






感知优化视频编码研究综述
关键词:感知视频编码,质量评估,人类视觉系统,视觉注意,仅显差异,率失真优化
为了更有效地压缩视频,感知优化视频编码是最有前途的方向之一,它倾向于利用人类视觉系统(HVS)的视觉特性,尽量减少视频中的视觉冗余。
本文首先从神经生理学的角度分析了HVS的视觉特性,并对HVS的感知模型和视觉质量评估算法进行了综述。然后,我们对感知优化视频编码算法的最新进展进行了系统的回顾,分析了问题的提出、关键特征、性能、优缺点。第三,对最新编码标准的感知编码性能进行了实验分析和比较。最后,指出了感知视频编码面临的挑战和机遇。包括如下五个部分:
1.提出了感知优化视频编码的问题表述和框架。包括视觉感知建模、视觉质量评估和感知引导编码优化。
2.介绍了视觉因子、关键计算视觉模型和质量评价模型的研究进展。
3.从感知优化比特分配、率失真优化、变换与量化、滤波与增强对感知视频编码优化进行综述。
4.实验分析最新编码标准和工具的感知编码性能。
5.指出感知视频编码的挑战问题和未来机遇。
感知优化视频编码框架
图1显示了一个端到端的视觉通信系统链,该链由光线与场景P、成像系统与表示(FR)、处理与通信(FE)、显示系统与观看条件(FD)以及HVS(FHVS)五大部分组成。
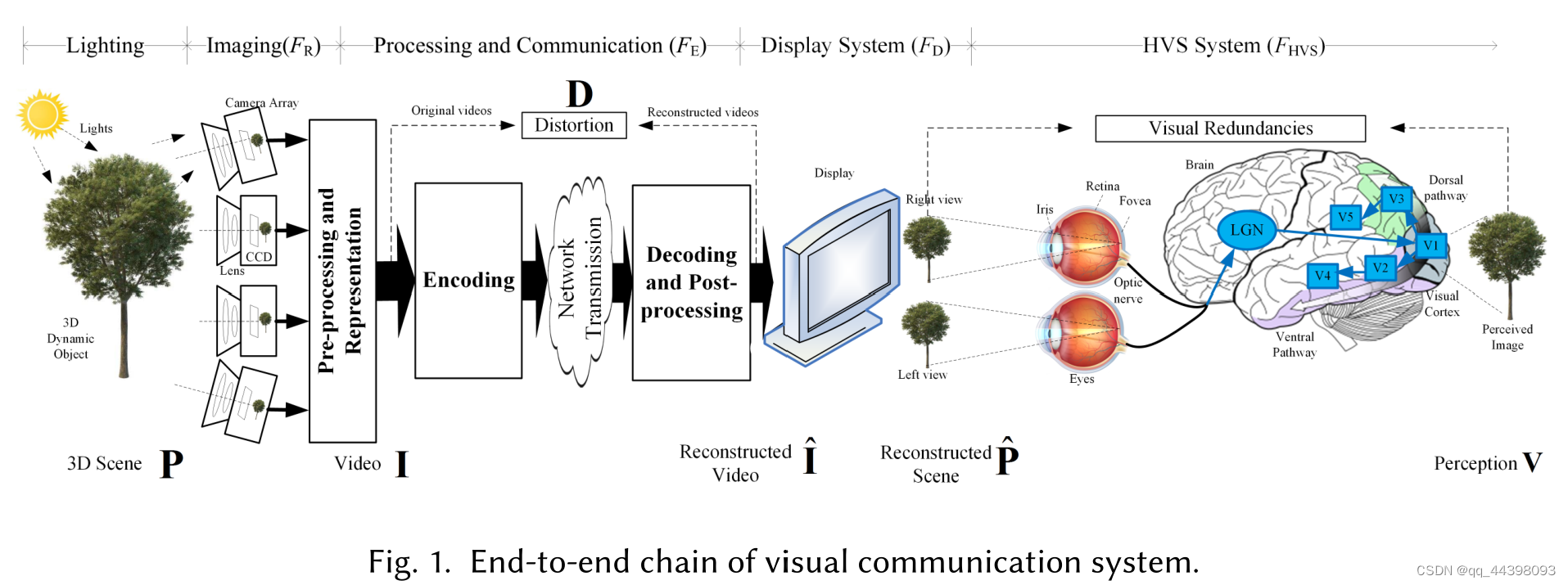
感知失真DV,其中V和Vorg分别为视觉传达中有无编码失真的感知图像。根据Dv和Fhvs的研究结果,可以利用感知冗余来优化FE中的视频压缩,这被称为感知优化视频编码。
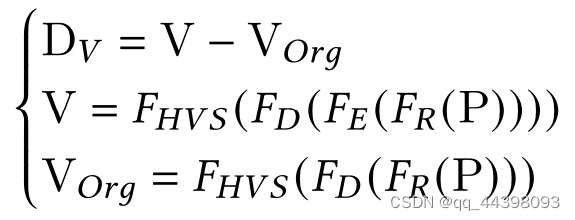
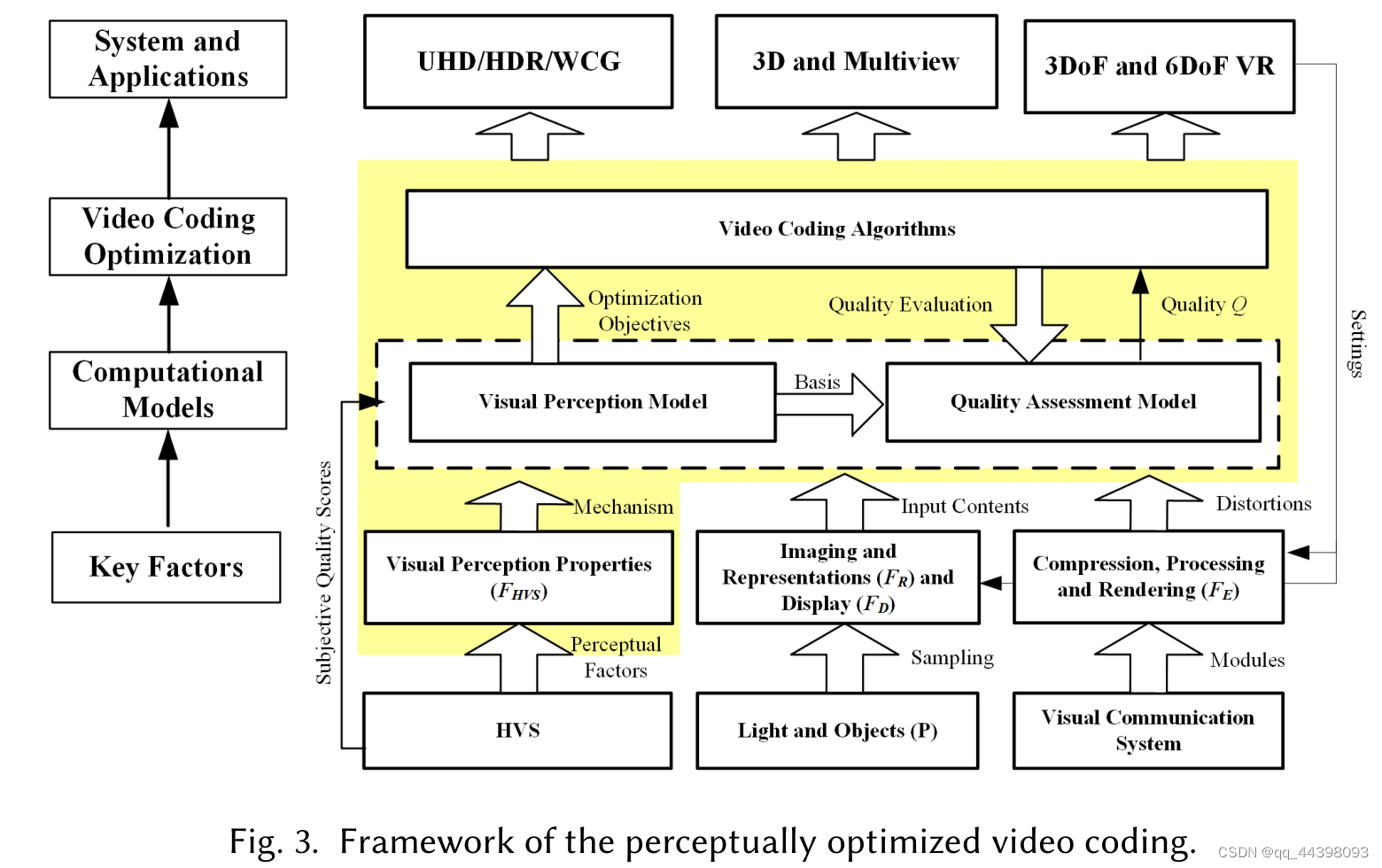
基于感知优化的视频编码框架从底层特征/因素到应用可分为四个层次,分别是**关键因素、计算感知模型、编码优化和应用。**如下图(图3)所示。第一级有四类关键因素,包括HVS属性(Fhvs)、来自场景P的图像表示(FR)和显示(FD)、压缩、处理和渲染的视觉通信系统(FE)。第二层包括基于对HVS的理解计算感知因子的视觉感知模型和对视觉质量进行评价的计算质量评估模型。在这个层次之上是视频编码优化,利用视觉冗余作为关键优化目标之一。然后,利用质量评价模型对压缩后的视频质量进行评价。最后,将视频编码算法应用到视频应用中,以降低码率,提高视觉质量。
人类视觉系统的生理视觉因素与计算知觉模型
人对于亮度相比色度更加敏感。基于这些感知因素,提出了许多计算模型来模拟Fhvs的视觉响应。简要介绍了三种高级计算模型,包括视觉灵敏度、JND和视觉注意。
1.视觉敏感度模型
视觉灵敏度是指对输入视觉信号的视觉反应。Bosse等[7]发现,随着图像纹理和空间复杂度的增加,图像中对MSE失真的空间视觉敏感度降低,并训练了一个神经网络来计算每个MSE失真的感知权重。Hosseini等人[31]试图合成一个卷积滤波器来模拟HVS对图像清晰度的视觉灵敏度衰减响应,即Io=I*Fhvs,该滤波器近似为逆广义高斯分布,并使用MaxPol滤波器库实现。
2.JND模型
由于有限的视觉灵敏度和掩蔽效应,并不是每一种失真都会被HVS感知到,最小可见阈值记为JND。Liu等人[54]开发了一种基于深度学习的JND模型来预测感知差异,其中JND预测被建模为一个二元分类问题,然后求解。Zhang等[112]基于VMAF特征[51]和支持向量回归(SVR),开发了压缩视频的满意用户比例(satisfaction User Ratio, SUR)预测。在[114]中,提出了一种基于深度学习的视频智能时空SUR (VW-STSUR)模型,该模型使用两流CNN来预测SUR和VWJND,其中在分数和特征级别融合了时空特征。
3.视觉注意模型
视觉注意(VA)是一种高级认知机制,它驱动人眼和视网膜中央凹注意内容以感知更高的保真度,也称为感兴趣区域(ROI)。HVS更关注高对比度的区域,如亮度、纹理、方向、时间运动和颜色对比。[109]中,Zhang等利用3D-CNN提取立体视频的时空显著性特征,利用卷积长短期记忆(Convolutional Long - Short-Term Memory, convl - lstm)提取立体视频的时空显著性特征用于融合时空和深度属性。
4.结论
HVS是一种复合非线性双目视觉系统,它比多个模型的简单组合更为复杂。多刺激物与双眼视觉的联合效应建模更具挑战性。由于深度学习算法,能够在大量数据中发现统计关系。对于具有足够标签的场景,数据驱动的计算感知模型方法是一个很有前途的方向。另一方面,发现的感知机制,如多尺度和视觉注意,也可以改善学习模型的设计。
视觉质量评估的计算模型
V = F VQA(Î),其中F VQA是非参考视觉质量评价的关系函数。V = Fhvs (FD (Î)),F VQA() = Fhvs(FD ()) DV = F VQA(D). DV是主观实验得到的视觉质量退化,信号失真D = I−Î。基于时间信息是否被利用,将全参考视觉质量评价模型分为IQA(图像)模型和VQA(视频)模型。
1.IQA模型
对于压缩后的彩色图像,Shang等[71]提出了一种基于颜色敏感性的组合PSNR (CSPSNR), Y、Cb和Cr分量的MSE分别以主观测试的权重0.695、0.130和0.175加权,比HEVC参考软件中经验的6:1:1组合PSNR[76]和4:1:1组合MSE具有更好的一致性。
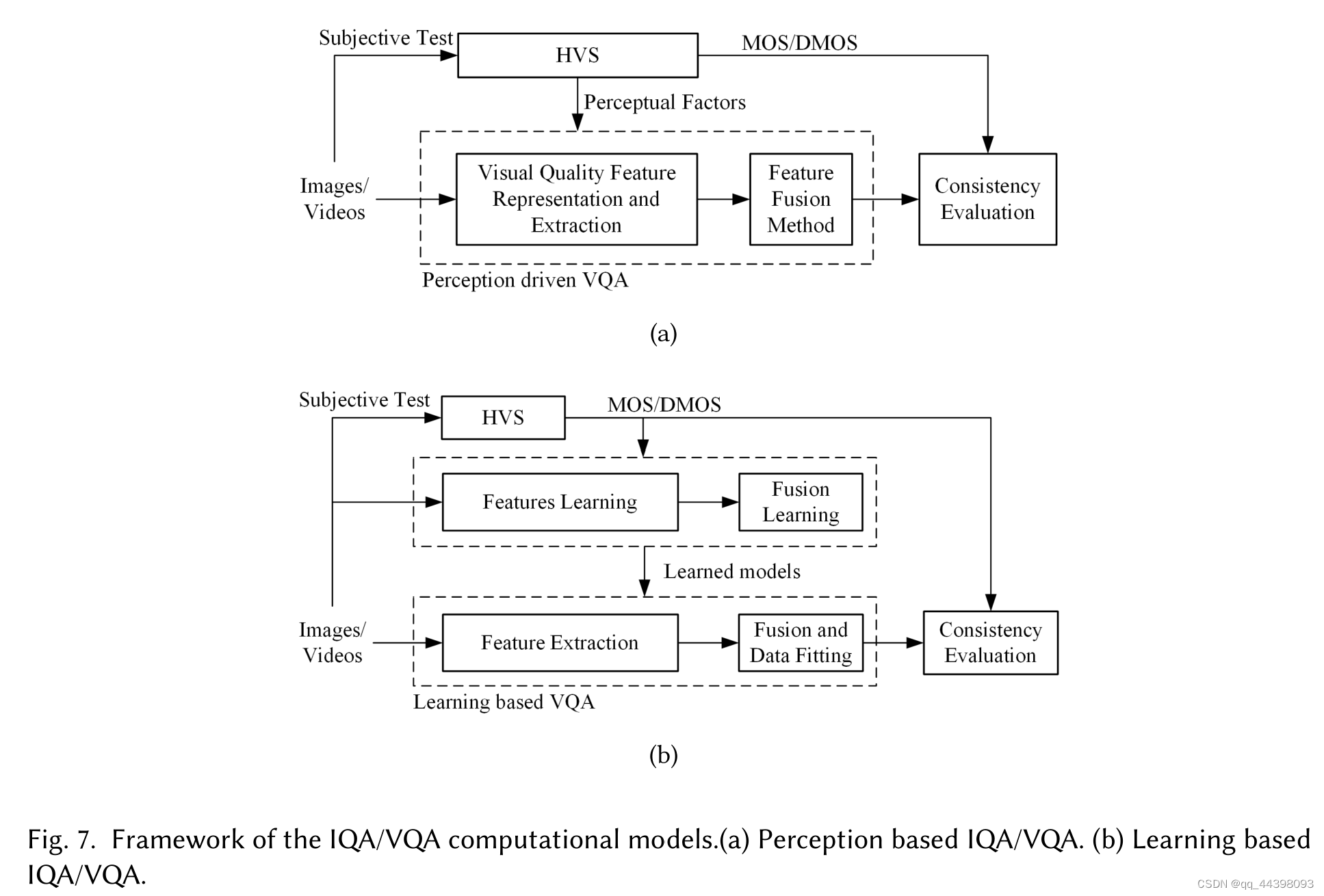
有许多经典的IQA指标都利用了视觉因素。它们的总体框架包括提取有效视觉特征的特征表示和拟合质量分数的融合模型,如下图(a)所示,其中HVS的感知因素为基础,主观测试的MOS/DMOS分数作为基础真值数据进行模型拟合。由于深度神经网络在从数据中挖掘知识和解决预测问题方面的强大能力,Kim等[43]提出了一种基于卷积神经网络(Convolutional neural networks, CNN)的全参考IQA模型,该模型基于数据库的数据分布信息,无需预先了解HVS。Fan等[20]利用multi-expert CNNs对失真类型进行分类,并对每种失真类型的质量进行预测。然而,训练深度CNN需要具有高质量标签的大数据集。此外,这些指标是IQAs,如果应用于评估视频质量,则不会考虑时间信息。
2.VQA模型
除了空间伪影外,压缩过程中还可能引入时间伪影,如闪烁、抖动、浮动等,这在VQA中需要考虑。Li等[51]提出了一种实用的视频流感知VQA,称为视频多方法评估融合(video Multi-Method Assessment Fusion, VMAF)。它通过将抗噪声信噪比(AN-SNR)、细节损失度量(DLM)、视觉信息保真度(VIF)、平均像素差(MCPD)等四个现有指标与支持向量机学习相融合来预测质量分数。Xu等[98]提出了一种基于三维CNN的VQA模型,由两流二维卷积层(用于从扭曲帧和残差帧中学习空间特征)、三维卷积层(用于学习时空特征)和回归层(用于预测质量)组成。
3.总结
尽管VQA是一个研究多年的开放问题,但仍然存在许多具有挑战性的问题和未解决的问题。(1)基于特定应用中的一些视觉属性和特征,开发了许多VQA模型。虽然SSIM和VMAF是衡量压缩视频质量的常用指标,但目前还没有像PSNR那样被普遍认可和广泛使用的感知视觉质量模型。(2)视觉质量数据库的建立需要在可控的环境下进行主观测试,而对大量失真的视觉内容进行数十人被试的评分是非常费力的。(3)之前的大多数VQA都是基于对感知因素的建模,被称为基于感知的VQA方案,如SSIM和MOVIE,而有效的特征提取和特征融合是保证图像准确性的关键。最近,许多基于学习的VQA方案被开发出来,这些学习方案被用于改进特征提取和融合模型。
感知视频编码优化
视频编码的目标是在给定比特率下最大化视觉质量。
1.感知引导比特分配和速率控制
现有的感知引导比特分配算法可分为基于质量度量和基于感知因素两种类型。除了SSIM之外,Xu等[97]还提出了一种基于自由能原理的新型视频质量指标,用于视频编码,将更多的比特分配到质量敏感区域。Gao等人[24]提出了一种速率控制方案,以保持相邻帧之间的图像质量一致。 在另一类中,使用感知因素来利用视频压缩中的视觉冗余。由于HVS对纹理区域更为敏感,Wang等[85]提出了一种基于梯度幅度相似偏差(GMSD)的帧内速率控制方案;在[100]中,分析了空间和时间感知特性,并利用它们将更多的比特分配给更敏感的区域。Wang等人[84]通过考虑纹理复杂性和运动信息,提出了一种基于掩蔽效应的感知模型,然后使用该模型在cpu级别将更少的比特分配给失真不太敏感的掩蔽区域。图8显示了感知优化的位分配流程图,其中包括视觉感知模型和增强的位分配。
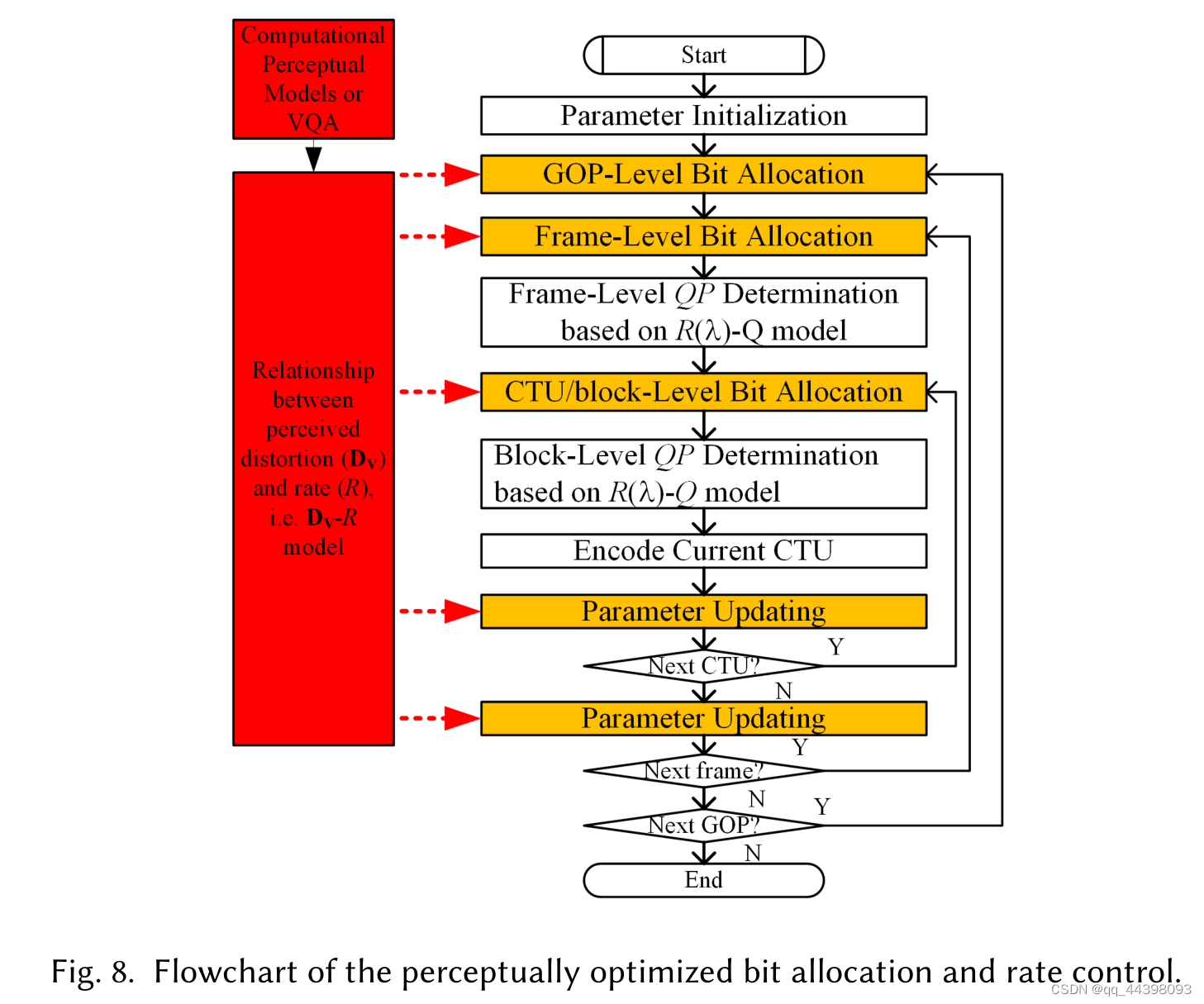
还有一些方面需要完善:(1)HVS 的视觉特性是多个不同视觉部分的复合效果,是一个复杂的非线性系统,计算视觉感知模型通常模拟一两个关键的视觉属性,不是所有的视觉属性都可考虑在内。(2)虽然可以使用感知模型分配比特,但是预测编码和RDO中的块匹配仍然使用基于MSE的失真项,并不能真实的反映HVS中的视觉感知。(3)评价的质量评价指标可能不一致。(4)HVS 是一个复杂的非线性系统,一些可视化模型是非导数的如JND,不能用凸优化求解。
2.感知速率失真优化(PRDO)
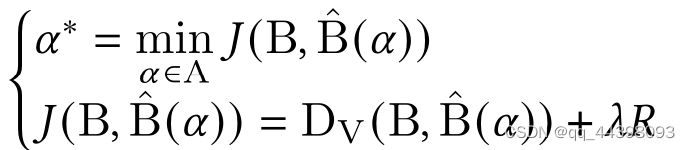
[88]中,基于DCT域SSIM指数,将DCT系数分归一化为感知均匀空间,利用HVS的掩蔽效应确定每个MB的相对感知重要性。在[86]中,基于自由能原理,将输入视频分为简单/规则纹理区域(较敏感)和复杂纹理区域(较不敏感)两类。然后,使用保真度(Dsse)和感知失真(1−Dssim)的加权组合,即DV =w(1−−Dssim)+Dmse作为PRDO中的最终失真度量,其中对纹理简单/规则的敏感区域的感知失真赋予更大的权重w。
第二类是利用JND和掩蔽效应等感知因素来提高RDO。Zhang等[116]提出了一种全参考合成视频质量度量(SVQM)来衡量合成视频的感知质量。
3.感知优化变换和量化
Papadopoulos等人在[64]中调整了量化中的QP,为每个MB分配比特,以反映每个MB的相对重要性。同样,Zhang等人[105]建立了时空域的掩蔽特征与量化参数之间的关系,然后根据视频内容的特征,感知地选择了局部的QP。变换编码可以看作一种降维。基于深度学习的变换利用非线性的CNN提高能量压缩。LR-JNQD和CNN-JNQD,这两种模型能够根据量化步骤调整JNQD水平,对视频编码器的输入进行预处理。为了利用块内部的视觉冗余,[107]提出感知优化自适应量化矩阵。现有工作大多是基于视觉模型对QP步骤和量化矩阵进行优化,如视觉灵敏度和JND,这是基于模型的。由于有更多的数据可用性和更强的非学习表示能力,考虑感知目标或损失函数,研究基于深度学习的变换和量化将是很有前途的方向。
4.基于感知的过滤和视觉增强
由于块的预测和量化,在重构帧中产生伪影严重降低了感知质量。因此提出滤波和视觉增强解决这个问题。相关工作包括环内滤波和环外后处理。滤波会消除伪影但是导致纹理边界模糊。基于CNN的环内滤波进一步实现了7%左右的BDBR增益,提高了视觉质量。第二类是编码循环之外的帧级视觉增强,相关的方法采用L1或L2的模作为损失函数,目睹是提高重建视频与参考视频之间的PSNR。
Guan等[28]提出了一种针对压缩视频的视频质量增强方法,该方法参考了具有较高质量的多个时间相邻帧,包括一个高质量的帧确定子网络和多帧增强CNN。虽然视频质量有所提高,但仍然是用PSNR来衡量,不能真实反映人的感知。Chadha 等[10]提出了基于CNN的深度感知预处理(Deep Perceptual Preprocessing, DPP)来增强视频编码器输入帧的视觉质量。这些滤波器被用作预处理之前平滑难以察觉的视觉细节,从而降低比特率。基于深度学习的方法是学习先验的更有效的解决方案,在训练基于深度学习的视觉质量增强模型时,源视频可以被视为基础事实,并且有足够的标签来学习先验,采用与HVS更一致的视觉质量度量。
5.总结
利用视频编码中的视觉冗余有两种方法,一是基于计算感知模型如CSF JND ROI等,将其作为常见的视觉特征来指导编码控制如比特分配和模式决策。然后用VQA评价压缩视频的质量。二是将VQA模型或其近似作为编码模块的失真度量,选择以最小化感知失真为目标的最优编码模式或参数如RDO和增强。在感知优化视频编码中存在三个挑战:(1)由于HVS的复杂性,建立精确的计算感知模型和适应各种视频应用的VQA具有挑战性。(2)视频编码中有各种编码模块,这些模块都是基于PSNR/MSE 进行开发的,适应视频编码模块具有挑战性。(3)视频编码需要大量使用RD成本比较来确定最优参数。计算复杂性将是感知编码中需要解决的一个重要问题。
编码标准和工具的实验验证
视频编码标准的性能:MSE 越大图像失真越严重;PNSR 值越大,图像质量越好;SSIM衡量两幅图像相似度,值越大越好,最大为1
结论及未来发展方向
感知优化视频编码是利用视觉冗余来进一步提高压缩效率,本文从视觉感知建模、视觉质量评价和视觉感知引导下的视频编码优化三个方面阐述。传统的PSNR不能真实的反映HVS的视觉质量,需要开发VQA模型来评估视频的视觉质量,构建稳定的VQA需要大规模的视频质量数据集,非常费力和耗时。感知视频编码在提高压缩效率方面有很多优点和潜力。
未来研究方向:(1)深度学习优化感知编码。深度学习能发现海量数据中的信息。两个需要解决的问题,一是为深度模型驯良提供足够的数据标签(视觉建模、视觉质量评估)。二是使用深度模型的高复杂性,特别是当它应用于循环编码模块时。(2)QoE建模。视频的感知质量除了与清晰度,还与自然度、低延迟等因素有关,研究QoE相关的视觉因素及其感知模型将有助于视觉信号处理的感知优化。基于学习的方法是解决建模中特征表示和融合问题的一个重要方向。如何将QoE模型应用到视频编码中解决多目标问题是一个挑战。(3)VCM 面向机器的视觉编码。随着深度学习的发展和VCM编码目标的不同,VCM 的深度特征分析、质量评价方法、编码框架、特征压缩算法都受到了关注。(4)超现实和高维视频的感知编码。当前的感知模型如掩蔽、JND、灵敏度和IQA模型以及编码算法,包括RDO、位分配、变换和视觉增强,值得进一步适应更高的位深。对高维视频的三维视觉感知、三维VQA和三维感知编码可以进一步研究。(5)感知优化的深度视觉模型。深度学习在视觉特征表示和数据拟合方面表现出强大的能力。然而,它需要大量带有标签的视觉数据,并且随着特征维数的增加和模型的深入,会导致极高的计算复杂度。HVS 的心理视觉研究成果将有可能用于改进基于深度学习的视觉模型的设计,包括计算感知模型、视觉质量评估、用于视觉表征、重建和识别的感知优化深度架构。
[17]: Qionghai Dai, Jiamin Wu, Jingtao Fan, Feng Xu, and Xun Cao. 2019. Recent advances in computational photography.
IEEE Journal of Selected Topics in Signal Processing 28, 1 (2019), 1–5.
[31]: Mahdi S. Hosseini, Yueyang Zhang, and Konstantinos N. Plataniotis. 2019. Encoding visual sensitivity by maxpol
convolution filters for image sharpness assessment. IEEE Transactions on Image Processing 28, 9 (2019), 4510–4525.
[54]: Huanhua Liu, Yun Zhang, Huan Zhang, Chunling Fan, Sam Kwong, C.-C. Jay Kuo, and Xiaoping Fan. 2020. Deep
learning-based picture-wise just noticeable distortion prediction model for image compression. IEEE Transactions on
Image Processing 29 (2020), 641–656.
[112]: Xinfeng Zhang, Chao Yang, Haiqiang Wang, Wei Xu, and C.-C. Jay Kuo. 2020. Satisfied-user-ratio modeling for
compressed video. IEEE Transactions on Image Processing 29 (2020), 3777–3789.
[114]:Yun Zhang, Huanhua Liu, You Yang, Xiaoping Fan, Sam Kwong, and C. C. Jay Kuo. 2021. Deep learning based just
noticeable difference and perceptual quality prediction models for compressed video. IEEE Transactions on Circuits
and Systems for Video Technology (2021). https://doi.org/10.1109/TCSVT.2021.3076224
[109]:Qiudan Zhang, Xu Wang, Shiqi Wang, Shikai Li, Sam Kwong, and Jianmin Jiang. 2019. Learning to explore intrinsic
saliency for stereoscopic video. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
9741–9750.
[71]:Xiwu Shang, Jie Liang, Guozhong Wang, Haiwu Zhao, Chengjia Wu, and Chang Lin. 2019. Color-sensitivity-based
combined PSNR for objective video quality assessment. IEEE Transactions on Circuits and Systems for Video Technology
29, 5 (2019), 1239–1250.
[20]:Chunling Fan, Yun Zhang, Liangbing Feng, and Qingshan Jiang. 2018. No reference image quality assessment based
on multi-expert convolutional neural networks. IEEE Access 6 (2018), 8934–8943.
[51]:Zhi Li, Anne Aaron, Katsavounidis, Ioannis Moorthy A, and Megha Manohara. 2016. Toward a practical perceptual
video quality metric. In Netflix TechBlog.
[98]:Munan Xu, Junming Chen, Haiqiang Wang, Shan Liu, Ge Li, and Zhiqiang Bai. 2020. C3DVQA: Full-reference video
quality assessment with 3D convolutional neural network. In IEEE International Conference on Acoustics, Speech and
Signal Processing (ICASSP). 4447–4451.
[97]: Long Xu, Weisi Lin, Lin Ma, Yongbing Zhang, Yuming Fang, King Ngi Ngan, Songnan Li, and Yihua Yan. 2016.
Free-energy principle inspired video quality metric and its use in video coding. IEEE Transactions on Multimedia 18, 4
(2016), 590–602.
[24]:Wei Gao, Qiuping Jiang, Ronggang Wang, Siwei Ma, Ge Li, and Sam Kwong. 2022. Consistent quality oriented rate
control in HEVC via balancing intra and inter frame coding. IEEE Transactions on Industrial Informatics 18, 3 (2022),
1594–1604.
[85]:Miaohui Wang, King Ngi Ngan, and Hongliang Li. 2015. An efficient frame-content based intra frame rate control for
high efficiency video coding. IEEE Signal Processing Letters 22, 7 (2015), 896–900.
[100]:Aisheng Yang, Huanqiang Zeng, Lin Ma, Jing Chen, Canhui Cai, and Kai-Kuang Ma. 2016. A perceptual-based rate
control for HEVC. In 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA).
1–5.
[84]:Hao Wang, Li Song, Rong Xie, Zhengyi Luo, and Xiangwen Wang. 2018. Masking effects based rate control scheme
for high efficiency video coding. In 2018 IEEE International Symposium on Circuits and Systems (ISCAS). 1–5.
[88]:Shiqi Wang, Abdul Rehman, Zhou Wang, Siwei Ma, and Wen Gao. 2013. Perceptual video coding based on SSIM-
inspired divisive normalization. IEEE Transactions on Image Processing 22, 4 (2013), 1418–1429.
[86]:Qun Wang, Hui Yuan, Junyan Huo, and Peng Li. 2019. A fidelity-assured rate distortion optimization method for
perceptual-based video coding. In 2019 IEEE International Conference on Image Processing (ICIP). 4135–4139.
[116]:Yun Zhang, Xiaoxiang Yang, Xiangkai Liu, Yongbing Zhang, Gangyi Jiang, and Sam Kwong. 2016. High-efficiency 3D
depth coding based on perceptual quality of synthesized video. IEEE Transactions on Image Processing 25, 12 (2016),
5877–5891.
[64]:M. A. Papadopoulos, Y. Rai, A. V. Katsenou, D. Agrafiotis, P. Le Callet, and D. R. Bull. 2017. Video quality enhancement
via QP adaptation based on perceptual coding maps. In 2017 IEEE International Conference on Image Processing (ICIP).
2741–2745.
[105]:Fan Zhang and David R. Bull. 2016. HEVC enhancement using content-based local QP selection. In 2016 IEEE
International Conference on Image Processing (ICIP). 4215–4219.
[107]:Lei Zhang, Qiang Peng, and Xiao Wu. 2017. Perception-based adaptive quantization for transform-domain Wyner-Ziv
video coding. Multimedia Tools and Applications 76 (08 2017), 16699–16725.
[28]:Zhenyu Guan, Qunliang Xing, Mai Xu, Ren Yang, Tie Liu, and Zulin Wang. 2021. MFQE 2.0: A new approach for
multi-frame quality enh
[10]:Aaron Chadha and Yiannis Andreopoulos. 2021. Deep perceptual preprocessing for video coding. In 2021 IEEE/CVF
Conference on Computer Vision and Pattern Recognition (CVPR). 14847–14856.















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









