







KMP算法笔记
在计算机科学中,Knuth-Morris-Pratt字符串查找算法(简称为KMP算法)可在一个主文本字符串S内查找一个模式串P的出现位置。此算法通过运用对这个模式串在不匹配时本身就包含足够的信息来确定下一个匹配将在哪里开始的发现,从而避免重新检查先前匹配的字符。
一、问题描述给定一个主串 S 及一个模式串 P,判断模式串是否为主串的子串;
二、朴素算法
这个不多说,就是循环,出现不匹配,S 指针加 1,P 指针置为 1 接着循环判断。
三、KMP 算法(手算)
首先本文采用 j(序号)为 1 开始
故 next 数组没有下标为 0 的
next[J]为-1 开始,第二位为 0(这是初始的已知,所有的都是)
如果需要 Next[J]为 0 开始,在上面求的式子上每一项加 1 便可(从 0 开始在使用编程语言写更简单点,手算建议和本文保持一致)
1.首先需要了解"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为 0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为 0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度 0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为 0;
- “ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A”,长度为 1;
- “ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB”,长度为 2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为 0。
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | a | b | a | b | a | a | a | b | a | b | a | a |
| next[J] | ||||||||||||
| nextval[J] |
next 手算及理解过程(加粗和斜体标记了前后缀):
-
当 j=1 时,P 串为空串,即 a 前没有字符,所以规定 next[1]=-1;
-
当 j=2 时,P 串为"a", "a"的前缀和后缀都为空集,共有元素的长度为 0,所以 next[2]=0;
-
当 j=3 时,P 串为"ab", "ab"的前缀为[a],后缀为[b],共有元素的长度为 0;所以 next[3]=0
-
当 j=4 时,P 串为"aba", 共有元素的长度为 1,所以 next[4]=1
-
当 j=5 时,P 串为"abab", 共有元素的长度为 2,所以 next[5]=2
-
当 j=6 时,P 串为"ababa",前后缀"aba",共有元素的长度为 3,所以 next[6]=3
-
当 j=7 时,P 串为"ababaa", 共有元素的长度为 1,所以 next[7]=1
-
当 j=8 时,P 串为"ababaaa", 共有元素的长度为 1,所以 next[8]=1
-
当 j=9 时,P 串为"ababaaab", 共有元素的长度为 2,所以 next[9]=2
-
当 j=10 时,P 串为"ababaaaba", 共有元素的长度为 3,所以 next[10]=3
-
当 j=11 时,P 串为"ababaaabab", 共有元素的长度为 4,所以 next[11]=4
-
当 j=12 时,P 串为"ababaaababa", 共有元素的长度为 5,所以 next[12]=5
得到:
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | a | b | a | b | a | a | a | b | a | b | a | a |
| next[J] | -1 | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 |
| nextval[J] |
理解的就接着看 nextval
1.首先我们先要了解 next 数组用处是什么,
我们把上面的 next[j]改为 0 开始,每项加 1:
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | a | b | a | b | a | a | a | b | a | b | a | a |
| next[J] | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 2 | 3 | 4 | 5 | 6 |
| nextval[J] |
现在就可以说当第 j 位不匹配时,跳转至 next[j]位重新匹配(即 P 串右移)
nextval 手算及理解过程:
-
当 j=1 时,规定 nextval[1]=0;
-
当 j=2 时
因 next[2]=1,所以会跳转到第一位(next[j])重新匹配
在 P 串中有 P[2]!=P[1] (不等于!=)所以 nextval[2]=1,即 nextval[j]=next[j]
-
当 j=3 时,因 next[3]=1,所以会跳转到第一位(next[j])重新匹配
*
在 P 串中有 P[3]=P[1]=a,当 j=1 时,因为 P[3]=a 不匹配,P[1]=a,所以还是不匹配
所以还会跳转到 next[1]=0 位开始重新匹配
next[3]=1 就显得多次一举,故引入 nextval
所以 nextval[3]=0,即 nextval[j]=next[next[j]]
-
当 j=4 时,因 next[4]=2,所以会跳转到第二位(next[j])重新匹配
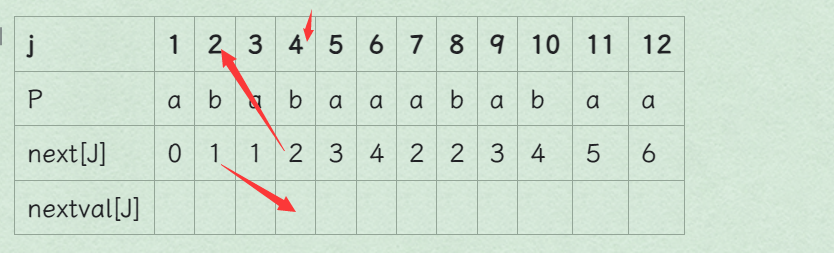
在 P 串中有 P[4]=P[2]=b,当 j=2 时,因为 P[4]=b 不匹配,P[2]=b,所以还是不匹配
所以还会跳转到 next[2]=1 位开始重新匹配
next[4]=2 就显得多次一举,故引入 nextval
所以 nextval[4]=1,即 nextval[j]=next[next[j]]
-
此时先说明结论:
当 j 所在位置,P[j]不等于 P(next[j])时,nextval[j]就等于 next[j]当 j 所在位置,P[j]等于 P(next[j])时,就必须往前找找到 j 所在位置(P[j])不等于 P(next[j])时,nextval[j]就等于 next[j];
例子:当 j=12,P[12]=P[next[12]]=a,
next[12]=6
j=6
P[6]!=P[next[6]]
所以 nextval[12]=next[6]
-
当 j=5 时,因 next[5]=3,所以会跳转到第三位(next[j])重新匹配
在 P 串中有 P[5]=P[3]=a,

当 j=3 时,因 next[3]=1,所以会跳转到第一位(next[j])重新匹配
在 P 串中有 P[3]=P[1]=a,当 j=1 时,因为 P[3]=a 不匹配,P[1]=a,所以还是不匹配
所以还会跳转到 next[1]=0 位开始重新匹配
所以 nextval[5]=0,即 nextval[j]=next[next[next[j]]]
-
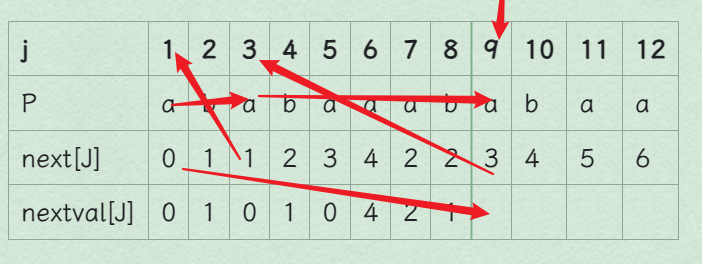
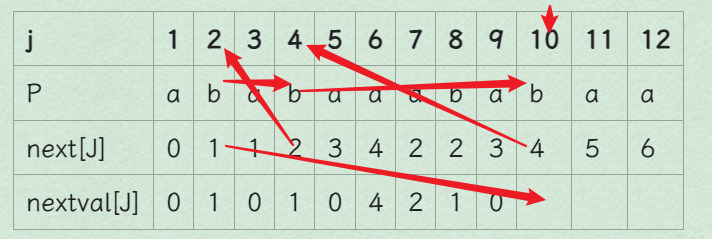
后面不写了太累放2张图,写了算法,更多题目自己跑程序验证
-
j 1 2 3 4 5 6 7 8 9 10 11 12 P a b a b a a a b a b a a next[J] 0 1 1 2 3 4 2 2 3 4 5 6 nextval[J] 0 1 0 1 0 4 2 1 0 1 0 4
代码
#include <stdio.h>
#include <string.h>
void compute_next(char* pattern, int* next) {
int len = strlen(pattern);
next[0] = -1;
int k = -1;
int j = 0;
while (j < len - 1) {
if (k == -1 || pattern[j] == pattern[k]) {
++k;
++j;
next[j] = k;
} else {
k = next[k];
}
}
}
void compute_nextval(char* pattern, int* next, int* nextval) {
int len = strlen(pattern);
for (int i = 0; i < len; ++i) {
nextval[i] = next[i];
}
for (int i = 1; i < len; ++i) {
if (pattern[i] == pattern[next[i]]) {
nextval[i] = nextval[next[i]];
}
}
}
void print_array(int* arr, int len) {
for (int i = 0; i < len; ++i) {
printf("%d ", arr[i]);
}
printf("\n");
}
void print_array_plus_one(int* arr, int len) {
for (int i = 0; i < len; ++i) {
printf("%d ", arr[i] + 1);
}
printf("\n");
}
int main() {
char pattern[] = "ababaaababaa";
int len = strlen(pattern);
int next[len], nextval[len];
compute_next(pattern, next);
compute_nextval(pattern, next, nextval);
printf("next array: ");
print_array(next, len);
printf("nextval array: ");
print_array(nextval, len);
printf("next array plus_one: ");
print_array_plus_one(next, len);
printf("nextval array plus_one: ");
print_array_plus_one(nextval, len);
return 0;
}
参考链接
网上 KMP 一大堆文章各异,有些还有错误,理解不便,所以自己写一篇笔记,首发本人博客 零星の小屋,转载,使用者可以对本创作进行转载、节选、混编、二次创作,但不得运用于商业目的,且使用时须进行署名,采用本创作的内容必须同样采用本协议进行授权

本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











