







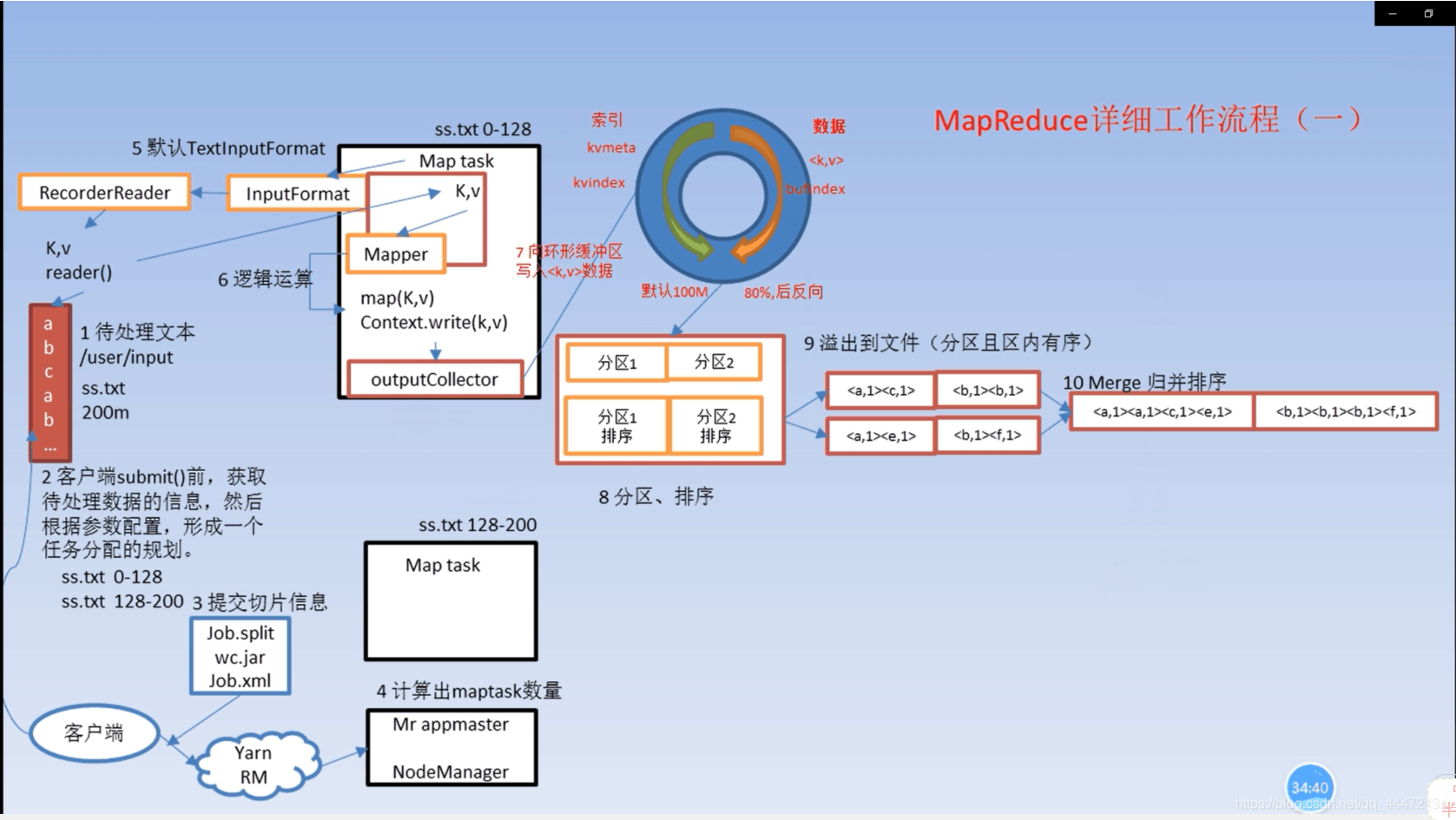
1、有多少个切片就会默认启动多少个maptask ,每个maptask会处理一个切片(split默认是 128M )
2、fileinputformat继承自inputformat,用inputformat里的read()流,以键值对的形式读取文档,键是行首偏移量,值是每一行数据
3、write并不是直接写到硬盘里面,而是用底层的outputCollector先写到环形缓冲区,环形缓冲区默认大小是 100M,溢写比是 80% mapred-site.xml文件中的io.sort.mb的配置项配置
4、内存环形缓冲区满了之后,他会往硬盘里面写,写之前首先进行分区,如下图所示:
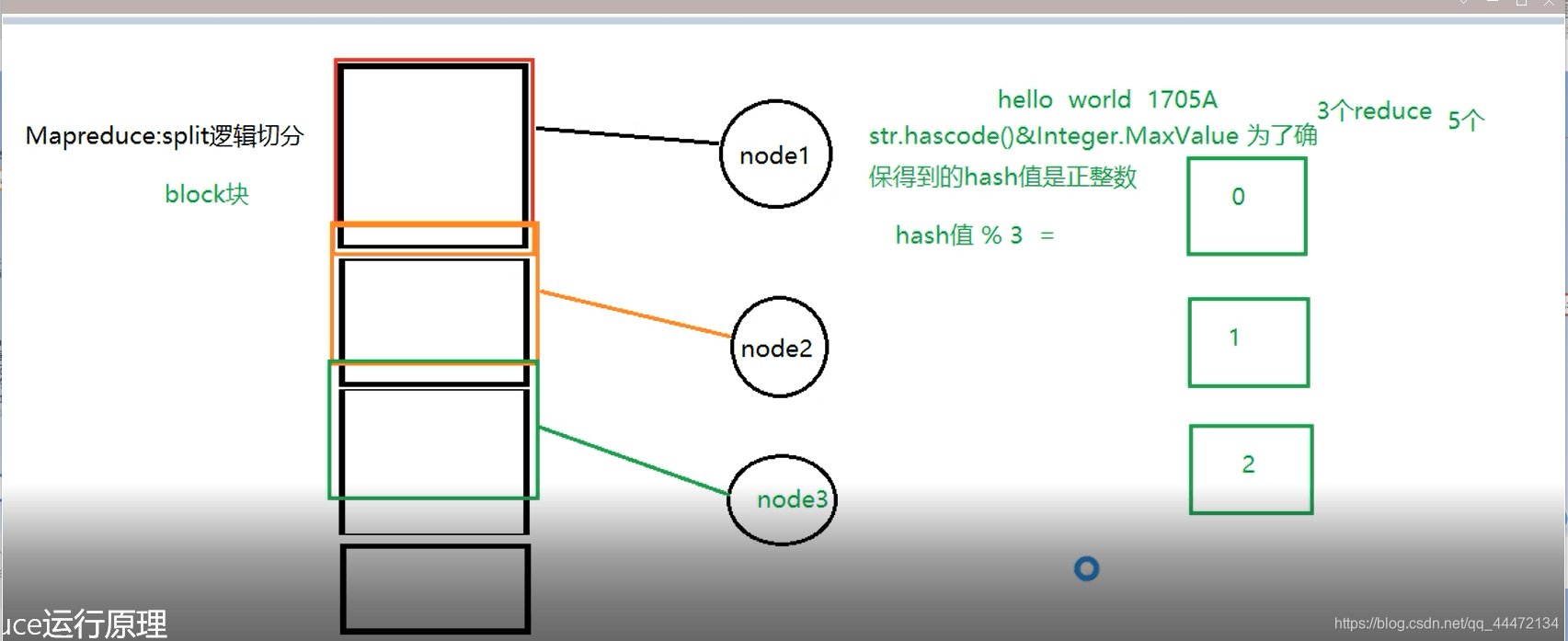
同一个分区的数据会落到同一个reducer端进行处理
5、归并排序
先两个两个进行排序
再四个四个进行排序
再八个八个进行排序
再把其他的和这8个进行排序
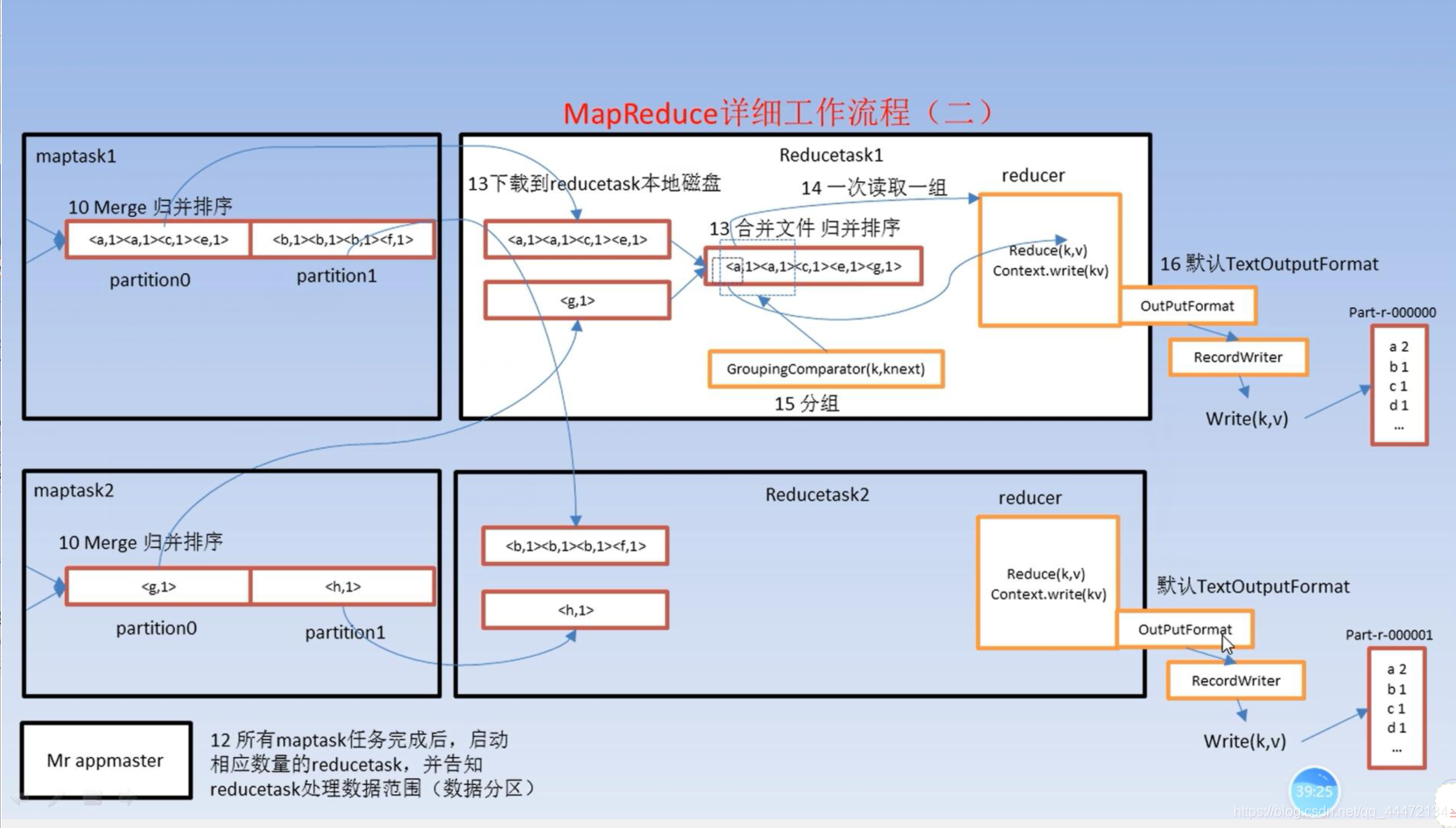
1、分区1的内容到reduceTask1中
分区2的内容到reduceTas2中
2、从各个maptask上远程拷贝一片数据,如果大小超过一定阀值,则写到磁盘上,否则放到内存中。














 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









