









目录
第一章 系统描述 3
§1.1系统概述 3
§1.2系统的物理组成 4
第二章 需求分析模型 4
§2.1 E-R图 4
§2.2 数据流图 5
§2.3 状态转换图 6
第三章 软件模块结构图 6
第四章 面向对象的视图 7
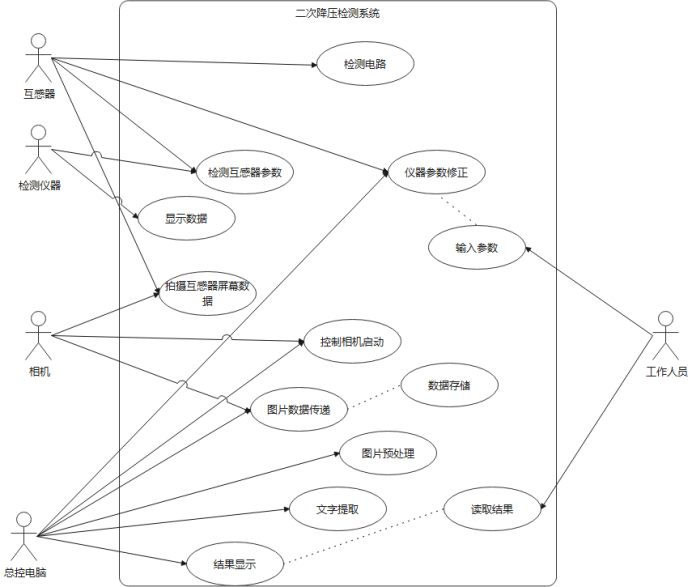
§4.1 用例图 7
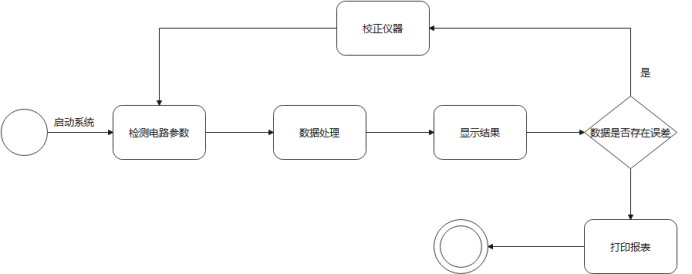
§4.2 活动图 8
五、关键技术及实现 9
§5.1 图像预处理 9
§5.1.1 开发工具 9
§5.1.2 流程设计 9
§5.1.3 主要模块详细设计 10
§5.1.4 效果展示 11
§5.2 文字识别 13
§5.2.1 开发工具 13
§5.2.2 Paddleocr介绍 14
§5.2.3 流程设计 14
§5.2.4 关键代码展示 15
§5.2.5 效果展示 16
第一章 系统描述
§1.1系统概述
在发电厂和变电站电能计量回路中,由于电压过大,产生的强电场会给电表带来较大影响,且难以读出,故电压互感器离装设于控制室配电盘上的电能表有较远的距离。整个回路有接线端子排、开关、熔断器及导线,必然存在着接触电阻、导线电阻及分布参数,从而就存在着一定的回路阻抗,造成电压互感器与电能表间的二次回路上有电压降。该系统针对的测试对象是用电压互感器二次回路导线所引起的电压降。试验目的是检验用于电能计量中电压互感器二次回路压降的误差。而电能计量综合误差的计算与修正,需要准确地检测出电压互感器二次回路压降的误差。
采用计算机进行数据读取和处理过程可有效保护工作人员生命安全,并减小读取误差。
§1.2系统的物理组成
检测仪器——二次压降检测仪器
被检测仪器——被检测的互感器
自动获取数据的相机
进行数据处理的电脑
电源充电器、RS232通讯线、USB通讯线、电压测试线等
第二章 需求分析模型
§2.1 E-R图
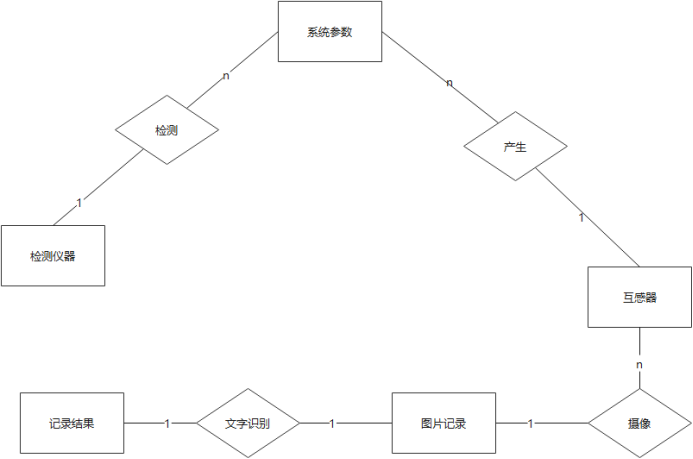
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
本系统的E-R图如下所示。
§2.2 数据流图
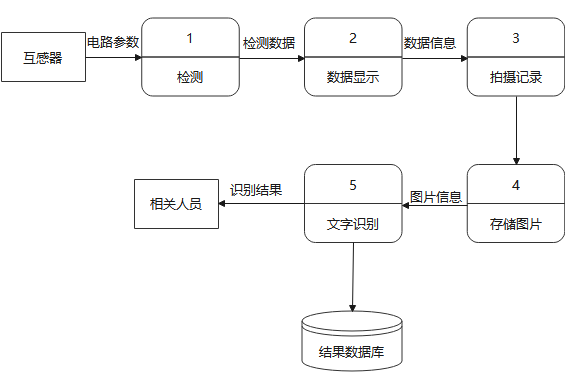
下图为整个系统的数据流图,包含了系统数据的流动方向。
§2.3 状态转换图
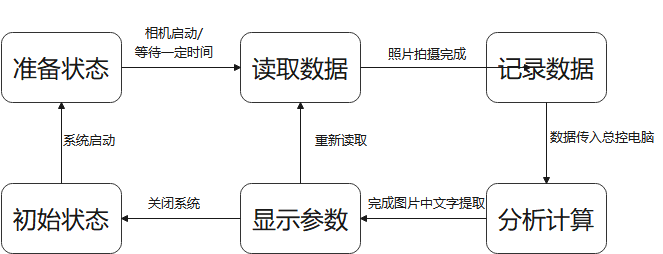
本系统状态变化如下。
第三章 软件模块结构图
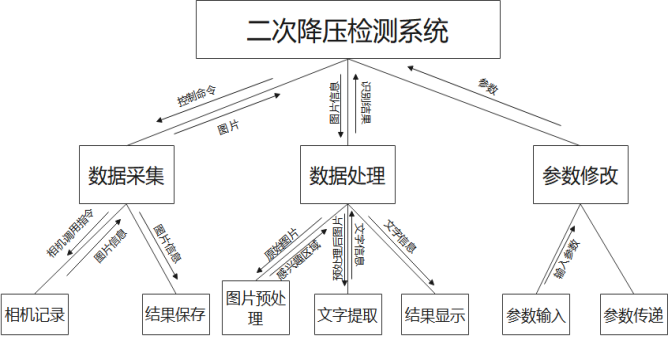
本系统主要分为数据采集,结果分析和参数修改三大模块,具体模块图如下所示。
第四章面向对象的视图
§4.1 用例图
§4.2 活动图
在确定系统用例后,对系统活动顺序进行建模如下。
五、关键技术及实现
§5.1 图像预处理
在本系统的拍摄图像过程中,难免会出现类似于图像角度偏转,周边存在误差等环境因素影响图片文字识别效果,故在此预处理过程中,对图像中感兴趣区域(即检测仪器屏幕区域)提取,并进行旋转和透视变化,使之呈现为矩形大小。同时,为了减少屏幕亮度影响,增强图片中文字与背景对比度,在本模块对图片进行二值化。
§5.1.1 开发工具
本部分采用python3.6和opencv进行开发。
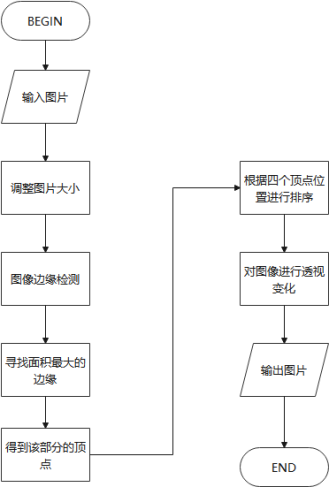
§5.1.2 流程设计
本模块的具体实现流程如下图所示:
§5.1.3 主要模块详细设计
1、图像边缘检测
在该部分的具体过程如下伪代码所示。
#进行高斯模糊,减少噪声
binary = GaussianBlur(image, (3, 3), 2, 2)
#对图片进行边缘检测
binary =Canny(binary, 60, 240, apertureSize=3)
#进行膨胀操作,尽量使边缘闭合
binary = dilate(binary, kernel, iterations=1)
2、寻找最大边缘
在该部分的具体过程如下伪代码所示。
Counters=findContours(Image)
max_area=0
max_contour = []
for contour in contours:
currentArea = cv2.contourArea(contour)
if currentArea > max_area:
max_area = currentArea
max_contour = contour
3、透视变化
在该部分的具体过程如下伪代码所示。
w, h = pointDistance(box[0], box[1]), \
pointDistance(box[1], box[2])
dst_rect = np.array([[0, 0],
[w - 1, 0],
[w - 1, h - 1],
[0, h - 1]], dtype='float32')
M = cv2.getPerspectiveTransform(box, dst_rect)
warped = cv2.warpPerspective(image, M, (w, h))
§5.1.4 效果展示
首先我们给出用例图片,如下图所示,很明显我们可以看到,该图片中屏幕部分存在一定倾斜,且中间存在亮点,并且四周存在许多干扰元素。
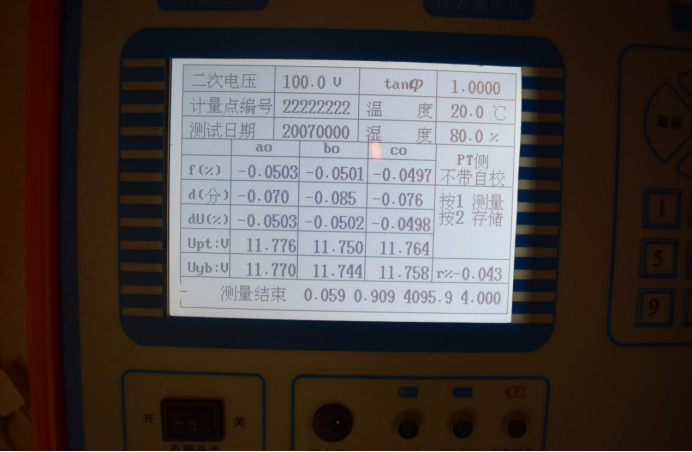
接着,我们展示对其进行边缘提取后的图片,如下图所示,我们可以发现在提取过程中,将文字等的边缘一并进行提取,所以需要通过提取最大边缘来解决该问题。
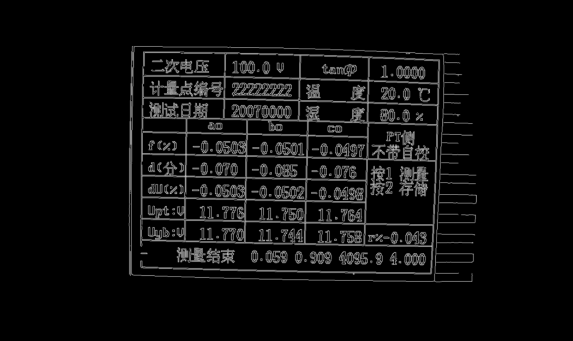
然后,显示我们完成透视映射后的图片,如下图所示,可以发现整个屏幕已经基本上被纠正成一个矩阵,但是,图片中间依然存在一个亮斑,为了去除亮斑,我们将该图片进行二值化。
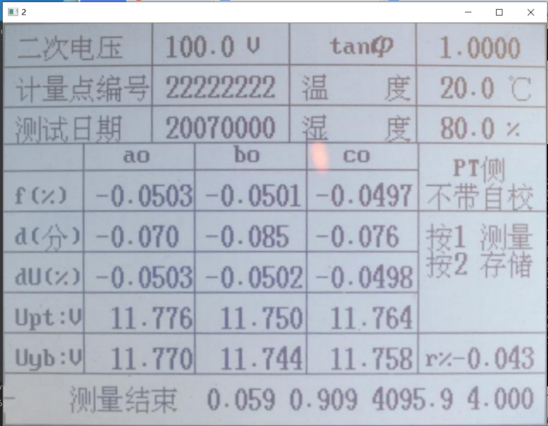
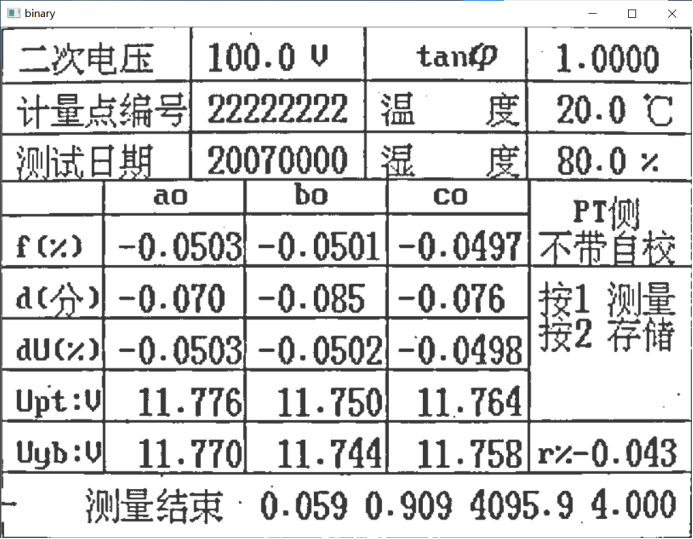
二值化后的图片如下,至此,整个图片预处理的过程结束。可以发现该图片中文字与背景对比已经非常明显,且不存在其他环境因素影响识别。
§5.2 文字识别
在本系统中,主控电脑需要对拍摄到的图片中参数信息进行处理,然而,计算机无法单纯的对图片中的信息进行处理。而将RGB图片中的文字进行识别并输出为文本格式的过程,就是文本识别需要完成的任务。
§5.2.1 开发工具
选择使用python3.6,Paddleocr进行文字识别任务。
§5.2.2 Paddleocr介绍
PaddleOCR是一款专门进行图像中文字检测和识别的工具,目前支持目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换,参数依次为ch, en, french, german, korean, japan。
该工具攘括文本检测、识别、端到端识别三种方向,每个方向包含多种算法,可以达到甚至超越SOTA效果的算法性能。
§5.2.3 流程设计
该部分的流程设计如下

§5.2.4 关键代码展示
1、调用PaddleOCR
def detect_words(img,ocr):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(~gray, 200, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
size=binary.shape
one=np.ones((size[0],size[1]),dtype=np.uint8)*255
binary=one - binary
cv2.imshow('binary',binary)
cv2.waitKey()
result = ocr.ocr(binary, cls=True)
显示结果
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(img, boxes, txts,scores, font_path='/path/to/PaddleOCR/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
return boxes,txts,scores,im_show
2、输出至excel文档
def outexcel(boxes,txts,filename):
fp = [box[0][0] for box in boxes]
with open('test.csv', "w", newline='') as csv_file:
writer = csv.writer(csv_file, dialect='excel')
row = []
j = 0
for i in range(len(txts)):
if i == 0:
row.append(txts[i])
continue
if (boxes[i][0][1] - boxes[i - 1][0][1] > 10):
row = sort(fp, j, i, row)
writer.writerows([row])
print(row)
row.clear()
j = i
row.append(txts[i])
row = sort(fp, j, len(txts), row)
print(row)
writer.writerows([row])
§5.2.5 效果展示
该算法对图片进行分块识别,效果如下。
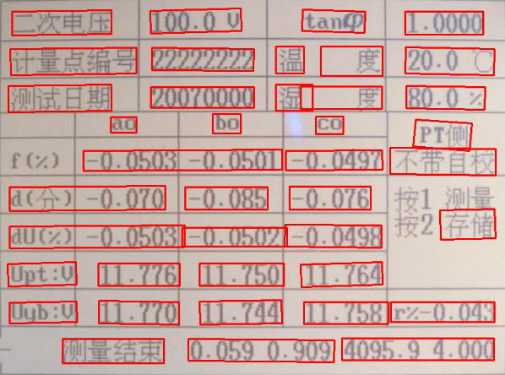
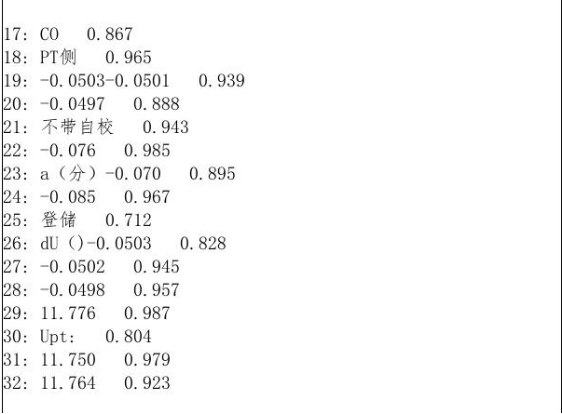
识别结果如下,左边为识别出的文字,右边为准确率。


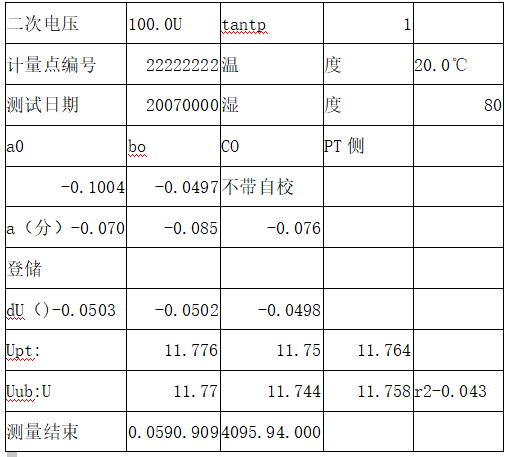
最后输出的excel表格如下所示,可以发现基本位置正确。















 2828
2828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









