






Abstract 超链接环境的网络结构可以是关于环境内容的丰富信息来源,只要我们有有效的手段来理解它。我们开发了一组算法工具,用于从这些环境的链接结构中提取信息,并报告了在各种上下文中证明它们在万维网上的有效性实验。我们在框架内讨论的中心问题是通过发现关于这些主题的“权威”信息来源来提炼广泛的搜索主题。我们提出并测试了权威概念的算法公式,基于一组相关的权威页面和一组将它们连接在一起的“集线器页面”之间的关系链接结构。我们的公式与与链接图相关的某些矩阵的特征向量有联系;这些联系反过来激励基于链接的分析的额外启发式。
1.Introduction
超链接环境的网络结构可以是关于环境内容的丰富信息来源,只要我们有有效的手段来理解它。在本工作中,我们开发了一组算法工具,用于从这些环境的链接结构中提取信息,并报告了在万维网中各种情况下证明其有效性的实验。特别是,我们专注于使用链接来分析与广泛搜索主题相关的页面集合,并发现关于这些主题的最“权威”页面。
虽然我们的技术不是特定于www,但我们发现搜索和结构分析的问题在这一领域特别令人信服。www是一个非常复杂的超文本语料库,它继续以惊人的速度扩展。此外,它可以被看作是一种复杂的民粹主义超媒体形式,在这种形式中,数以百万计的在线参与者,有着不同的和往往相互冲突的目标,正在不断地创建超链连接。因此,虽然个人可以在极端的地方一级强加秩序,但其全球组织是完全没有计划的-高层结构只能通过后验分析才能出现。
我们的工作起源于在www上搜索的问题,我们可以粗略地定义为发现与给定查询相关的页面的过程。搜索方法的质量必然需要人的评价,因为相关性等概念固有的主观性。我们从观察到,提高www上的搜索方法的质量,目前是一个丰富和有趣的问题,在许多方面是与关注算法的效率与存储正交。特别是,考虑到当前的搜索引擎通常索引www的相当大的一部分,并按秒的顺序响应。
虽然在响应时间较长的搜索工具中会有相当大的效用,但只要结果对用户的价值显著提高,通常就很难做到说出这样一个搜索工具应该用这个额外的时间来计算什么。显然,我们缺乏既具体界定又符合人类对质量观念的客观方法。
1.1查询和权威来源。我们将搜索视为从用户提供的查询开始。似乎最好不要对查询的概念采取过于统一的观点.有多种类型的查询,每个查询的处理可能需要不同的技术。例如,考虑以下类型的查询:
——具体问题。 例如,“Netscape支持JDK1.1编码API吗?”
——广泛的主题查询。 例如,“查找有关Java编程语言的信息。”
——类似页面查询。 例如,“找到与java.sun.com相似的页面。”
现在我们只关注前两种类型的查询,我们看到它们呈现出非常不同的障碍。处理特定查询的困难大致围绕着所谓的稀缺问题:包含所需信息的页面很少,而且常常是不同的确定这些页面的标识。
另一方面,对于主题广泛的查询,人们期望在www上找到数千个相关页面;这样的一组页面可能是由术语匹配的变体生成的。根本问题在于富余问题:可以合理地返回相关页面的数量太大,人类用户无法消化。为了在这些条件下提供有效的搜索方法,人们需要一种方法,从大量相关页面中筛选出一小部分最“权威”或“权威”的页面。
相对于广泛的主题查询,这种权威概念是我们工作的中心焦点。在解决这个问题时,我们面临的一个基本障碍是在特定查询主题的上下文中准确地建模权威。给定一个特定的页面,我们如何判断它是否权威?
讨论这里出现的一些并发症是有用的。首先,考虑报告www.harvard.edu,哈佛大学的主页,作为查询“哈佛”最权威的页面之一”的自然目标。不幸的是,在www上有超过一百万页使用“哈佛”这个词,而www.harvard.edu不是最经常或最突出地使用这个词的网页,或是以任何其他方式,使其在一个基于文本的排序函数下处于有利位置。相反有人怀疑,没有任何页面内生性措施可以允许其准确评估页面权威。其次,考虑查找主www搜索引擎首页的问题。一个人可以从查询“搜索引擎”开始,但事实上有一个直接的困难:许多权威并没有在他们的页面上使用这个词。这是一个根本性和反复出现的现象——另一个例子是,没有理由期望本田或丰田的主页包含“汽车制造商”一词。”
1.2. 链路结构分析。
分析www页面之间的超链接结构,为我们解决上述许多困难提供了一种方法。超链接编码大量潜在的人类判断,我们声称这种类型的判断正是制定权威概念所需要的。具体来说,在www上创建链接代表了以下类型判断的具体指示:p页的创建者,通过包含到q页的链接,在某种程度上已经授予关于q的权威。此外,链接使我们有机会纯粹通过指向它们的网页找到潜在的权威;这提供了一种方法来规避上述问题,即许多表现突出的页面缺乏自我描述。
当然,在为此目的应用链接时存在一些潜在的陷阱。首先,建立联系的原因多种多样,其中许多与授予权力无关。例如,大量链接主要是为了导航目的而创建的(“单击此处返回主菜单”);其他链接代表付费广告。
另一个问题是很难在相关性和受欢迎程度的标准之间找到适当的平衡,这两个标准都有助于我们直观的权威概念。考虑以下简单启发式定位权威页面所固有的严重问题具有指导意义:在包含查询字符串的所有页面中,返回那些具有最多的链接的页面。我们已经提出了很多疑问(“搜索引擎”,“汽车制造商”,…),一些最权威的页面不包含关联的查询字符串。相反,这种启发会考虑一个普遍流行的页面( 比如 www.yahoo.com 或者 www.netscape.com )对于它所包含的任何查询字符串要具有高度的权威性。
在这项工作中,我们提出了一个基于链接的授权模型,并展示了它如何导致一种方法,一致地识别相关的,权威的www页面的广泛搜索主题。 我们的模型基于一个主题的权威与链接到许多相关权威的页面之间存在的关系-我们将后一种类型的页面称为中心。 我们观察在由链路结构定义的图中,中心和权威之间存在某种自然类型的平衡,我们利用这一点开发了一种同时定义两种类别的方法。该算法对基于文本的www搜索引擎的输出构造的www的聚焦子图进行操作;我们构造这种子图的技术是为了产生小的可能包含给定主题最权威页面的页面集合。
1.3. 概览。 我们发现权威的www来源的方法是具有全球性的:我们希望在wwwas的背景下为广泛的搜索主题确定最核心的页面一个整体。 全局方法涉及表示和过滤大量信息的基本问题,因为与广泛主题查询相关的整个页面集合可以在milli中具有大小国家统计局。 这与试图了解属于单一逻辑网站或内联网的一组www页面之间的相互联系的本地方法形成了鲜明对比;在这种情况下,数据量是要小得多,而且往往是一组不同的考虑因素占主导地位。
同样重要的是要注意到,我们的主要关切与集群问题有根本的不同。集群处理的问题是将一个不同的群体分解成以某种方式更具凝聚力的亚群体;在www的背景下,这可能涉及到区分页面关系查询术语的不同含义或意义。因此,聚类本质上不同于通过发现权威来提取广泛主题的问题,尽管随后的一节将指出一些联系。因为即使我们能够完美地剖析一个模棱两可的查询术语(例如,“Windows”或“Gates”)的多种感官,我们仍然会面临相同的基本问题,即表示和表示过滤与查询项的每个主要感官相关的大量页面。
论文组织如下。 第二节讨论了我们根据一个广泛的搜索主题构造一个聚焦的www子图的方法,产生了一组富含c的相关页面任命当局。 第3节和第4节讨论了我们在这样一个子图中识别集线器和权限的主要算法,以及该算法的一些应用。 第五节讨论了Conne在www搜索、文献计量学和社交网络研究等领域从事相关工作。 第6节描述了我们的基本算法的扩展如何产生多个集线器集合以及共同链接结构中的权威。 最后,第7节调查了一个主题必须如何“广泛”才能有效,第8节调查了一些工作这是在这里提出的方法的评估上做的。
- 构建WWW的聚焦子图
将任意页面的集合看作图G=<V,E>,V代表页面集,E表页面间只想,(a,b)代表page(a)存在指向page(b)的超链接。从图G中,我们可以通过以下方式隔离小区域或子图。如果W属于V是页面的子集,我们用G[W]表示在W上诱导的图:它的节点是W中的页面,它的边对应于W中页之间的所有链接,它的节点是W中的页面,它的边缘对应于W中页之间的所有链接。
假设我们得到了一个由查询字符串s指定的宽主题查询。我们希望通过对链接结构的分析来确定权威页面;但是首先我们必须确定我们的算法将在www上操作的子图。我们在这里的目标是将计算工作集中在相关的页面上。因此,例如,我们可以将分析限制在包含查询字符串的所有页面的集合Q;但这有两个显著的缺点。首先,这一套可能包含100多万页,因此需要相当大的计算成本;其次,我们已经注意到,一些或大多数最好的权威可能不属于去这套。理想情况下,我们希望关注具有以下属性的页面集合S。
(1)S足够小
(2)S是由丰富的相关页面
(3)S包含大多数(或许多)最强大的权威。
通过保持S足够小,我们能够负担应用非线性算法的计算成本;通过确保它有丰富的相关页面,我们更容易找到好的权威,因为这些很可能在S中被大量引用。
我们怎么能找到这样一个页面集合?对于参数t(通常设置为200左右),我们首先从基于文本的搜索引擎(中收集查询s的t最高排名页面。我们将把这些t页称为根集R。这个根集满足上面列出的desiderata的(1))和(2),但通常远远不能满足(3)。同样有趣的是,Rs中的页面之间的链接往往非常少,使其基本上“无结构。”
我们可以使用根基R来产生需要的集合S。考虑查询主题的强大权威-尽管它可能不在集合R中,但它很可能至少被Rs中一页指向。沿着进入和离开Rs的便进行扩展。
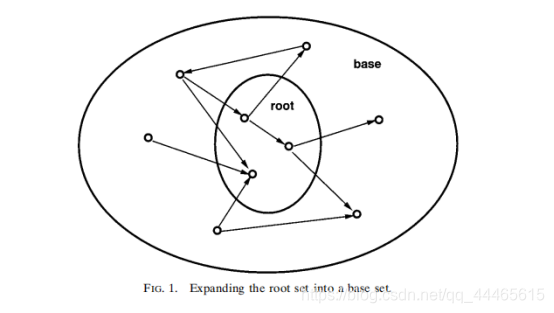
算法如下:

我们讨论在S中的两种不同链接(启发式),以单纯的导航链接影响抵消。我们说,链接是横向的,如果它是在不同域名的页面之间,而内在的,如果它是在相同域名的页面之间。这里的“域名”是指与页面关联的URL字符串中的第一级。由于内在链接的存在往往纯粹是为了允许导航站点的基础设施,因此它们传递的信息比横向链接要少得多,而横向链接是关于它们所指向的页面的权限的到。因此,我们从图G[S]中删除所有内在链接o只保 留与横向链接对应的边;这将导致图Go.
这是一个非常简单的启发式,但我们发现它有效地避免了许多病理造成的处理 导航链接的方式与其他链接。 还有其他一些简单的启发式方法,对于消除似乎没 有直觉赋予权威的链接是有价值的。 值得提及的是基于以下观察:假设来自单个 域的大量页面都指向单个页面p,这通常对应于引用页面之间的大量背书、广告或 其他类型的“串通”-例如,短语“由…设计的站点”和给定域中每个页面底部 的相应链接。 . . 为了消除这种现象,我们可以修复参数m(通常是m»4-8),并且 只允许从单个域中最多m页面指向任何给定的页p,这在某些情况下是一种有效的 启发式方法,尽管我们在运行下面的实验时没有使用它。
2.计算中心和权威
我们早些时候拒绝了这个想法,当时它被应用 于包含查询项o的所有页面的集合;但是现在我们已经显式地构建了一个包含我们 想要找到的大多数权限的相关页面的小集合。 因此,这些当局都是 属于Go 并且被G中的页面大量引用o.
事实上,纯粹按程度排序的方法通常在G的上下文中效果要好得多o 在某些情况 下, 它 可以 生产 统一的 高质量的 结果。 但是, 的 方法 仍然存在一些重大 问题。 例如,在查询“java”上 www.gamelan.com 学位最大的页面包括和 java.sun.com,以及加勒比度假广告页面和主页的亚马逊图书。 这种混合代表了 这种简单的排序方案所产生的问题类型:虽然前两页肯定应该被视为“好”答 案,但其他页面与查询主题无关;它们的程度很大,但缺乏任何主题统一。 这暴露出的基本困难是子图G中存在的内在张力,它存在于强大的权威和简单的“普遍流行”的页面之间我们希望。后一种类型的页面具有较大的程度,而不管底层查询主题如何。
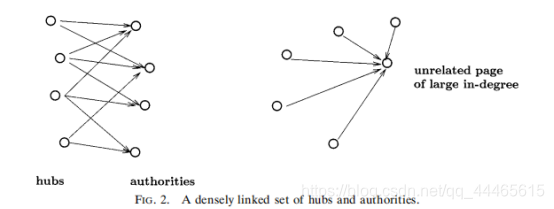
人们可能会想,要解决这些问题,是否需要进一步利用基集中页面的文本内容, 而不仅仅是G的链接结构o。 我们现在表明情况并非如此——事实上,从链接中更 有效地提取信息是可能的——我们从下面的观察开始。 与初始查询相关的权威页 面不仅应该有很大的程度;由于它们都是关于一个共同主题的权威,因此指向它们 的页面集合也应该有相当大的重叠。 因此,除了高度权威的页面外,我们还希望 找到可以称为中心页面的页面:这些是链接到多个相关权威页面的页面。正是这些中心页面在一个共同的主题上“汇集”了权威,并允许我们抛出不相关的大型程度页面。(图2中描述了一个骨架示例;当然,在现实中,图片并不那么干净。 )
中心和权威展示了可以被称为相辅相成的关系。一个好的中心是一个指向许多好的权威的页面;一个好的权威是一个由许多好的中心指向的页面。 显然,如果我们希望在子图G中识别权威和威我们需要一种打破这种循环的方法。
3.1. 一种迭代算法。 我们利用集线器和权限之间的关系,通过迭代算法来维护和更新每个页面的数字权重。如果p指向许多具有大x值的页面,那么它应该接收一个大的y值;如果p被许多具有大y值的页面指向,那么它应该接收一个大的x值。x为非负权威权重,y为非负中心权重。
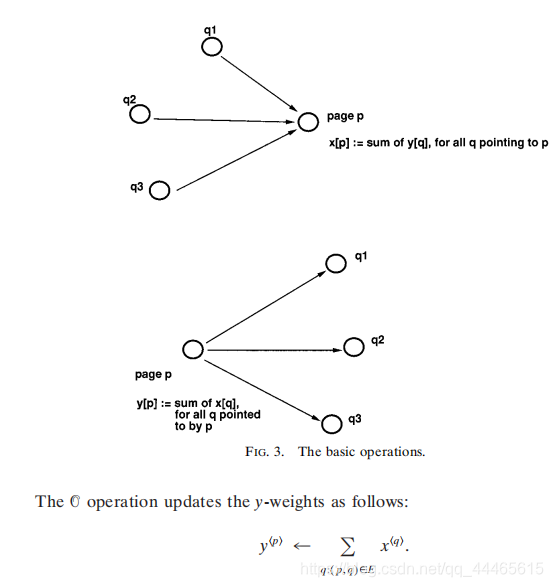
定理3.1。 序列x1,x2,x3,…和y1,y2,y3,…收敛(分别限制x和y)。 xi,yi分别为第i次迭代中x和y的值。


上一节中提出的算法可以应用于另一种类型的问题-使用链接结构来推断页面之间的“相似性”概念。 假设我们找到了一页帽子是有兴趣的-也许它是一个关于感兴趣的主题的权威页面-我们想问以下类型的问题:当www的用户创建时,他们认为有关,当他们创建页面和超链接?
如果p是高度引用的页面,我们有一个版本的富余问题:周围的链接结构将隐式地表示大量关于p与其他页面关系的独立意见。 利用我们的中心和权威概念,我们可以提供一个处理页面相似性问题,问:在p附近链接结构的局部区域,什么是最强的权限? 这类主管部门可以作为一个广泛的专题摘要与p相关的页面。
之前的方法基本适用,只是存在一些排序上的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









