






二分算法
二分查找是一种算法,其输入是一个有序的元素列表(必须有序的原因稍后解释)。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回null。
仅当列表是有序的时候,二分查找才管用
对于包含n个元素的列表,用二分查找最多需要log2n步,而简单查找最多需要n步。
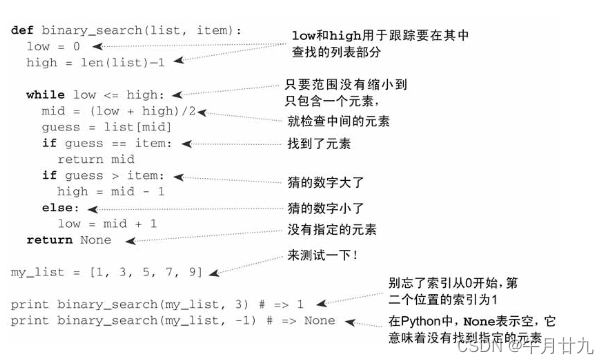
最多需要猜测的次数与列表长度相同,这被称为线性时间(linear time)
二分查找的运行时间为对数时间(或log时间)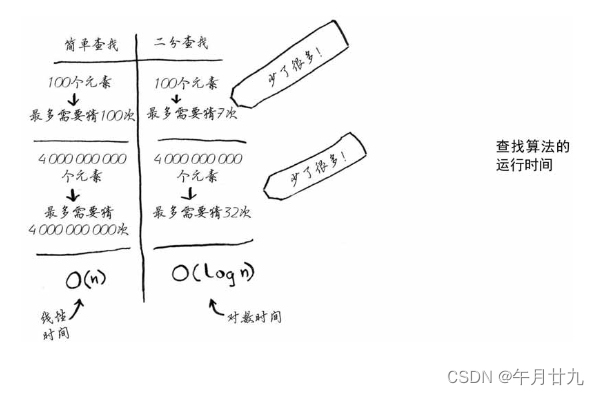
大O表示法
仅知道算法需要多长时间才能运行完毕还不够,还需知道运行时间如何随列表增长而增加。这正是大O表示法的用武之地。
大O表示法指出了算法有多快。例如,假设列表包含n个元素。简单查找需要检查每个元素,因此需要执行n次操作。使用大O表示法,这个运行时间为O(n)。
大O表示法指的并非以秒为单位的速度。大O表示法让你能够比较操作数,它指出了算法运行时间的增速
大O表示法指出了最糟情况下的运行时间
简单查找的运行时间总是为O(n)。
从快到慢的顺序:
❑ O(log n),也叫对数时间,这样的算法包括二分查找。
❑ O(n),也叫线性时间,这样的算法包括简单查找。
❑ O(n * log n),这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。
❑ O(n2),这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。
❑ O(n!),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。
❑ 算法的速度指的并非时间,而是操作数的增速。
❑ 谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
❑ 算法的运行时间用大O表示法表示。
❑ O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
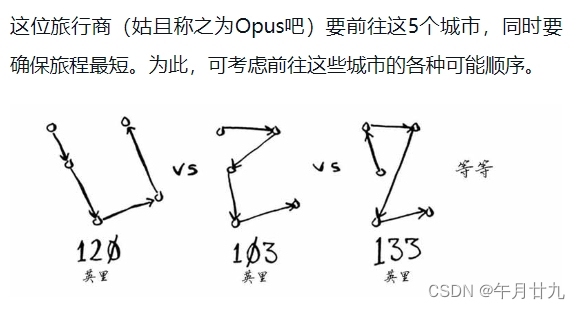
旅行商问题


选择排序
内存的工作原理
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
数组和链表
数组
先将待办事项存储在数组中。使用数组意味着所有待办事项在内存中都是相连的(紧靠在一起的)
在数组中添加新元素也可能很麻烦。如果没有了空间,就得移到内存的其他地方,因此添加新元素的速度会很慢。一种解决之道是“预留座位”:即便当前只有3个待办事项,也请计算机提供10个位置。
它存在如下两个缺点:
❑ 你额外请求的位置可能根本用不上,这将浪费内存。你没有使用,别人也用不了。
❑ 待办事项超过10个后,你还得转移。
链表
链表中的元素可存储在内存的任何地方。
链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
使用链表时,根本就不需要移动元素。这还可避免另一个问题。
链表存在问题:在需要读取链表的最后一个元素时,你不能直接读取,因为你不知道它所处的地址
插入
使用链表时,插入元素很简单,只需修改它前面的那个元素指向的地址。
而使用数组时,则必须将后面的元素都向后移。
插入元素时,链表是更好的选择。
删除
链表也是更好的选择,因为只需修改前一个元素指向的地址即可。而使用数组时,删除元素后,必须将后面的元素都向前移。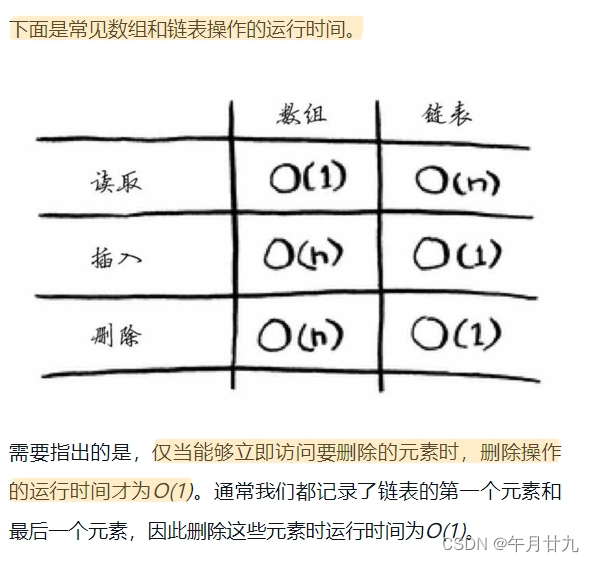
数组和链表哪个用得更多呢?
数组用得很多,因为它支持随机访问。
有两种访问方式:随机访问和顺序访问。
顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。
随机访问意味着可直接跳到第十个元素。本书经常说数组的读取速度更快,这是因为它们支持随机访问。
很多情况都要求能够随机访问,因此数组用得很多。
选择排序
并非每次都需要检查n个元素。第一次需要检查n个元素,但随后检查的元素数依次为n -1,n -2,…,2和1。平均每次检查的元素数为1/2×n,因此运行时间为O(n×1/2×n)。但大O表示法省略诸如1/2这样的常数(有关这方面的完整讨论,请参阅第4章),因此简单地写作O(n×n)或O(n2)。
选择排序是一种灵巧的算法,但其速度不是很快。快速排序是一种更快的排序算法,其运行时间为O(n log n)
在同一个数组中,所有元素的类型都必须相同(都为int、double等)。
递归
基线条件和递归条件
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。
递归条件指的是函数调用自己。
基线条件则指的是函数不再调用自己,从而避免形成无限循环。
栈
只有两种操作:压入(插入)和弹出(删除并读取)。
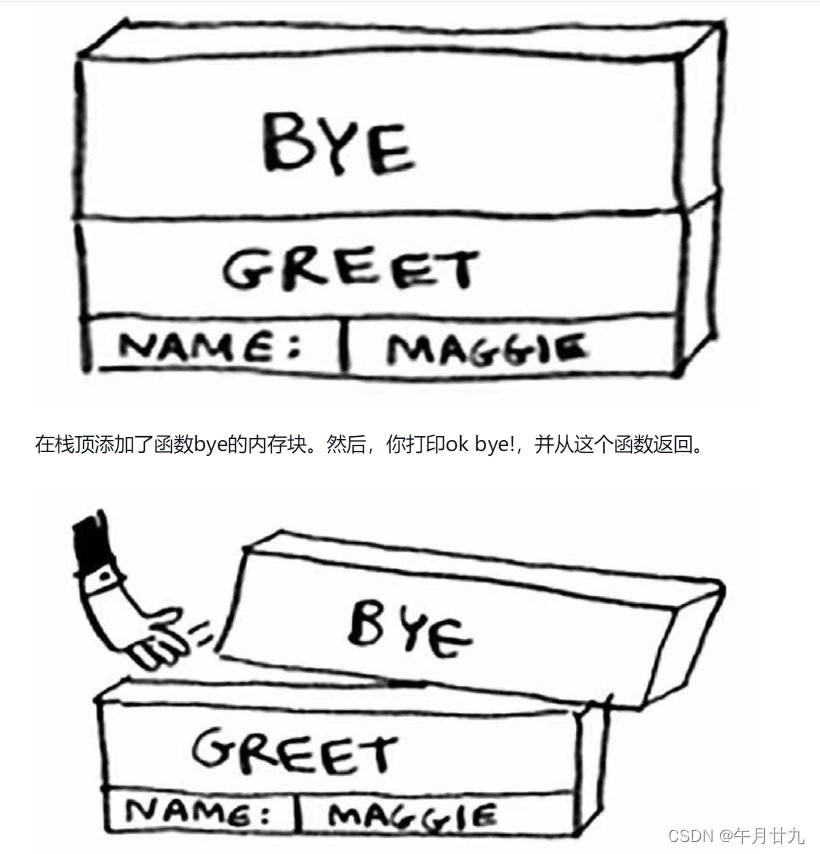
调用栈




















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









