节点下至少配置一个从节点
2.操作redis的cluster命令完成测试()
2.1手动搭建集群
手动搭建:调用集群命令cluster meet 节点碰撞
注意:手动搭建集群,登录时用-h携带对外访问地址
- 启动节点 8000-8005全启动

- 节点握手
登录任何启动的节点; >cluster meet ip port(ip 端口是其他节点信息)
注意:跨服务器执行集群的搭建,需要登录时使用对外访问ip地址;
[root@10-9-17-153 redis-3.2.11]# redis-cli -c -p 8000 -h 10.9.17.153
10.9.17.153:8000>cluster meet 10.9.17.153 8001
初始化情况下,所有握手的节点都是master 8001属于有数据记录没清干净

添加其他节点到集群(槽道是没有分配的)
10.9.17.153:8000> cluster meet 10.9.17.153 8002
OK
10.9.17.153:8000> cluster meet 10.9.17.153 8003
OK
10.9.17.153:8000> cluster meet 10.9.17.153 8004
OK
10.9.17.153:8000> cluster meet 10.9.17.153 8005
OK
观察集群节点

8000-8002是主节点,8003-8005是从节点
- 先为8000-8002三个主节点分配槽道
- 8000>cluster addslots 槽道号 :可以1个,也可以多个用空格隔开

addslot执行完成后,当前节点和其他节点的共享数组发生变动,0号元素内容替换为8000的节点信息,和其他
所有节点的二进制,除了8000的第0位从0变成1,其他没变化
分配了一个槽道后,查看集群info状态,在16384个槽道全部分配完毕前,fail
分配其他槽道的脚本;这里使用到shell脚本;例如如下脚本内容;
[root@10-9-17-153 redis-3.2.11]# vim slot.sh
for slot in {3..5460};do redis-cli -c -p 8000 cluster addslots
$slot;done;
for slot in {5461..10922};do redis-cli -c -p 8001 cluster addslots $slot;done;
for slot in {10923..16383};do redis-cli -c -p 8002 cluster addslots $slot;done;
redis-cli -c -p 8000 cluster addslots for循环(0 1 2 3 4)
- 执行shell脚本
#sh slot.sh
调用执行shell脚本中的内容,将0-5461槽道挨个添加到当前8000节点中
查看集群节点信息,发现槽道分配完毕

编辑其他两个shell脚本,各自执行脚本,完成 8001(5461-10922) 8002(10923-16383)的槽道分配
对应的shell脚本为
for i in {5462..10922}; do redis-cli -h 10.9.17.153 -c -p 8001 cluster addslots $i;done
for i in {10923..16383}; do redis-cli -h 10.9.17.153 -c -p 8002 cluster addslots $i;done

查看集群状态,ok
>cluster info
2.2从节点的角色转化
利用集群命令cluster来添加的,必须先meet进来
将8003登录,然后调用命令添加为8001的从节点
[root@10-9-17-153 redis-3.2.11]# redis-cli -h 10.9.17.153 -c -p 8003
10.9.17.153:8003> cluster replicate dec454918ff966249a35ee4b2460c61cc09da709(8001id)

8004 8005的操作一样
登录8004,8005,
执行挂接到主节点id的cluster命令
测试集群

总结:redis-trib.rb 命令文件,就是利用ruby语言完成上述步骤的封装;对外提供方便的调用命令;
3.槽道的迁移(数据微调)
3.1空槽道迁移(10923槽道)
- 判断10923是否为空槽道,就是检查10923map的key是否对应一批key值
127.0.0.1:8002> cluster getkeysinslot 10923 500
(empty list or set)
- 目标节点(8001)导入槽道(目标节点中二进制不变, 数组当前槽道的状态变为导入) 正常状态是stable,槽道有四种状态,stable,importing导入状态,migrating导出状态,deleted删除状态
cluster setslot 10923 importing 源节点id
在8001上登录,执行命令,10923就是操作的槽道,importing将8001上的数组的10923元素中的槽道状态修改为导入importing 跟着的是源节点id 8002的id
10.9.17.153:8001> cluster setslot 10923 importing 28d08aa5640c9544c3732551f971ede6bb432210
从8001检查当前集群的节点状态

- 源节点(8002)导出槽道(源节点二进制不变,数组槽道状态变为导出)
登录8002执行迁出操作
cluster setslot 10923 migrating 目标节点id
10.9.17.153:8002> cluster setslot 10923 migrating dec454918ff966249a35ee4b2460c61cc09da709(8001的id)
通过cluster nodes观察到 8002的信息也发生了变化

槽道的状态是正常,导入,导出,都不影响数据的插入
数据微调的时候,集群不能对外提供服务;
数据迁移工作,在维护内容属于重大维护事项;
- 通知所有集群当事人节点槽道迁移了(所有的节点,数组发生变化)
cluster setslot 10923 node 8001节点id 所有集群节点都执行这个操作
将所有集群节点通知到,10923从现在开始,归8001所有
10.9.17.153:8001> cluster setslot 10923 node dec454918ff966249a35ee4b2460c61cc09da709 (8001二进制10923下标的二进制从0变成1,数组变了)
10.9.17.153:8002> cluster setslot 10923 node dec454918ff966249a35ee4b2460c61cc09da709 (8002二进制从1变成0,数组变了)

在8003上执行操作,提示只能再master执行更新
从节点同步主节点的信息,包括数组,和数据的备份
检查集群节点状态

空槽道迁移成功了
3.2非空槽道迁移(reshard命令不支持)
- 判断5798槽道是否非空
127.0.0.1:8001> cluster getkeysinslot 5798 500
1) "name"
按照以上的内容,有数据的槽道可以迁移,但是数组保存着 map{槽道号:[keys]};所以,要迁移非空槽道,需要同步的将数据keys一并迁移;
name 存储在5798上,迁移5798(源节点8001)目标节点8002
- 目标节点导入槽道
10.9.17.153:8002> cluster setslot 5798 importing dec454918ff966249a35ee4b2460c61cc09da709(源节点id)
- 源节点导出槽道
10.9.17.153:8001> cluster setslot 5798 migrating 28d08aa5640c9544c3732551f971ede6bb432210(目标节点id)
- 将槽道的数据迁移到目标节点(登录源节点迁移数据)
- 确定当前槽道包含的所有key(5798)
8001>cluster getkeysinslot 5798 500
查看5798上500个范围内的所有key;
[root@10-9-17-153 redis-3.2.11]# redis-cli -h 10.9.17.153 -c -p 8001 (登录8001)
10.9.17.153:8001> cluster getkeysinslot 5798 5 (获取槽道保存的数组信息)
1) "name"
- 将获取的key值,进行迁移,从8001迁移到8002
8001>migrate 目标节点ip 目标端口 "" 0 500 keys name
10.9.17.153:8001> migrate 10.9.17.153 8002 "" 0 500 keys name
"": 表示key的匹配; 可以使用正则(有待考证)
0: 表示迁移到目标节点的database(0-15)
500:连接超时毫秒
keys:标签确定迁移的key值名称
name:key
如果有多个key:keys name1 name2 name3 name4
除了key-value执行迁移,map记录{槽道:[key集合]}的内容一并迁移
- 所有当事人节点通知更新数据(槽道迁移)
10.9.17.153:8001> cluster setslot 5798 node 28d08aa5640c9544c3732551f971ede6bb432210
10.9.17.153:8002> cluster setslot 5798 node 28d08aa5640c9544c3732551f971ede6bb432210
最后测试

redis集群的命令
2018年2月23日
20:31
集群
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
节点
cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点(保证空槽道)。
cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
cluster saveconfig :将节点的node配置文件保存到硬盘里面。
槽(slot)
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
键
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键
JedisCluster连接集群
2019年9月24日
16:37
1.jedisCluster的使用
jedis客户端针对redis-cluster的结构,单独封装了一套具备访问集群的客户端对象JedisCluster,底层封装了连接池JedisPool,单独计算槽道与节点的对应关系,通过连接集群若干个节点获取整个集群信息,初始化一个可以操作集群的对象
1.1测试代码
实现三主各自一从的rdis-cluster结构,实现操作代码逻辑
@Test
public void jedisCluster(){
//收集节点信息,至少提供一个
Set<HostAndPort> clusterSet=new HashSet<HostAndPort>();
clusterSet.add(new HostAndPort("10.9.39.13",8000));
//cluster对象底层使用连接池,使用config配合连接池属性
GenericObjectPoolConfig
config=new GenericObjectPoolConfig();
config.setMaxTotal(200);
//创建JedisCluster
JedisCluster cluster=
new JedisCluster(clusterSet, config);
cluster.set("name", "王老师");
System.out.println(cluster.get("name"));}















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









