







资源地址:http://dblab.xmu.edu.cn/post/movierecommend/
项目介绍
项目流程:首先获取用户id,删除用户之前存在的推荐结果,装载样本评分数据(不同用户对不同电影的评分数据:userid、 movieid、rating、timestamp )。然后装载电影信息数据(从movieinfo表中取出movieid、moviename、typelist)
注:样本评分数据和电影信息数据以.dat文件的形式被传入HDFS中
将样本评分数据切分成3部分,60%用于训练(训练集)、20%用于校验(校验集)、20%用于测试(测试集)
训练不同参数下的模型,并在校验集中校验,找出最佳模型
如何训练呢?
设置参数(隐语义因子的个数、ALS的正则化参数、迭代次数),将设置的参数和训练集作为参数传入到spark MLlib库的ALS()函数中,得到推荐模型,调整参数会得到多个不同的模型。
如何校验?
将校验集装入模型中,得到用户对电影的预测评分,计算预测评分和实际评分的均方根误差,找出多个模型中均方根误差最小的模型作为最佳模型。
用最佳模型预测测试集的评分,并计算预测评分和实际评分的均方根误差,改进最佳模型。
用最佳模型预测某用户对电影信息数据集中的所有电影的评分,选出评分最高的前十部电影。将推荐结果存入数据库recommendresult表中
ALS协同过滤算法最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
在我们研究两个变量(x,y)之间的相互关系时,通常可以得到一系列成对的数据(x1,y1.x2,y2… xm,ym);将这些数据描绘在x -y直角坐标系中,若发现这些点在一条直线附近,可以令这条直线方程如(式1-1)。
其中:a0、a1 是任意实数
为建立这直线方程就要确定a0和a1,应用《最小二乘法原理》,将实测值Yi与利用(式1-1)计算值(Yj=a0+a1X)的离差(Yi-Yj)的平方和
最小为“优化判据”。
令:φ =
(式1-2)
把(式1-1)代入(式1-2)中得:
φ =
(式1-3)
当
最小时,可用函数 φ 对a0、a1求偏导数,令这两个偏导数等于零。
∑2(a0 + a1Xi - Yi)(式1-4)
∑2Xi(a0 + a1Xi - Yi)(式1-5)
亦即:
na0 + (∑Xi ) a1 = ∑Yi (式1-6)
(∑Xi ) a0 + (∑Xi^2 ) a1 = ∑(XiYi) (式1-7)
得到的两个关于a0、 a1为未知数的两个方程组,解这两个方程组得出:
a0 = (∑Yi) / n - a1(∑Xi) / n (式1-8)
a1 = [n∑Xi Yi - (∑Xi ∑Yi)] / [n∑Xi2 - (∑Xi)2 )] (式1-9)
这时把a0、a1代入(式1-1)中, 此时的(式1-1)就是我们回归的元线性方程即:数学模型。
在回归过程中,回归的关联式不可能全部通过每个回归数据点(x1,y1. x2,y2…xm,ym),为了判断关联式的好坏,可借助相关系数“R”,统计量“F”,剩余标准偏差“S”进行判断;“R”越趋近于 1 越好;“F”的绝对值越大越好;“S”越趋近于 0 越好。
R = [∑XiYi - m (∑Xi / m)(∑Yi / m)]/ SQR{[∑Xi2 - m (∑Xi / m)2][∑Yi2 - m (∑Yi / m)2]} (式1-10) *
在(式1-10)中,m为样本容量,即实验次数;Xi、Yi分别为任意一组实验数据X、Y的数值
需求分析
电影推荐系统可以根据用户的兴趣、特点、需求等,为用户提供信息服务。与一般的搜索引擎不同的是,推荐系统是通过研究用户自身的兴趣偏好来进行个性化的推荐。一个好的推荐系统,能自动挖掘用户的兴趣点,引导用户发现自己的信息需求,同时,通过为用户提供个性化的推荐服务从而与用户建立联系,使得用户对推荐系统产生依赖。
电影推荐是根据当前热门的电影,研究用户的一些个性化数据,为用户提供个性化的视频推荐服务,以增加用户黏度,从而提高视频网站流量。对在线电影提供商而言,电影推荐系统的推荐效率对公司的经济效益会产生直接的影响,甚至会影响到公司的发展。
概要设计
1、总体功能模块设计
本文设计的电影推荐系统包含以下三大功能模块 :用户
注册登录、电影评分、电影推荐。其中电影推荐模块是系统的核
心模块。
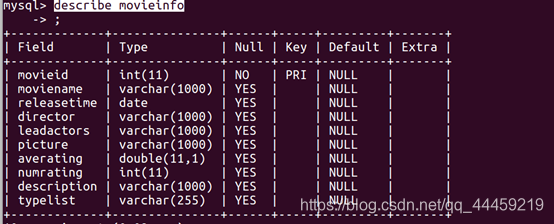
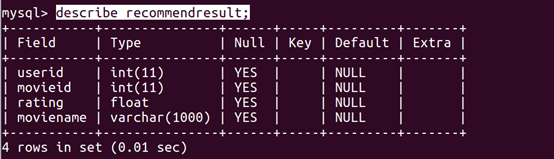
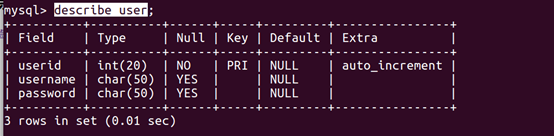
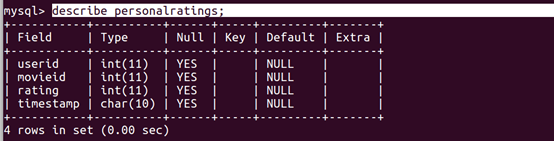
2、 数据库设计
本系统采用 MySQL 数据库,在 Django model[9] 基础上
额外设计了 4 个数据表 :movieinfo、personalratings、recommendresult 、user。
四张表的结构如下
movieinfo
recommendresult
user
personalratings
详细设计及实现
基于ALS协同过滤算法的电影推荐的实现过程
1. 把数据集ETL到HDFS中
准备数据集
本案例采用的数据集为movie_recommend.zip,这些数据集老师为我们准备好了,也可以自己在厦门大学数据库实验室去下载。
movie_recommend.zip中包含3个数据集:
用户评分数据集ratings.dat
样本评分数据集personalRatings.txt
电影数据集movies.dat
使用如下命令启动Hadoop:
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh
接下来再建立一个用于存放本案例数据集的HDFS目录input_spark,如果之前还没有创建该目录,则使用如下命令创建:
$ cd /usr/local/hadoop
$ ./bin/hdfs dfs -mkdir /input_spark
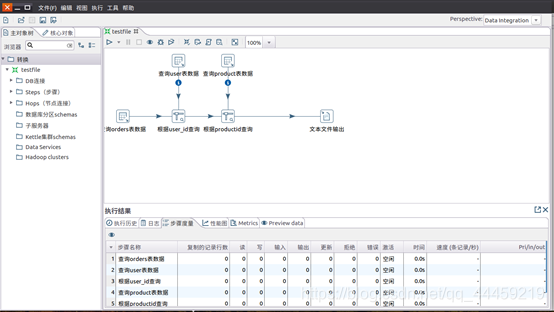
2.使用Kettle工具把数据ETL到HDFS中
关于Kettle这里给出地址去学习安装使用:http://dblab.xmu.edu.cn/blog/kettle/#more-1901
使用Kettle把数据加载到HDFS中,分别把ratings.dat、personalRatings.txt、movies.dat、user.dat上传到HDFS的“input_spark”目录中。
通过这个小实验我们大概了解了如何使用Kettle的工作流程。
传输完毕后,可以在Linux终端中使用HDFS Shell命令查看刚才传输到HDFS中的各个文件。比如,可以查看ratings.dat的前五行数据:

2. 编写Spark程序实现电影推荐

代码:
package recommend
import java.io.File
import scala.io.Source
import org.apache.log4j.{ Level, Logger }
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd._
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
object MovieLensALS {
def main(args: Array[String]) {
// 屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
if (args.length != 5) {
println("Usage: /usr/local/spark/bin/spark-submit --class recommend.MovieLensALS " +
"Spark_Recommend.jar movieLensHomeDir personalRatingsFile bestRank bestLambda bestNumiter")
sys.exit(1)
}
// 设置运行环境
val conf = new SparkConf().setAppName("MovieLensALS").setMaster("local[1]")
val sc = new SparkContext(conf)
// 装载参数二,即用户评分,该评分由评分器生成
val myRatings = loadRatings(args(1))
val myRatingsRDD = sc.parallelize(myRatings, 1)
// 样本数据目录
val movieLensHomeDir = args(0)
// 装载样本评分数据,其中最后一列Timestamp取除10的余数作为key,Rating为值,即(Int,Rating)
//ratings.dat原始数据:用户编号、电影编号、评分、评分时间戳
val ratings = sc.textFile(new File(movieLensHomeDir, "ratings.dat").toString).map { line =>
val fields = line.split("::")
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
//装载电影目录对照表(电影ID->电影标题)
//movies.dat原始数据:电影编号、电影名称、电影类别
val movies = sc.textFile(new File(movieLensHomeDir, "movies.dat").toString).map { line =>
val fields = line.split("::")
(fields(0).toInt, fields(1).toString())
}.collect().toMap
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
// 将样本评分表以key值切分成3个部分,分别用于训练 (60%,并加入用户评分), 校验 (20%), and 测试 (20%)
// 该数据在计算过程中要多次应用到,所以cache到内存
val numPartitions = 4
// training训练样本数据
val training = ratings.filter(x => x._1 < 6) //取评分时间除10的余数后值小于6的作为训练样本
.values
.union(myRatingsRDD) //注意ratings是(Int,Rating),取value即可
.repartition(numPartitions)
.cache()
// validation校验样本数据
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8) //取评分时间除10的余数后值大于等于6且小于8分的作为校验样本
.values
.repartition(numPartitions)
.cache()
// test测试样本数据
val test = ratings.filter(x => x._1 >= 8).values.cache() //取评分时间除10的余数后值大于等于8分的作为测试样本
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
// 训练不同参数下的模型,并在校验集中验证,获取最佳参数下的模型
val ranks = List(8, 12) //模型中隐语义因子的个数
val lambdas = List(0.1, 10.0) //是ALS的正则化参数
val numIters = List(10, 20) //迭代次数
var bestModel: Option[MatrixFactorizationModel] = None //最好的模型
var bestValidationRmse = Double.MaxValue //最好的校验均方根误差
var bestRank = args(2).toInt //最好的隐语义因子的个数
var bestLambda = args(3).toDouble //最好的ALS正则化参数
var bestNumIter = args(4).toInt //最好的迭代次数
//val model = ALS.train(training, bestRank, bestNumIter, bestLambda) //如果是从外部传入参数,则使用该语句训练模型
//如果不使用外部传入的参数,而是使用上面定义的ranks、lambdas和numIters的列表值进行模型训练,则使用下面的for循环语句训练模型
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda) //训练样本、隐语义因子的个数、迭代次数、ALS的正则化参数
// model训练模型
//输入训练模型、校验样本、校验个数
val validationRmse = computeRmse(model, validation, numValidation) // 校验模型结果
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
// 用最佳模型预测测试集的评分,并计算和实际评分之间的均方根误差
val testRmse = computeRmse(bestModel.get, test, numTest)
//创建一个naïve baseline和最好的模型比较
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse =
math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean)
//提高了baseline的最佳模型
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")
// 推荐前5部最感兴趣的电影,注意要剔除用户已经评分的电影
val myRatedMovieIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get
.predict(candidates.map((1, _)))
.collect()
.sortBy(-_.rating)
.take(5)
var i = 1
println("Movies recommended for you(用户ID:推荐电影ID:推荐分数:推荐电影名称):")
recommendations.foreach { r =>
println( r.user + ":"+ r.product + ":"+ r.rating+":" + movies(r.product))
i += 1
}
val recommendations2 = bestModel.get
.predict(candidates.map((2, _)))
.collect()
.sortBy(-_.rating)
.take(5)
var i2 = 1
recommendations2.foreach { r =>
println( r.user + ":"+ r.product + ":"+ r.rating+":" + movies(r.product))
i2 += 1
}
val recommendations3 = bestModel.get
.predict(candidates.map((3, _)))
.collect()
.sortBy(-_.rating)
.take(5)
var i3 = 1
recommendations3.foreach { r =>
println( r.user + ":"+ r.product + ":"+ r.rating+":" + movies(r.product))
i3 += 1
}
val recommendations4 = bestModel.get
.predict(candidates.map((4, _)))
.collect()
.sortBy(-_.rating)
.take(5)
var i4 = 1
recommendations4.foreach { r =>
println( r.user + ":"+ r.product + ":"+ r.rating+":" + movies(r.product))
i4 += 1
}
sc.stop()
}
/** 校验集预测数据和实际数据之间的均方根误差 **/
//输入训练模型、校验样本、校验个数
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = {
val predictions = model.predict(data.map(x => (x.user, x.product))) //调用预测的函数
val mapuser = data.map(x => (x.user))
val mapproduct = data.map(x => (x.product))
val maprating = data.map(x => (x.rating))
// 输出predictionsAndRatings预测和评分
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
/** 装载用户评分文件 **/
def loadRatings(path: String): Seq[Rating] = {
val lines = Source.fromFile(path).getLines()
val ratings = lines.map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}.filter(_.rating > 0.0)
if (ratings.isEmpty) {
sys.error("No ratings provided.")
} else {
ratings.toSeq
}
}
}
运行结果:
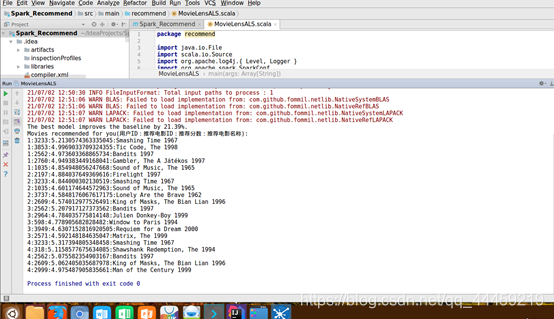
3. 应用程序JAR包在Spark环境中运行
为了能够把应用程序部署到Spark环境中运行,需要使用IDEA工具对程序进行打包,生成应用程序JAR包。
在IDEA工程界面中,打开菜单“File->Project Structure”。
然后,会弹出如下图所示界面,请依次点击“Artifacts”、绿色加号、“JAR”和“From modules with dependencies…”。
然后,在弹出的界面中(如下图所示),点击“Main Class”右边的省略号按钮。在弹出的界面中,在搜索文本框中输入“MovieLensALS”,再点击OK按钮。 然后,会返回到如下图所示界面,把“Directory for META-INF/MANIFEST.MF“设置为如下目录:
/home/linziyu/IdeaProjects/Spark_Recommend”,点击“OK”按钮。 在“Output Layout”选项卡中,删除所有带Extracted开头的JAR包,只保留Spark_Recommend.jar和‘Spark_Recommend’ compile output,最后点击“OK”即可。 最后点击顶部菜单中的“Build”菜单,在弹出的子菜单中点击“Build Artifacts…”。 然后,点击“Build”,就开始打包了。最后的jar包路径是: “~/IdeaProjects/Spark_Recommend/out/artifacts/Spark_Recommend_jar/ Spark_Recommend.jar”。
4.把jar包提交到spark中运行
命令如下:
cd /usr/local/spark bin/spark-submit --class recommend.MovieLensALS
~/IdeaProjects/Spark_Recommend/out/artifacts/Spark_Recommend_jar/Spark_Recommend.jar
/input_spark ~/Downloads/personalRatings.dat 10 5 10
在命令中,为Spark_Recommend程序提供了5个参数,其中,第1个参数“/input_spark”是HDFS文件系统中的目录,该目录下包含了两个文件movies.dat和ratings.dat(如果不存在该目录和文件,请使用HDFS命令创建目录并上传数据文件)。第2个参数是personalRatings.dat文件路径(这里是一个放在Linux本地文件系统中的文件,没有存放在HDFS中),第3、4和5个参数分别是隐语义因子个数、ALS正则化参数、迭代次数。
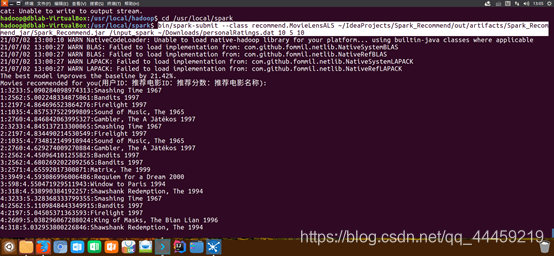
5. 使用Node.js在网页中展现结果
1.创建项目目录
在Linux终端中,使用如下命令创建项目目录并完成初始化:
$ cd ~ #进入当前Linux用户的主目录
$ mkdir mysparkapp #创建一个目录
$ cd mysparkapp
$ npm init
在输入初始化项目命令“npm init”后,终端会提示输入项目的相关信息,并自动把这些信息记录在package.json中。如果想进行快捷开发,不想手动输入项目信息,只需要一直按“Enter”键即可,接受默认的自动配置。
2.安装相关模块
在Linux终端中继续如下命令来安装Express、jade和body-parser模块:
$ npm install express --save
$ npm install jade --save
$ npm install body-parser --save
通过上面命令安装的模块,都会放在当前项目文件夹下的node_modules文件夹下,并更新到package.json文件中。Node.js引用该模块的时候,会自动从node_modules文件夹下寻找模块。
3. 创建服务器
在mysparkapp项目目录中,创建一个名为index.js的文件,这个文件是整个网页应用的入口,该文件的内容如下:
const express = require('express')
const bodyParser = require('body-parser')
const spawnSync = require('child_process').spawnSync
const app = express();
// 设置模板引擎
app.set('views','./views')
app.set('view engine', 'jade')
// 添加body-parser解析post过来的数据
app.use(bodyParser.urlencoded({extended: false}))
app.use(bodyParser.json())
app.get('/', function (req, res) {
res.render('index', {title: '电影推荐系统', message: '厦门大学数据库实验室!'})
})
app.post('/',function(req, res){
const path = req.body.path.trim() || '/input_spark'
const myRatings = req.body.myRatings.trim() || '~/Downloads/personalRatings.dat'
const bestRank = req.body.bestRank.trim() || 10
const bestLambda = req.body.bestLambda.trim() || 5
const bestNumIter = req.body.bestNumIter.trim() || 10
let spark_submit = spawnSync('/usr/local/spark/bin/spark-submit',['--class', 'recommend.MovieLensALS',' ~/IdeaProjects/Spark_Recommend/out/artifacts/Spark_Recommend_jar/Spark_Recommend.jar', path, myRatings, bestRank, bestLambda, bestNumIter],{ shell:true, encoding: 'utf8' })
res.render('index', {title: '电影推荐系统', message: '厦门大学数据库实验室!', result: spark_submit.stdout})
})
const server = app.listen(3000, function () {
const host = server.address().address;
const port = server.address().port;
console.log('Example app listening at http://%s:%s', host, port);
});
上面的代码用于启动一个HTTP服务器,并监听从 3000 端口进入的所有连接请求。
4. 添加模板文件
在当前项目目录下添加名称为“views”的子目录,并在views目录下添加一个Jade模板文件index.jade,具体方法是,在Linux终端中输入如下命令:
$ cd ~/mysparkapp #设置当前目录
$ mkdir views #创建一个views目录
$ cd views
$ vim index.jade #使用vim编辑器新建一个index.jade文件
在index.jade文件中输入如下信息:
html
head
title!= title
body
h1!= message
form(action='/', method='post')
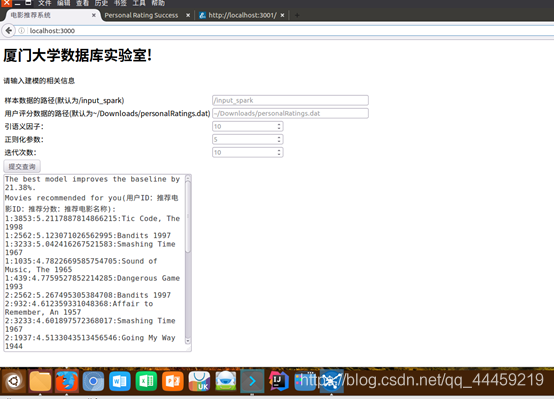
p 请输入建模的相关信息
table(border=0)
tr
td 样本数据的路径(默认为/input_spark)
td
input(style='width:350px',placeholder='/input_spark',name='path')
tr
td 用户评分数据的路径(默认为~/Downloads/personalRatings.dat)
td
input(style='width:350px',placeholder='~/Downloads/personalRatings.dat ',name='myRatings')
tr
td 引语义因子:
td
input(placeholder='10',type='number',min='8',max='12',name='bestRank')
tr
td 正则化参数:
td
input(placeholder='5',type='number',min='0',max='10',step='0.1',name='bestLambda')
tr
td 迭代次数:
td
input(placeholder='10',type='number',min='10',max='20',name='bestNumIter')
input(type='submit')
br
textarea(rows='20', cols='40')!=result
保存该文件并退出vim编辑器。
5. 在网页中调用程序并展现结果
在Linux终端中输入如下命令启动该HTTP服务器:
$ node index.js
在Linux系统中打开一个浏览器,再次访问网址“localhost:3000”,会出现如下图所示的网页:
6.使用Node完成电影推荐系统
代码:
Node.js项目代码
myapp.js代码如下:
/**
* express接收html传递的参数
/
var express=require('express');
var bodyParser = require('body-parser')
const exec = require('child_process').exec
var app=express();
var mysql=require('mysql');
app.set('view engine', 'jade');
app.set('views', './views');
app.use(bodyParser.urlencoded({extended: false}))
app.use(bodyParser.json())
var userid;
var name;
var movieid = new Array(10);
/**
* 配置MySQL
/
var connection = mysql.createConnection({
host : '127.0.0.1',
user : 'root',
password : '123456',
database : 'tuijian',
port:'3306'
});
connection.connect();
/**
* 跳转到网站首页
*/
app.get('/',function (req,res) {
res.render('index',{title:'电影推荐系统'});
})
/**
* 跳转到登录界面
*/
app.get('/login',function (req,res) {
res.render('login',{title:'登录'});
})
/**
* 实现登录验证功能,并随机读取数据库的电影
*/
app.post('/login',function (req,res) {
name=req.body.username.trim();
var pwd=req.body.pwd.trim();
console.log('username:'+name+'password:'+pwd);
var selectSQL = "select * from userinfo where username = '"+name+"' and password = '"+pwd+"'";
connection.query(selectSQL,function (err,rs) {
if(rs.length==0){
res.render('faile',{title:'登录失败'});
}
else{
userid=rs[0].userid;
console.log(rs);
console.log('ok');
var selectm = "SELECT * FROM movieinfo where movieid < 7000 ORDER BY rand() LIMIT 10";
connection.query(selectm,function (err,rs) {
for(var i=0;i<10;i++){
movieid[i]=rs[i].movieid;
}
console.log(movieid);
res.render('recommendtest',{title:'推荐测试',rs:rs,message:name});
})
}
})
})
/**
* 跳转到注册页面
*/
app.get('/registerpage',function (req,res) {
res.render('registerpage',{title:'注册'});
})
/**
* 实现注册功能
*/
app.post('/register',function (req,res) {
name=req.body.username.trim();
var pwd=req.body.pwd.trim();
var user={username:name,password:pwd};
connection.query('insert into userinfo set ?',user,function (err,rs) {
if (err) throw err;
console.log('ok');
res.render('ok',{title:'Welcome User',message:name});
})
})
var server=app.listen(3000,function () {
console.log("userloginjade server start......");
})
/**
* 跳转到主页面
*/
app.get('/index',function (req,res) {
res.render('index',{title:'主页'});
})
/**
* 选择电影
*/
app.post('/tijiao',function (req,res) {
var rating = new Array(10);
rating[0] = req.body.a;
rating[1] = req.body.b;
rating[2] = req.body.c;
rating[3] = req.body.d;
rating[4] = req.body.e;
rating[5] = req.body.f;
rating[6] = req.body.g;
rating[7] = req.body.h;
rating[8] = req.body.i;
rating[9] = req.body.j;
for(var i=0;i<10;i++)
{
if(rating[i]!=0)
{
var user={userid:userid,movieid:movieid[i],rating:rating[i],ratingtime:1};
connection.query('insert into ratings set ?',user,function (err,rs) {
if (err) throw err;
console.log('ok');
})
}
}
const jarStr = '/usr/local/spark/bin/spark-submit --class "MoviesRecommond" /home/hadoop/MoviesRecommond.jar '+userid
exec(jarStr, function(err, stdout, stderr){
if(stderr){
console.log('ok1111');
var selectm = "select * from recommend";
var movid = new Array(10);
connection.query(selectm,function (err,rs) {
for(var i=0;i<10;i++){
movid[i]=rs[i].movieid;
}
console.log(movid[0]);
var selectm = "select * from movieinfo where movieid in("+movid[0]+","+movid[1]+","+movid[2]+","+movid[3]+","+movid[4]+","+movid[5]+","+movid[6]+","+movid[7]+","+movid[8]+","+movid[9]+")";
connection.query(selectm,function (err,rs) {
res.render('recommend',{title:'推荐结果',rs:rs,message:name});
})
})
}
})
})
1 登录界面代码
登录界面代码如下:
html
head
title!= title
style.
body{
background-image:url(https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1537261291133&di=c04553d39f158272a36be6e3ec0c8071&imgtype=0&src=http%3A%2F%2Fh.hiphotos.baidu.com%2Fzhidao%2Fpic%2Fitem%2Fc2fdfc039245d6885bc3be94a2c27d1ed21b2438.jpg);
}
#log{
padding-top: 2px;
margin-top: 10%;
margin-left: 37%;
background: white;
width: 25%;
height: 40%;
text-align: center;
}
body
div#log
form(action='/login', method='post')
h1 用户登录
br
span 账户:
input(type='text',name='username')
br
span 密码:
input(type='password',name='pwd')
br
br
input(type='submit',value='登录')
br
a(href='/registerpage', title='注册')注册
br
a(href='/index',title='主页')返回主页
2 注册界面代码
注册界面代码如下:
html
head
title!= title
style.
body{
background-image:url(https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1537261291133&di=c04553d39f158272a36be6e3ec0c8071&imgtype=0&src=http%3A%2F%2Fh.hiphotos.baidu.com%2Fzhidao%2Fpic%2Fitem%2Fc2fdfc039245d6885bc3be94a2c27d1ed21b2438.jpg);
}
#reg{
padding-top: 2px;
margin-top: 10%;
margin-left: 37%;
background: white;
width: 25%;
height: 40%;
text-align: center;
}
body
div#reg
form(action='/register', method='post')
h1 用户注册
br
span 账户:
input(type='text',name='username')
br
span 密码:
input(type='password',name='pwd')
br
br
input(type='submit',value='注册')
3 登录失败代码
登录失败界面代码如下:
html
head
title!=title
style.
body{
background-image:url(https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1537261291133&di=c04553d39f158272a36be6e3ec0c8071&imgtype=0&src=http%3A%2F%2Fh.hiphotos.baidu.com%2Fzhidao%2Fpic%2Fitem%2Fc2fdfc039245d6885bc3be94a2c27d1ed21b2438.jpg);
text-align:center;
}
body
h1 登录失败请重试
a(href='/login', title='登录')返回登录
4 主页界面代码
主页界面代码如下:
html
head
title!=title
meta(charset='utf-8')
meta(name='description')
meta(name='keywords')
meta(name='author')
link(rel='shortcut icon', href='http://eduppp.cn/images/logo4.gif')
link(rel='apple-touch-icon', href='http://eduppp.cn/images/logo.gif')
style
include css/index.css
style(type='text/css').
#frame {/*----------图片轮播相框容器----------*/
position: absolute; /*--绝对定位,方便子元素的定位*/
width: 1500px;
height: 75%;
overflow: hidden;/*--相框作用,只显示一个图片---*/
border-radius:5px;
}
#dis {/*--绝对定位方便li图片简介的自动分布定位---*/
position: absolute;
left: -50px;
top: -10px;
opacity: 0.5;
}
#dis li {
display: inline-block;
width: 200px;
height: 20px;
margin: 0 650px;
float: left;
text-align: center;
color: #fff;
border-radius: 10px;
background: #000;
}
#photos img {
float: left;
width:1500px;
height:75%;
}
#photos {/*---设置总的图片宽度--通过位移来达到轮播效果----*/
position: absolute;z-index:9px;
width: calc(1500px * 5);/*---修改图片数量的话需要修改下面的动画参数*/
}
.play{
animation: ma 20s ease-out infinite alternate;/**/
}
@keyframes ma {/*---每图片切换有两个阶段:位移切换和静置。中间的效果可以任意定制----*/
0%,20% { margin-left: 0px; }
25%,40% { margin-left: -1500px; }
45%,60% { margin-left: -3000px; }
65%,80% { margin-left: -4500px; }
85%,100% { margin-left: -6000px; }
}
.num{
position:absolute;z-index:10;
display:inline-block;
right:10px;top:550px;
border-radius:100%;
background:#778899;
width:50px;height:50px;
line-height:50px;
cursor:pointer;
color:#fff;
background-clor:rgba(0,0,0,0.5);
text-align:center;
opacity:0.8;
}
.num:hover{background:#000;}
.num:hover,#photos:hover{animation-play-state:paused;}
.num:nth-child(2){margin-right:60px}
.num:nth-child(3){margin-right:120px}
.num:nth-child(4){margin-right:180px}
.num:nth-child(5){margin-right:240px}
#a1:hover ~ #photos{animation: ma1 .5s ease-out forwards;}
#a2:hover ~ #photos{animation: ma2 .5s ease-out forwards;}
#a3:hover ~ #photos{animation: ma3 .5s ease-out forwards;}
#a4:hover ~ #photos{animation: ma4 .5s ease-out forwards;}
#a5:hover ~ #photos {animation: ma5 .5s ease-out forwards;}
@keyframes ma1 {0%{margin-left:-1200px;}100%{margin-left:-0px;} }
@keyframes ma2 {0%{margin-left:-1200px;}100%{margin-left:-1500px;} }
@keyframes ma3 {100%{margin-left:-3000px;} }
@keyframes ma4 {100%{margin-left:-4500px;} }
@keyframes ma5 {100%{margin-left:-6000px;} }
body
div#navigation 团队9影片推荐系统
div#logreg
input(type='submit',value='登录',οnclick="window.location='/login'")
input(type='submit', value='注册',οnclick="window.location='/registerpage'")
div#mid
#frame
a#a5.num 5
a#a4.num 4
a#a3.num 3
a#a2.num 2
a#a1.num 1
#photos.play
img(src='http://img05.tooopen.com/products/20150130/44128217.jpg')
img(src='http://image.17173.com/bbs/v1/2012/11/14/1352873759491.jpg')
img(src='http://t1.27270.com/uploads/tu/201502/103/5.jpg')
img(src='http://img.doooor.com/img/forum/201507/15/171203xowepc3ju9n9br9z.jpg')
img(src='http://4493bz.1985t.com/uploads/allimg/170503/5-1F503140J0.jpg')
ul#dis
li 魔戒:霍比特人
li 魔境仙踪
li 阿凡达
li 大圣归来
li 拆弹专家
5 评分界面代码
评分界面代码如下:
html
head
title!= title
style
include css/recommendtest.css
style.
span{
width:295px;
height:15px;
line-height:15px;
overflow:hidden;
margin: 0 auto;
}
.movie select{
margin: 0 auto;
text-align:center;
position:absolute;
}
body
div#top 请在下面选择你喜欢的电影并评分
div#user
欢迎: #{message}
input(type='submit', value='退出' οnclick="window.location='/index'")
form(action='/tijiao', method='post')
div#mid
div#movie
img(src=rs[0].picture+"")
span 电影名:#{rs[0].moviename}
br
select(name='a')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[1].picture+"")
span 电影名:#{rs[1].moviename}
br
select(name='b')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[2].picture+"")
span 电影名:#{rs[2].moviename}
br
select(name='c')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[3].picture+"")
span 电影名:#{rs[3].moviename}
br
select(name='d')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[4].picture+"")
span 电影名:#{rs[4].moviename}
br
select(name='e')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[5].picture+"")
span 电影名:#{rs[5].moviename}
br
select(name='f')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[6].picture+"")
span 电影名:#{rs[6].moviename}
br
select(name='g')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[7].picture+"")
span 电影名:#{rs[7].moviename}
br
select(name='h')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[8].picture+"")
span 电影名:#{rs[8].moviename}
br
select(name='i')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#movie
img(src=rs[9].picture+"")
span 电影名:#{rs[9].moviename}
br
select(name='j')
option(value='0') 未选择
option(value='1') 1
option(value='2') 2
option(value='3') 3
option(value='4') 4
option(value='5') 5
div#buttom
input(type='submit', value='提交')
6 推荐界面代码
推荐界面代码如下:
html
head
title!= title
style
include css/recommend.css
style.
img{
border:0
}
body{
behavior:url("csshover.htc");
text-align:center;
}
#movie span{
display:none;
text-decoration:none;
height:330px;
//line-height:2px;
overflow:hidden;
text-align:left;
}
#movie:hover{
cursor:pointer;
}
#movie:hover span {
display:block;
position:absolute;
bottom:0;
left:0;
color:#FFF;
width:295px;
z-index:10;
background:#000;
filter:alpha(opacity=60);
-moz-opacity:0.5;
opacity:0.5;
}
body
div#top 以下是为你推荐的10部电影
div#user
欢迎: #{message}
input(type='submit', value='退出' οnclick="window.location='/index'")
form(action='/tijiao', method='post')
div#mid
div#movie
img(src=rs[0].picture+"")
span
|电影名:#{rs[0].moviename}
br
|电影评分:#{rs[0].averating}
br
|电影简介:#{rs[0].description}
div#movie
img(src=rs[1].picture+"")
span
|电影名:#{rs[1].moviename}
br
|电影评分:#{rs[1].averating}
br
|电影简介:#{rs[1].description}
div#movie
img(src=rs[2].picture+"")
span
|电影名:#{rs[2].moviename}
br
|电影评分:#{rs[2].averating}
br
|电影简介:#{rs[2].description}
div#movie
img(src=rs[3].picture+"")
span
|电影名:#{rs[3].moviename}
br
|电影评分:#{rs[3].averating}
br
|电影简介:#{rs[3].description}
div#movie
img(src=rs[4].picture+"")
span
|电影名:#{rs[4].moviename}
br
|电影评分:#{rs[4].averating}
br
|电影简介:#{rs[4].description}
div#movie
img(src=rs[5].picture+"")
span
|电影名:#{rs[5].moviename}
br
|电影评分:#{rs[5].averating}
br
|电影简介:#{rs[5].description}
div#movie
img(src=rs[6].picture+"")
span
|电影名:#{rs[6].moviename}
br
|电影评分:#{rs[6].averating}
br
|电影简介:#{rs[6].description}
div#movie
img(src=rs[7].picture+"")
span
|电影名:#{rs[7].moviename}
br
|电影评分:#{rs[7].averating}
br
|电影简介:#{rs[7].description}
div#movie
img(src=rs[8].picture+"")
span
|电影名:#{rs[8].moviename}
br
|电影评分:#{rs[8].averating}
br
|电影简介:#{rs[8].description}
div#movie
img(src=rs[9].picture+"")
span
|电影名:#{rs[9].moviename}
br
|电影评分:#{rs[9].averating}
br
|电影简介:#{rs[9].description}
div#buttom
7 Pom.xml代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
8 MoviesRecommond代码
import java.sql.DriverManager
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SQLContext, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object MoviesRecommond {
def main(args: Array[String]) {
//获取用户id
val userid = if(args.size != 0) args(0).toInt else 6100
//val userid = 4;
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//创建入口对象
val conf = new SparkConf().setMaster("local[4]").setAppName("MoviesRecommond")
val sc = new SparkContext(conf)
//评分训练总数据集,元组格式 (args(1) + "/ratings.dat")
val ratingsList_Tuple = sc.textFile("file:///home/hadoop/下载/ratings.dat").map { lines =>
val fields = lines.split("::")
(fields(0).toInt, fields(1).toInt, fields(2).toDouble, fields(3).toLong % 10)//这里将timespan这列对10做取余操作
}
//评分训练总数据集,模拟键值对形式,键是0-9中的一个数字,值是Rating类型
val ratingsTrain_KV = ratingsList_Tuple.map(x =>
(x._4, Rating(x._1, x._2, x._3)))
//打印出从ratings.dat中,我们从多少个用户和电影之中得到了多少条评分记录
println("得到 " + ratingsTrain_KV.count()
+ "数据 来自 " + ratingsTrain_KV.map(_._2.user).distinct().count()
+ "用户 在 " + ratingsTrain_KV.map(_._2.product).distinct().count() + " movies")
// get 1000209ratings from 6040users on 3706movies
//从mysql中提取数据
val spark = SparkSession.builder().appName("MoviesRecommond").master("local[2]").getOrCreate()
val jdbcDF = spark.read.format("jdbc").
option("url", "jdbc:mysql://localhost:3306/personrating").
option("driver","com.mysql.jdbc.Driver").
option("dbtable", "ratings").
option("user", "root").
option("password", "123").load()
val myRatedData_Rating = jdbcDF.where("userid="+userid).rdd.map(x => Rating(x(0).toString.toInt,x(2).toString.toInt,x(3).toString.toDouble))
//jdbcDF.show();
//设置分区数
val numPartitions = 3
//训练数据
val traningData_Rating = ratingsTrain_KV.filter(_._1 < 8)
.values//注意,由于原本的数据集是伪键值对形式的,而当做训练数据只需要RDD[Rating]类型的数据,即values集合
.union(myRatedData_Rating)//使用union操作将我的评分数据加入训练集中,以做为训练的基准
.repartition(numPartitions)
.cache()
//测试数据
val testData_Rating = ratingsTrain_KV.filter(x=>x._1 >= 8 && x._1 <= 9)
.values
.cache()
//打印出用于训练数据集分别是多少条记录
println("训练数据 : " + traningData_Rating.count()+ " 测试数据 : " + testData_Rating.count())
// training data's num : 821160 validate data's num : 198919 test data's num : 199049
//开始模型训练,选择最佳模型
val ranks = List(8, 22)//隐语义因子
val lambdas = List(0.1, 10.0)//正则化参数
val iters = List(5, 7)//迭代次数
var bestModel: MatrixFactorizationModel = null
var bestValidateRnse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestIter = -1
//一个三层嵌套循环,会产生8个ranks ,lambdas ,iters 的组合,每个组合都会产生一个模型,计算8个模型的方差,最小的那个记为最佳模型
for (rank <- ranks; lam <- lambdas; iter <- iters) {
val model = ALS.train(traningData_Rating, rank, iter, lam)
//rnse为计算方差的函数,定义在最下方
val validateRnse = rnse(model, traningData_Rating, traningData_Rating.count())
println("validation = " + validateRnse
+ " for the model trained with rank = " + rank
+ " lambda = " + lam
+ " and numIter" + iter)
if (validateRnse < bestValidateRnse) {
bestModel = model
bestValidateRnse = validateRnse
bestRank = rank
bestLambda = lam
bestIter = iter
}
}
//val bestModel = ALS.train(traningData_Rating, 22, 7, 0.1)
//将最佳模型运用在测试数据集上
val testDataRnse = rnse(bestModel, traningData_Rating, traningData_Rating.count())
println("最好的测试模型是在rank=" + bestRank + " and lambda = " + bestLambda
+ " and numIter = " + bestIter + " 得到测试集数据的方差=" + testDataRnse)
//电影数据(1,Toy Story (1995),Animation|Children's|Comedy)格式, (args(1) + "/movies.dat")
val movieList_Tuple = sc.textFile("file:///home/hadoop/下载/movies.dat").map { lines =>
val fields = lines.split("::")
(fields(0).toInt, fields(1), fields(2))
}
//Map类型,键为id,值为name
val movies_Map = movieList_Tuple.map(x =>
(x._1, x._2)).collect().toMap
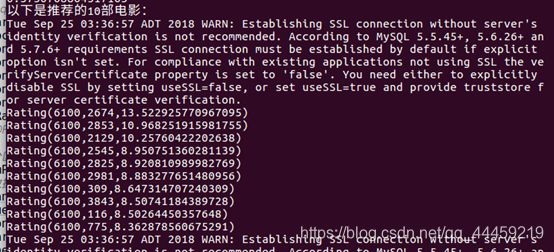
println("以下是推荐的10部电影:")
//得到我已经看过的电影的id
val myRatedMovieIds = myRatedData_Rating.map(_.product).collect().toSet
//从电影列表中将这些电影过滤掉,剩下的电影列表将被送到模型中预测每部电影我可能做出的评分
val recommondList = sc.parallelize(movies_Map.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
//将结果数据按评分从大小小排序,选出评分最高的10条记录输出
val recommondRdd = bestModel.predict(recommondList.map((userid, _)))
.collect()
.sortBy(-_.rating)
.take(10)
recommondRdd.foreach {
println
}
//下面加载recommondRdd生成Rdd文件,记录
val resultRdd = spark.sparkContext.parallelize(recommondRdd)
//生成字段,schema为表头
val schema = StructType(List(
StructField("userid", IntegerType, false),
StructField("movieid", IntegerType, false),
StructField("tating",FloatType , false)))
//对resultRdd每一行元素进行解析
val rowRDD = resultRdd.map(p => Row(p.user.toInt, p.product.toInt, p.rating.toFloat))
//将表头和表中数据结合起来
val resultDF = spark.createDataFrame(rowRDD,schema)
//创建prop变量保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "123")
prop.put("driver","com.mysql.jdbc.Driver")
//删除原有数据
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/personrating","root","123")
val statement = connection.createStatement()
statement.executeUpdate("delete from recommend where userid="+userid)
//写入推荐数据,采用append模式,表示追加数据到recommond表中
resultDF.write.mode("append").
jdbc("jdbc:mysql://localhost:3306/personrating?useSSL=false", "personrating.recommend", prop)
}
//计算方差函数
def rnse(model: MatrixFactorizationModel, predictionData: RDD[Rating], n: Long): Double = {
//根据参数model,来对验证数据集进行预测
val prediction = model.predict(predictionData.map(x => (x.user, x.product)))
//将预测结果和验证数据集join之后计算评分的方差并返回
val predictionAndOldRatings = prediction.map(x => ((x.user, x.product), x.rating))
.join(predictionData.map(x => ((x.user, x.product), x.rating))).values
math.sqrt(predictionAndOldRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ - _) / n)
}
}
项目运行截图:
主页:
注册页:
登录页:
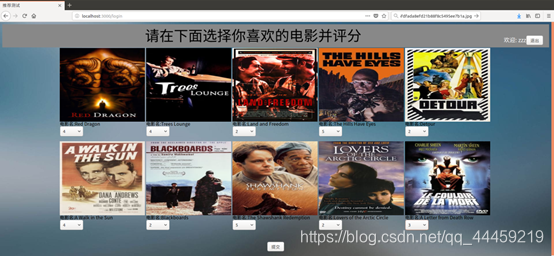
打分页:
推荐页:
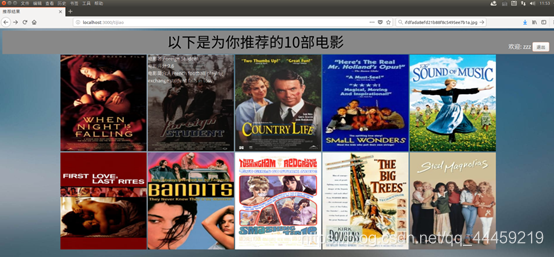
获取最佳模型结果图:
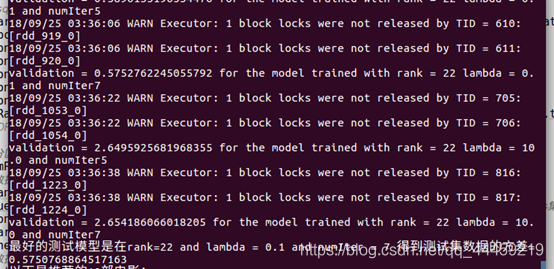
推荐结果图:
总结
1.Node
在使用node构建项目的时候出现错误“SyntaxError: Block-scoped declarations (let, const, function, class) not yet supported outside strict mode”: SyntaxError:在严格模式外尚不支持块作用域声明(let、const、function、class)。
报错原因是node版本太低造成的,因为开始我是使用Ubuntu直接下载node的,没有指定版本,所以把原来下载好的node全部删除干净,重新下载。
删除:
#apt-get 卸载
sudo apt-get remove --purge npm
sudo apt-get remove --purge nodejs
sudo apt-get remove --purge nodejs-legacy
sudo apt-get autoremove
#下载:
sudo wget https://nodejs.org/download/release/v12.18.3/node-v12.18.3-linux-x64.tar.gz
#解压
sudo tar -zxvf node-v12.18.3-linux-x64.tar.gz
#移动到自己的环境目录
sudo mv node-v12.18.3-linux-x64 /usr/local
#创建连接
sudo ln -s /usr/local/node-v12.18.3-linux-x64/bin/node /usr/local/bin/node > sudo ln -s /usr/local/node-v12.18.3-linux-x64/bin/npm /usr/local/bin/npm
查看版本信息
node -v
npm-v
再次使用node构建服务器就没问题了。
以前也很少使用过node作为构建工具,这次的项目让我好好学习了Node的相关命令和使用场景。就说Js吧,JavaScript 是一门被创建于 Netscape(作为用于在其浏览器 Netscape Navigator 中操纵网页的脚本工具)中的编程语言。Netscape 的商业模式的其中一部分是出售 Web 服务器,其中包括一个被称为 Netscape LiveWire 的环境,该环境可以使用服务器端 JavaScript 创建动态页面。
随着许多浏览器竞相为用户提供最佳的性能,JavaScript 引擎也变得更好。 主流浏览器背后的开发团队都在努力为 JavaScript 提供更好的支持,并找出使 JavaScript 运行更快的方法。 多亏这场竞争,Node.js 使用的 V8 引擎(也称为 Chrome V8,是 Chromium 项目开源的 JavaScript 引擎)获得了显着的改进。Node.js 恰巧构建于正确的地点和时间,但是运气并不是其今天流行的唯一原因。它为 JavaScript 服务器端开发引入了许多创新思维和方法,这已经对许多开发者带来了帮助。
2.项目结语
本项目通过构建电影推荐系统,将其作为辅助信息,构建了基于ALS协同过滤算法的推荐模型,并将其应用到电影推荐系统。采用预测用户满意度评分的方法优化了推荐性能,通过评分结果来判定用户对电影的喜好程度,并将合适的电影类型推荐给用户。随着影视行业的飞速发展,每年的电影数量都在剧增,这对视频推荐提出了更高的要求,而本系统具有个性化的推荐功能以及一定的商业价值。

















 7691
7691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









