







一个会"记仇"的HashMap
想象你有一个神奇的电话本:
- 普通电话本(HashMap):可以快速找到任何人,但查通话记录时顺序全乱
- 智能电话本(LinkedHashMap):不仅能快速找人,还能记住你查询的顺序
这就是LinkedHashMap的魔力!今天我们就来揭开这个"有记忆功能"的Map实现类的神秘面纱。
一、基础认知:LinkedHashMap是谁?
1. 家族关系图
- 父亲:HashMap(提供高速查找能力)
- 超能力:额外维护了一个双向链表记录插入/访问顺序
2. 核心特点
// 典型创建方式
Map<String, Integer> linkedMap = new LinkedHashMap<>();
linkedMap.put("苹果", 10);
linkedMap.put("香蕉", 5);
linkedMap.put("橙子", 8);
// 遍历时保证顺序!
for (Map.Entry<String, Integer> entry : linkedMap.entrySet()) {
System.out.println(entry.getKey()); // 保证输出:苹果、香蕉、橙子
}
二、底层原理:如何实现"记忆功能"?
1. 数据结构图解
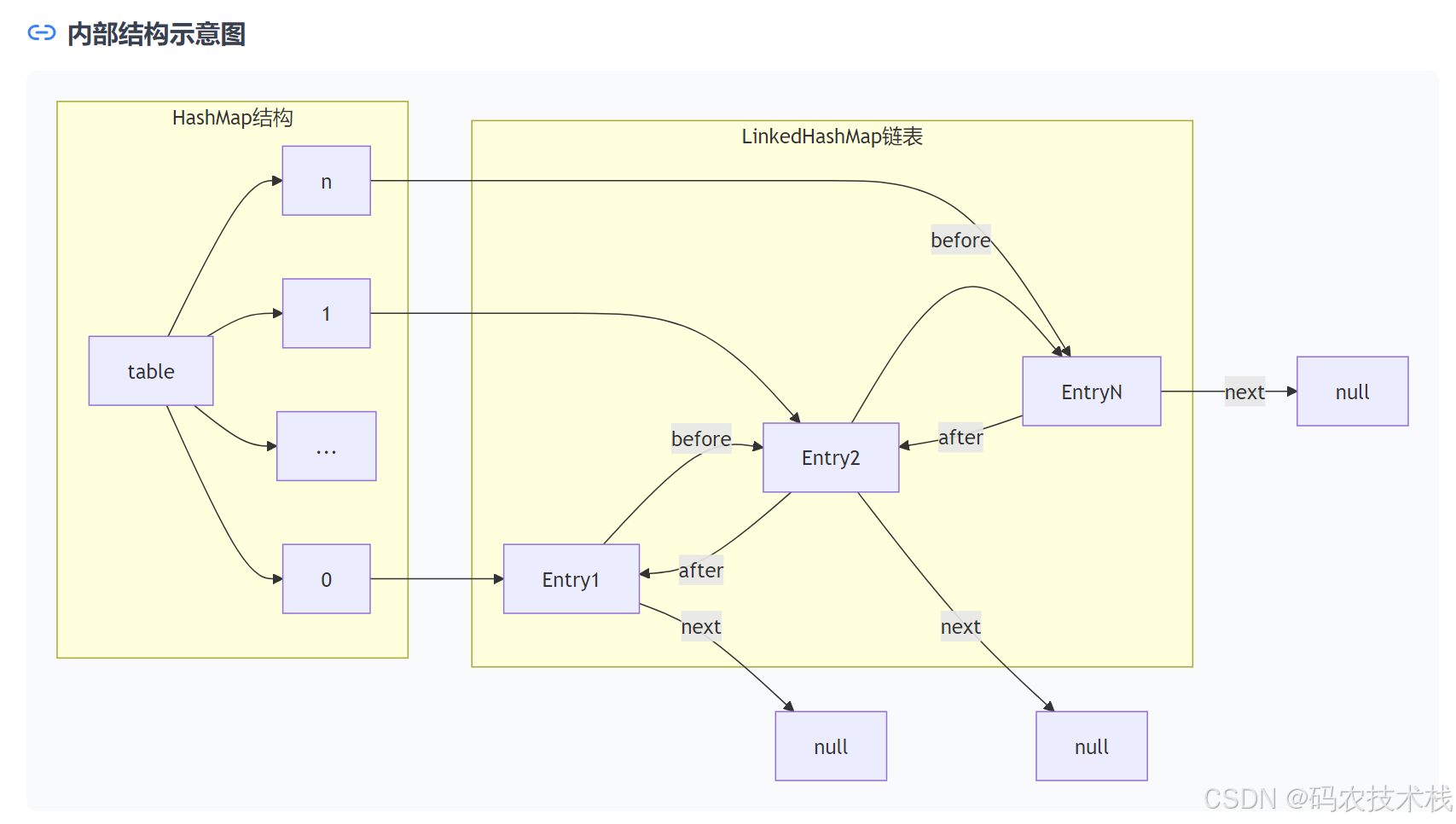

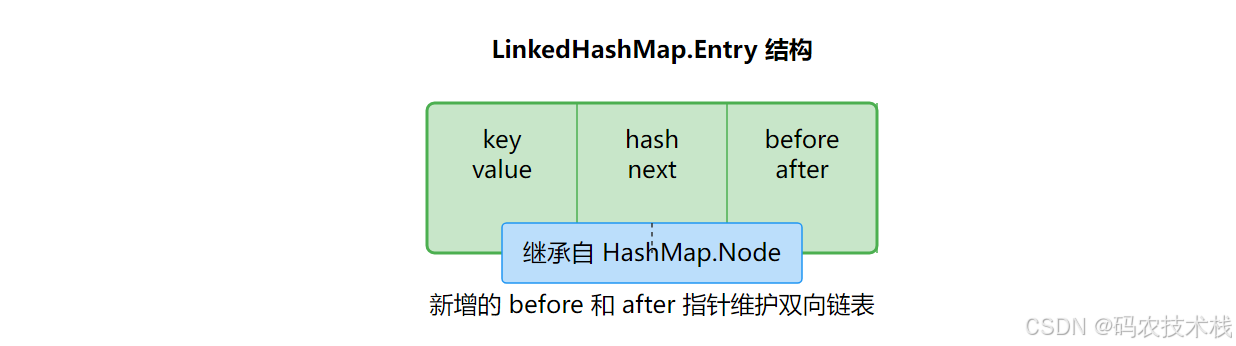
- 哈希表部分:和HashMap一样的数组+链表/红黑树
- 附加魔法:所有节点通过双向链表连接
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 新增的两个指针
}
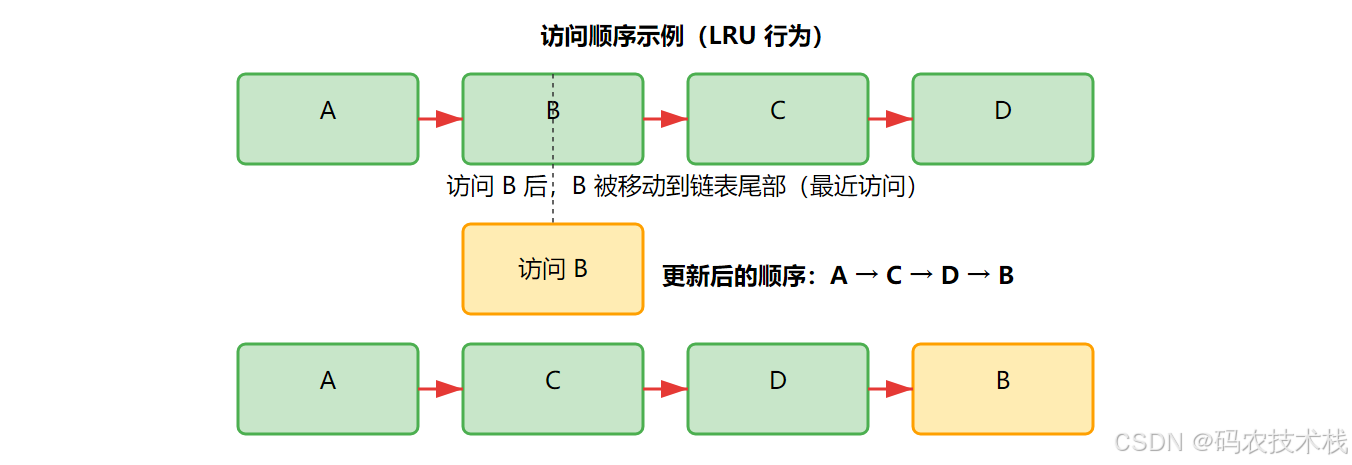
2. 顺序维护的两种模式
| 模式 | 触发条件 | 特点 | 适用场景 |
|---|---|---|---|
| 插入顺序 | 默认模式 | 记录put操作的先后顺序 | 需要保持原始添加顺序 |
| 访问顺序 | 构造器传accessOrder=true | 最近访问的元素移到链表尾 | LRU缓存实现 |
三、性能对比:LinkedHashMap vs HashMap
1. 基本操作对比
| 操作 | HashMap | LinkedHashMap | 差异原因 |
|---|---|---|---|
| 插入(put) | O(1) | O(1) | 需要额外维护链表 |
| 查询(get) | O(1) | O(1) | 访问顺序模式需移动节点 |
| 遍历 | 无序 | 有序 | 链表维护顺序的优势 |
2. 内存占用比较
// 存储100万个元素的内存占用测试
HashMap: ~48MB
LinkedHashMap: ~56MB // 多出的8MB用于维护链表
多消耗约15%内存换取有序性
四、三大经典应用场景
场景1:保持插入顺序的日志记录
Map<String, String> configHistory = new LinkedHashMap<>();
configHistory.put("2023-01", "配置A");
configHistory.put("2023-02", "配置B");
// 遍历时严格按照时间顺序输出
场景2:实现LRU缓存(淘汰最近最少使用)
// 最大100个元素,超过时自动淘汰最久未使用的
Map<String, Object> lruCache = new LinkedHashMap<>(100, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 100;
}
};
场景3:有序的配置项管理
// 保持配置文件原始顺序
Map<String, String> settings = new LinkedHashMap<>();
settings.put("server.port", "8080");
settings.put("db.url", "jdbc:mysql...");
// 生成配置文件时顺序不变
五、源码级揭秘:如何实现访问顺序?
关键代码片段解析:
// get操作时的处理(accessOrder=true时)
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder) // 如果是访问顺序模式
afterNodeAccess(e); // 将被访问节点移到链表尾部
return e.value;
}
移动节点的具体过程:
- 从链表中解除该节点原有连接
- 将该节点追加到链表末尾
- 调整前后节点的指针
六、实战技巧:如何正确使用LinkedHashMap?
1. 初始化参数详解
// 完整构造方法
LinkedHashMap(int initialCapacity, // 初始容量
float loadFactor, // 负载因子
boolean accessOrder) // true=访问顺序, false=插入顺序
2. 实现固定大小缓存示例
// 最多缓存5个最近使用的城市温度
Map<String, Integer> weatherCache = new LinkedHashMap<>(5, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 5; // 超过5个就移除最老的
}
};
weatherCache.put("北京", 28);
weatherCache.put("上海", 30);
weatherCache.get("北京"); // 访问后"北京"变为最新
3. 性能优化建议
- 预分配足够容量避免频繁扩容
- 非必要不使用访问顺序模式(额外开销)
- 多线程环境用Collections.synchronizedMap包装
七、常见面试题精讲
Q1:LinkedHashMap和TreeMap都是有序的,区别是什么?
- LinkedHashMap:维护插入/访问顺序,O(1)时间复杂度
- TreeMap:按照键的自然顺序排序,O(log n)时间复杂度
Q2:如何实现线程安全的LinkedHashMap?
Map<String, String> safeMap =
Collections.synchronizedMap(new LinkedHashMap<>());
// 或者使用ConcurrentLinkedHashMap等第三方实现
Q3:为什么选择双向链表而不是单向链表?
因为需要支持:
- 快速删除任意节点(O(1)复杂度)
- LRU缓存需要移动节点到链表尾
结语:选择的艺术
当你需要Map时:
- 只要快 → HashMap
- 要记住顺序 → LinkedHashMap
- 需要排序 → TreeMap
- 线程安全 → ConcurrentHashMap
LinkedHashMap就像你的私人助理,不仅高效完成任务,还能记住每件事的来龙去脉。现在,是时候在你的工具箱里为它留个位置了!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











