






代码仅供参考
一元多项式计算器
注意:c报错的,删掉typedef enum Bool {false, true} bool;换成c++运行。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define MAX_SIZE 100
#define max(x, y) x > y ? x : y
typedef enum Bool {false, true} bool;
typedef struct {
int coef; //系数
int expn; //幂次
} ElemType;
// 线性表
typedef struct vector{
int size; // 开辟的空间大小
int length; // 有效数据长度
int *data;
}Vector;
// 单链表
typedef struct node {
ElemType data;
struct node *next;
}Node, *Link;
int pows[MAX_SIZE * 2 + 10];
void inputMessage() {
printf("因变量为x,不需要输入。输入多项式请按要求每一行输入两个数字,");
printf("分别代表x的系数与幂次,幂次由高到低。\n两数请用空格隔开,以文件结束符终止输入\n");
}
// 创建一个空的线性表
Vector getEmptyArray() {
Vector arr;
arr.size = MAX_SIZE * 2 + 10;
arr.data = (int*)malloc(sizeof(int) * arr.size);
for (int i = 0; i < arr.size; ++ i) arr.data[i] = 0;
arr.length = 0;
return arr;
}
// 线性表,输入多项式
Vector inputPolynomialArray() {
int coef, expn;
Vector arr = getEmptyArray();
while(~scanf("%d%d", &coef, &expn)) {
arr.length = max(arr.length, expn);
arr.data[expn] = coef;
}
++ arr.length;
return arr;
}
// 多项式相乘
Vector mulPolynomial(Vector A, Vector B) {
Vector arr = getEmptyArray();
int coef, expn;
for (int i = 0; i < A.length; ++ i) {
for (int j = 0; j < B.length; ++ j) {
coef = A.data[i] * B.data[j];
expn = i * j;
arr.data[expn] += coef;
arr.length = max(arr.length, expn);
}
}
++ arr.length;
return arr;
}
// 线性表,输出多项式
void printPolynomialArray(Vector arr) {
bool f = true;
printf("升幂:");
for (int i = 0; i < arr.length; ++ i) {
if(arr.data[i] == 0) continue;
if(!f) printf(" %c ", arr.data[i] > 0 ? '+' : '-');
else if(arr.data[i] < 0) printf("-");
f = false;
printf("%dx^%d", abs(arr.data[i]), i);
}
printf("\n降幂:");
f = true;
for (int i = arr.length - 1; i >= 0; -- i) {
if(arr.data[i] == 0) continue;
if(!f) printf(" %c ", arr.data[i] > 0 ? '+' : '-');
f = false;
printf("%dx^%d", abs(arr.data[i]), i);
}
puts("");
}
//单链表尾插法函数,减少代码量
Link rearInsert(Link p, int coef, int expn) {
Link tmp = tmp = (Link)malloc(sizeof(Node));
tmp->next = NULL;
tmp->data.coef = coef;
tmp->data.expn = expn;
p->next = tmp;
p = tmp;
return p;
}
//单链表,输入一个多项式
Link inputPolynomialList() {
Link head = (Link)malloc(sizeof(Node));
head->next = NULL;
int coef, expn;
Link tmp, p;
p = head;
while(~scanf("%d%d", &coef, &expn))
p = rearInsert(p, coef, expn);
return head;
}
//单链表,输出多项式
void printPolynomialList(Link head) {
Vector arr = getEmptyArray();
Link p = head;
while(p->next != NULL) {
int coef = p->next->data.coef;
int expn = p->next->data.expn;
arr.data[expn] += coef;
arr.length = max(arr.length, expn);
p = p->next;
}
++ arr.length;
printPolynomialArray(arr);
}
//多项式相加减
Link addOrSubPolynomial(Link A, Link B, bool add) {
Link head = (Link)malloc(sizeof(Node));
Link p, tmp;
int coefA, coefB, coef;
int expnA, expnB, expn;
p = head;
// 链表加减,先计算出幂次高的值
while(A->next && B->next) {
coefA = A->next->data.coef;
coefB = B->next->data.coef;
expnA = A->next->data.expn;
expnB = B->next->data.expn;
if(expnA == expnB) {
if(add) coef = coefA + coefB;
else coef = coefA - coefB;
expn = expnA;
A = A->next;
B = B->next;
if(coef == 0) continue;
} else if(expnA > expnB) {
coef = coefA;
expn = expnA;
A = A->next;
} else {
if(add) coef = coefB;
else coef = -coefB;
expn = expnB;
B = B->next;
}
p = rearInsert(p, coef, expn);
}
while(A->next) {
p = rearInsert(p, A->next->data.coef, A->next->data.expn);
A = A->next;
}
while(B->next) {
if(add) p = rearInsert(p, B->next->data.coef, B->next->data.expn);
else p = rearInsert(p, -B->next->data.coef, B->next->data.expn);
B = B->next;
}
return head;
}
int main() {
printf("1:多项式+,-\n");
printf("2:多项式*\n");
printf("0:退出\n");
int choose;
while(~scanf("%d", &choose)) {
if(choose == 0) break;
inputMessage();
if(choose == 1) {
printf("请输入多项式A:\n");
Link A = inputPolynomialList();
printf("请输入多项式B:\n");
Link B = inputPolynomialList();
int op;
printf("0:-\n1:+\n");
scanf("%d", &op);
Link C = addOrSubPolynomial(A, B, op);
printPolynomialList(C);
} else {
printf("请输入多项式A:\n");
Vector A = inputPolynomialArray();
printf("请输入多项式B:\n");
Vector B = inputPolynomialArray();
Vector C = mulPolynomial(A, B);
printPolynomialArray(C);
}
puts("---------");
printf("1:多项式+,-\n");
printf("2:多项式*\n");
printf("0:退出\n");
}
return 0;
}
实验二:哈夫曼编码
注意:C++运行代码
补充
之前写的没仔细看实验要求,本来想着也没多难,然后就直接写了。哪知道他还要求中文字符。(;´д`)ゞ。这一天天的,教的东西没啥,要求蛮多。
除此之外,一些细节也已更改。就是输出文件路径那些,之前漏掉了。
为减少篇幅,最新的代码放这里:
https://paste.ubuntu.com/p/cMDX6fWQsn/
然后说下支持中文字符的改动
加上头文件#include <map>,work函数中原有的int* mp改成map<char, int> mp。然后更改原有函数void getLeafsArray。
void getLeafsArray(List &leafs, map<char, int> &mp, char* s) {
map<char, int> nums; // 保存每个字符出现的次数
for (int i = 0; i < strlen(s); ++ i)
++ nums[s[i]];
leafs.len = nums.size() + 1; // 0不用故+1
leafs.codes = (char*) malloc(sizeof(char) * leafs.len);
leafs.weights = (int*) malloc(sizeof(int) * leafs.len);
int len = 0;
for (map<char, int>::iterator it = nums.begin(); it != nums.end(); it ++) {
leafs.codes[++ len] = it->first;
leafs.weights[len] = it->second;
mp[it->first] = len; // 字符映射,方便查找
}
}
然后就是编码部分。直接新建记事本用的应该是utf8的编码,然而咱们的控制台大部分都是gbk编码的。

所以如果你的控制台上出现乱码。像这样。

不要慌。记事本里的还是完好的。
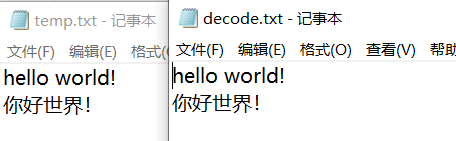
若是想消除控制台上的乱码,可以用记事本新建,保存的时候将编码保存成ANSI。
ANSI编码会根据电脑系统的不同为你选择合适的编码。简体中文环境下就是gbk。详见百度百科


输入和输出
- 输入:硬盘上原始文件的文件路径
- 输出:
- 生成一个加密文件,并在控制台输出其路径。
- 生成一个解码文件,并在控制台输出其路径。
- 在控制台输出原始文件与解码文件的对比结果。
编写环境
C/C++
实验分析
分析个锤子,就两部分。会就是会,不会就百度。
- 文件操作
- 哈夫曼编码
文件操作咱们就用C语言吧,起码还会一点点,C++就要从零开始了
文件操作
编写两个函数,一个用来读取文本内容,一个写入文本内容。
- 文本路径Path,及字符串。typedef char* Path。
- 读取文本内容,char* readAllTxt(Path txtPath)
- 写入文本内容,void writeTxt(char* str, Path txtPath)。
code
char* readAllTxt(Path txtPath) {
FILE* fp = fopen(txtPath, "rb"); // rb打开用于读取的二进制文件,不要写r。不然会错
fseek(fp, 0, SEEK_END); // 将fp的输入流移动到文本末端
int flen = ftell(fp); // 计算文本长度
char* str = (char*)malloc(sizeof(char) * (flen + 1)); // 创建一个长度为flen+1的字符数组。结束符'\0'要占一位。所以最小的长度就是flen+1
fseek(fp, 0, SEEK_SET); // 再讲fp的输入流移动到文本起始处
fread(str, flen, 1, fp); // 从fp的输入流位置开始,读取1个长度为flen的字符串给str
str[flen] = '\0'; // 最后一位结束符
fclose(fp); // 关闭输入流
return str;
}
void writeTxt(char* str, Path txtPath) {
FILE* fp = fopen(txtPath, "wb"); //wb打开用于写入的二进制文件
rewind(fp); // 把文件指针移到由stream(流)指定的开始处, 同时清除和流相关的错误和EOF标记.
fwrite(str, strlen(str), 1, fp); // 往fp中写入一个字符串。从str中读取,长度为strlen(str)
fclose(fp);
}
哈夫曼树编码
原理啥的就不细写了,网上有很多博客。我就简单说下这是个啥玩意。
有个文本abbbcccddd。它比较害羞,所以它要咱们帮它加个密,一个字符对应一个字符串。除此之外,它还喜欢二叉树。非得要咱们用二叉树帮它加密。孩子们扮演0和1,根节点不喜欢和它们一起玩,就出来露个脸。只有在所需编码的字符个数为1时,根节点才。。。一个人你玩个毛线。
游戏也很简单。所需编码字符**{a, b, c, d}。每个都为一个叶子节点,作为一个节点集。在文本中出现的次数为权值。每次操作便从节点集中挑选出两个权值最小**的节点(不用再放回去),组成一个新的节点,放进节点集。直到只剩下一个节点——根节点。
获取编码字符**{a, b, c, d}所对应的编码str,除根节点外,所有节点都标上0、1,0左、1右**。然后从所对应的叶子节点开始往上走,走到根节点。其路程所对应的字符串的逆序就是该字符所对应的编码。
还原哈夫曼编码,从根节点开始,0走左、1走右,不能走了便得到所对应的字符,然后再从根节点开始走。
code
typedef char* Path;
const int MAX_SIZE = 1010;
typedef struct HTNode{
int weight;
int parent;
int lson;
int rson;
// 0表无
HTNode(int _weight = 0, int _parent = 0, int _lson = 0, int _rson = 0) {
weight = _weight;
parent = _parent;
lson = _lson;
rson = _rson;
}
}*HuffmanTree;
typedef struct LeafNodeArray{
int len; // 这个从1开始,0不用
int* weights;
char* codes;
}List;
typedef char** HuffmanCode;
void getLeafsArray(List &leafs, int* &mp, char* s) { // 得到叶子节点集
int num = 0; // 不同字符数
// cnt用来记录每个字符出现的次数
int* cnt = (int*) malloc(sizeof(int) * 310); memset(cnt, 0, sizeof(int) * 310);
for (int i = 0; i < strlen(s); ++ i)
if(cnt[s[i] ] ++ == 0) ++ num;
leafs.len = num + 1; // 从1开始存储,0不用,故num + 1
leafs.codes = (char*) malloc(sizeof(char) * leafs.len);
leafs.weights = (int*) malloc(sizeof(int) * leafs.len);
mp = (int*) malloc(sizeof(int) * 310);
memset(mp, 0, sizeof(int) * 310);
int len = 0;
for (int i = 0; i < 310; ++ i) {
if(cnt[i] != 0) {
leafs.codes[++ len] = i;
leafs.weights[len] = cnt[i];
mp[i] = len; // 字符映射,方便查询每个字符的编码
}
}
}
/**
找到两个权重最小的节点,当然此节点还没有父节点,有说明啥,用过一次了。出局了。
**/
void select(HuffmanTree &HT, int len, int &node1, int &node2) {
int w1, w2;
node1 = node2 = w1 = w2 = 0; // 初值为0
/**
先更新w1,后更新w2。另w1始终<=w2。故每次更新w1的时候,就将原本的{w1,node1}给{w2,node2}
**/
for (int i = 1; i <= len; ++ i) {
if(HT[i].parent != 0) continue; // 有父节点,一边玩去
// 更新w1,node1
if(w1 == 0 || w1 > HT[i].weight) {
w2 = w1;
node2 = node1;
w1 = HT[i].weight;
node1 = i;
continue;
}
// 更新w2,node2
if(w2 == 0 || w2 > HT[i].weight) {
w2 = HT[i].weight;
node2 = i;
continue;
}
}
}
void HuffmanCoding(HuffmanTree &HT, HuffmanCode &HC, List leafs, int &root) {
int m = leafs.len - 1; // 叶子节点个数,0没用到,故-1
int n = 2 * m - 1; // 二叉树节点个数,二叉树的性质
// 存储二叉树,共n个节点,0不用,开辟n+1个
HT = (HuffmanTree)malloc(sizeof(HTNode) * (n + 1));
for (int i = 1; i <= m; ++ i) HT[i] = HTNode(leafs.weights[i], 0, 0, 0); // m个叶子节点
// 建树
for (int i = m + 1; i <= n; ++ i) {
int node1, node2;
select(HT, i - 1, node1, node2); // 从节点集中找到两个权重最小的节点
HT[i] = HTNode(HT[node1].weight + HT[node2].weight, 0, node1, node2); // 合成新节点
HT[node1].parent = i; HT[node2].parent = i; // 更新子节点的父节点
}
// 找到跟节点root,根节点最大,没父节点的就是跟节点。
for (int i = 1; i <= n; ++ i) {
if(HT[i].parent == 0) {root = i; break; }
}
// 0不用,故开辟m + 1个长度未知的字符串
HC = (char**) malloc(sizeof(char*) * (m + 1));
// 开辟一个长度为m的字符串,编码长度肯定会<m,m是叶子节点数,编码长度最大就是高度,m绝对够用
char* str = (char*) malloc(sizeof(char) * m);
int len = 0;
int parent;
for (int i = 1; i <= m; ++ i) {
len = 0;
// 父节点为0,代表该节点为root,跳出循环
for (int j = i; HT[j].parent != 0; j = HT[j].parent ) {
parent = HT[j].parent;
if(HT[parent].lson == j) str[len ++] = '0'; // 是父节点的左孩子 0
else str[len ++] = '1'; // 右孩子 1
}
HC[i] = (char*) malloc(sizeof(char) * len); // 存储二叉树,共n个节点,0不用,开辟n+1个
for (int j = 0; j < len; ++ j) HC[i][j] = str[len - j - 1]; // 逆序
HC[i][len] = '\0'; // 结束符
}
}
void work(Path parentPath, Path txtName) {
Path oriTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path codeTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path decodeTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path codeName = "code.txt";
Path decodeName = "decode.txt";
strcat(parentPath, "\\\\"); // \\转义字符\
strcpy(oriTxtPath, parentPath);
strcat(oriTxtPath, txtName);
strcpy(codeTxtPath, parentPath);
strcat(codeTxtPath, codeName);
strcpy(decodeTxtPath, parentPath);
strcat(decodeTxtPath, decodeName);
char* oriMessage = readAllTxt(oriTxtPath);
int* mp;
List leafs;
getLeafsArray(leafs, mp, oriMessage);
HuffmanTree HT;
HuffmanCode HC;
int root;
HuffmanCoding(HT, HC, leafs, root);
// /**
// 输出每一字符对应的哈夫曼码,这个不建议打印。
// 因为有些字符无法打印在控制台上。
// **/
// for (int i = 1; i < leafs.len; ++ i)
// printf("%c : %s\n", leafs.codes[i], HC[i]);
// puts("--------------");
// 加密
char* codeMessage = (char*) malloc(sizeof(char) * (leafs.len * strlen(oriMessage)));
codeMessage[0] = '\0';
for (int i = 0; i < strlen(oriMessage); ++ i) strcat(codeMessage, HC[mp[oriMessage[i] ] ]);
printf("加密后的字符串:\n"); puts(codeMessage);
writeTxt(codeMessage, codeTxtPath);
// 文件大小
printf("加密文件字符串长度:%d\n", strlen(codeMessage));
printf("原文件字符串长度:%d\n", strlen(oriMessage));
// 解码
int p = root; // 从root开始走
char* decodeMessage = (char*) malloc(sizeof(char) * strlen(oriMessage));
int len = 0;
for (int i = 0; i < strlen(codeMessage); ++ i) {
if(codeMessage[i] == '0') p = HT[p].lson;
else p = HT[p].rson;
// 找到字符,再从root开始走
if(HT[p].lson == 0 && HT[p].rson == 0) {
decodeMessage[len ++] = leafs.codes[p];
p = root;
}
}
decodeMessage[len] = '\0';
printf("解码内容:\n"); puts(decodeMessage);
writeTxt(decodeMessage, decodeTxtPath);
// 对比
if(strcmp(decodeMessage, oriMessage) == 0) puts("解码文件内容与原文件内容一致。");
else puts("!!!解码文件内容与原文件内容不一致。");
}
现在,就只剩下输入了。
code
int main() {
/**注意:输入路径时,里面的\要用\\来代替。**/
char parentPath[MAX_SIZE];
char txtName[MAX_SIZE];
printf("输入文件的父路径:"); scanf("%s", parentPath);
printf("输入文件名:"); scanf("%s", txtName);
printf("working\n"); work(parentPath, txtName);
return 0;
}
少量注释完整版代码
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <cstring>
#include <cctype>
#include <iostream>
#include <algorithm>
#include <queue>
#include <vector>
using namespace std;
/**
1、读取文件
2、生成加密文件
3、比较两文件大小差别
4、对加密文件进行解密,生成解密文件
5、比较原始文件和解码文件的内容是否一致。
**/
typedef char* Path;
const int MAX_SIZE = 1010;
typedef struct HTNode{
int weight;
int parent;
int lson;
int rson;
// 0表无
HTNode(int _weight = 0, int _parent = 0, int _lson = 0, int _rson = 0) {
weight = _weight;
parent = _parent;
lson = _lson;
rson = _rson;
}
}*HuffmanTree;
typedef struct LeafNodeArray{
int len; // 这个从1开始,0不用
int* weights;
char* codes;
}List;
typedef char** HuffmanCode;
char* readAllTxt(Path txtPath) {
FILE* fp = fopen(txtPath, "rb");
fseek(fp, 0, SEEK_END);
int flen = ftell(fp);
char* str = (char*)malloc(sizeof(char) * (flen + 1));
fseek(fp, 0, SEEK_SET);
fread(str, flen, 1, fp);
str[flen] = '\0';
fclose(fp);
return str;
}
void writeTxt(char* str, Path txtPath) {
FILE* fp = fopen(txtPath, "wb");
rewind(fp);
fwrite(str, strlen(str), 1, fp);
fclose(fp);
}
void getLeafsArray(List &leafs, int* &mp, char* s) {
int num = 0;
int* cnt = (int*) malloc(sizeof(int) * 310); memset(cnt, 0, sizeof(int) * 310);
for (int i = 0; i < strlen(s); ++ i)
if(cnt[s[i] ] ++ == 0) ++ num;
leafs.len = num + 1;
leafs.codes = (char*) malloc(sizeof(char) * leafs.len);
leafs.weights = (int*) malloc(sizeof(int) * leafs.len);
mp = (int*) malloc(sizeof(int) * 310);
memset(mp, 0, sizeof(int) * 310);
int len = 0;
for (int i = 0; i < 310; ++ i) {
if(cnt[i] != 0) {
leafs.codes[++ len] = i;
leafs.weights[len] = cnt[i];
mp[i] = len;
}
}
}
/**
找到两个权重最小的节点,当然此节点还没有父节点,有说明啥,用过一次了。出局了。
**/
void select(HuffmanTree &HT, int len, int &node1, int &node2) {
int w1, w2;
node1 = node2 = w1 = w2 = 0;
for (int i = 1; i <= len; ++ i) {
if(HT[i].parent != 0) continue; // 有父节点,一边玩去
if(w1 == 0 || w1 > HT[i].weight) {
w2 = w1;
node2 = node1;
w1 = HT[i].weight;
node1 = i;
continue;
}
if(w2 == 0 || w2 > HT[i].weight) {
w2 = HT[i].weight;
node2 = i;
continue;
}
}
}
void HuffmanCoding(HuffmanTree &HT, HuffmanCode &HC, List leafs, int &root) {
int m = leafs.len - 1;
int n = 2 * m - 1;
// 存储二叉树
HT = (HuffmanTree)malloc(sizeof(HTNode) * (n + 1));
for (int i = 1; i <= m; ++ i) HT[i] = HTNode(leafs.weights[i], 0, 0, 0);
// 建树
for (int i = m + 1; i <= n; ++ i) {
int node1, node2;
select(HT, i - 1, node1, node2);
HT[i] = HTNode(HT[node1].weight + HT[node2].weight, 0, node1, node2);
HT[node1].parent = i; HT[node2].parent = i;
}
for (int i = 1; i <= n; ++ i)
if(HT[i].parent == 0) {root = i; break; }
HC = (char**) malloc(sizeof(char*) * (m + 1));
char* str = (char*) malloc(sizeof(char) * m);
int len = 0;
int parent;
for (int i = 1; i <= m; ++ i) {
len = 0;
for (int j = i; HT[j].parent != 0; j = HT[j].parent ) {
parent = HT[j].parent;
if(HT[parent].lson == j) str[len ++] = '0';
else str[len ++] = '1';
}
HC[i] = (char*) malloc(sizeof(char) * len);
for (int j = 0; j < len; ++ j) HC[i][j] = str[len - j - 1];
HC[i][len] = '\0';
}
}
void work(Path parentPath, Path txtName) {
// 确定三个文件的路径
Path oriTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path codeTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path decodeTxtPath = (char*) malloc(sizeof(char) * MAX_SIZE);
Path codeName = "code.txt";
Path decodeName = "decode.txt";
strcat(parentPath, "\\\\");
strcpy(oriTxtPath, parentPath);
strcat(oriTxtPath, txtName);
strcpy(codeTxtPath, parentPath);
strcat(codeTxtPath, codeName);
strcpy(decodeTxtPath, parentPath);
strcat(decodeTxtPath, decodeName);
// 编码
char* oriMessage = readAllTxt(oriTxtPath);
int* mp;
List leafs;
getLeafsArray(leafs, mp, oriMessage);
HuffmanTree HT;
HuffmanCode HC;
int root;
HuffmanCoding(HT, HC, leafs, root);
// 加密
char* codeMessage = (char*) malloc(sizeof(char) * (leafs.len * strlen(oriMessage)));
codeMessage[0] = '\0';
for (int i = 0; i < strlen(oriMessage); ++ i) strcat(codeMessage, HC[mp[oriMessage[i] ] ]);
printf("加密后的字符串:\n"); puts(codeMessage);
writeTxt(codeMessage, codeTxtPath);
// 文件大小
printf("加密文件字符串长度:%d\n", strlen(codeMessage));
printf("原文件字符串长度:%d\n", strlen(oriMessage));
// 解码
int p = root;
char* decodeMessage = (char*) malloc(sizeof(char) * strlen(oriMessage));
int len = 0;
for (int i = 0; i < strlen(codeMessage); ++ i) {
if(codeMessage[i] == '0') p = HT[p].lson;
else p = HT[p].rson;
if(HT[p].lson == 0 && HT[p].rson == 0) {
decodeMessage[len ++] = leafs.codes[p];
p = root;
}
}
decodeMessage[len] = '\0';
printf("解码内容:\n"); puts(decodeMessage);
writeTxt(decodeMessage, decodeTxtPath);
// 对比
if(strcmp(decodeMessage, oriMessage) == 0) puts("解码文件内容与原文件内容一致。");
else puts("!!!解码文件内容与原文件内容不一致。");
}
int main() {
char parentPath[MAX_SIZE];
char txtName[MAX_SIZE];
printf("输入文件的父路径:"); scanf("%s", parentPath);
printf("输入文件名:"); scanf("%s", txtName);
printf("working\n"); work(parentPath, txtName);
return 0;
}




实验三:图及其应用
实验报告带的源码部分解析
注意:若代码与文件在同一目录下,可以只写文件名,若不在请自行补全路径。
#define inf 99999999 // 代表无穷大,及不存在
#define max_element 50
int e[max_element][max_element]; //保存地图的数组,保存的是边的距离
/**
存路径,_e是计算距离时用的,_t是计算时间用的。
eg:start:1, end:3。计算距离,假设最短路径是1->2->3
那么path_e[1][3] = 2, path_e[2][3] = 3.
**/
int path_e[max_element][max_element], path_t[max_element][max_element];
double t[max_element][max_element]; //保存地图的速度(这个是报告里写的),不是速度,是经过(i->j)这一条边的所需时间
count.txt 保存地图中点的个数
map.txt存的是地图的路径。用二维数组来保存。边是双向边。
map_speed.txt同样用的是二维数组,每一个元素代表的是经过那一条边所需的时间。
该实验报告中使用的算法,Floyd。三重循环暴力求解。
算法思路:确定一个中间点k,然后看看有没有两个点i,j。可以使用k缩短i与j之间的距离。达到松弛的效果。如果有就更新数组。没有不管。要想获得最短路径,那么就令每一个点都当一个中间点。
为什么?这个。。。请自行搜索吧,或者自己悟
源码中的一个代码实现部分,打印地图。我觉得直接用画笔画出来图片也行(▽)。反正给了图片,而且也只画这一个。
///将地图信息打印*************能否采用图形界面将位置信息打印?
system("mspaint map.png"); // map.png是图片文件名。
文件内容:
count.txt
9
map.txt
99999999 12 8 6 99999999 99999999 99999999 99999999 99999999
12 99999999 99999999 99999999 5 99999999 99999999 99999999 99999999
8 99999999 99999999 99999999 8 99999999 99999999 99999999 99999999
6 99999999 99999999 99999999 99999999 7 99999999 99999999 99999999
99999999 5 8 99999999 99999999 99999999 5 6 99999999
99999999 99999999 99999999 7 99999999 99999999 99999999 10 99999999
99999999 99999999 99999999 99999999 5 99999999 99999999 99999999 6
99999999 99999999 99999999 99999999 6 10 99999999 99999999 8
99999999 99999999 99999999 99999999 99999999 99999999 6 8 99999999
map_speed.txt
99999999.00 0.30 0.16 0.10 99999999.00 99999999.00 99999999.00 99999999.00 99999999.00
0.30 99999999.00 99999999.00 99999999.00 0.25 99999999.00 99999999.00 99999999.00 99999999.00
0.16 99999999.00 99999999.00 99999999.00 0.32 99999999.00 99999999.00 99999999.00 99999999.00
0.10 99999999.00 99999999.00 99999999.00 99999999.00 0.13 99999999.00 99999999.00 99999999.00
99999999.00 0.25 0.32 99999999.00 99999999.00 99999999.00 0.25 0.30 99999999.00
99999999.00 99999999.00 99999999.00 0.13 99999999.00 99999999.00 99999999.00 0.25 99999999.00
99999999.00 99999999.00 99999999.00 99999999.00 0.25 99999999.00 99999999.00 99999999.00 0.20
99999999.00 99999999.00 99999999.00 99999999.00 0.30 0.25 99999999.00 99999999.00 0.32
99999999.00 99999999.00 99999999.00 99999999.00 99999999.00 99999999.00 0.20 0.32 99999999.00















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









