







在sql中有一类函数叫做`聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数。(开创函数,我们一般用于分组中求 TopN问题)
- OVER():用于指定分析函数工作时的数据窗口大小,这个数据窗口大小可能会随着行的变而变化;
OVER()函数之中:
- n PRECEDING:往前n行数据;
- CURRENT ROW:当前行;
- n FOLLOWING:往后n行数据;
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
OVER()函数之前:
- LAG(col,n,default_val):往前第n行数据;
- LEAD(col,n, default_val):往后第n行数据;
- NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。这个函数需要注意:n必须为int类型。
下面通过如下需求来解释:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94根据如上数据创建hive表:
hive (db_test)> create table if not exists over_table(
> name string,
> buydate string,
> cost int)
> row format delimited fields terminated by ','加载数据:
hive (db_test)> load data local inpath '/Datawarehouse/hive/hive-3.1.2/test-data/over_table.txt' into table over_table;
1. 查询在 2017 年 4 月份购买过的顾客及总人数
SELECT name from over_table
where substring(buydate,1,7)='2017-04'
group by name;
结果如下:

但是需求实际需要效果是,每行列名后面紧跟总人数:
上述是开窗之前,这里既要查询聚合前的人名,又要查询聚合后的总人数,新增加一列称之为开窗。
SELECT name,count(*) over() as count_num
from over_table
where substring(buydate,1,7)='2017-04'
group by name; 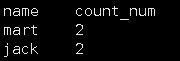
count_num列为开窗字段,该开窗范围是开窗之前整个行,当over()不加任何修饰时,默认开窗范围是开窗前整个行。
2.查询顾客的购买明细及月购买总额
先分解,查询顾客的购买明细SQL语句如下:
hive (db_test)> select name,buydate,cost from over_table where name='jack'
> union
> select name,buydate,cost from over_table where name='tony'
> union
> select name,buydate,cost from over_table where name='mart';

既要有明细,又要有每月总额,那么开窗范围应该按月进行分类,

hive (db_test)> select name,buydate,cost,
sum(cost) over(partition by month(buydate))
from over_table;
开窗后的新列中的每一行都对应一个开窗范围,上述图中,每个矩形框称为开窗范围,over(partition by month(buydate))根据月份,相同月份划分为一个窗口,再对窗口中的cost字段值求和,得到每个月的月购买总额。
3.将每个顾客的 cost 按照日期进行累加

select name,buydate,cost,
sum(cost) over(partition by name order by buydate rows between UNBOUNDED PRECEDING and current row) as sum_cost
from over_table;
over()中的partition by name使开窗根据人名分类,order by buydate使分类后的结果根据购买日期进行排序,rows between unbouned preceding and current row限制了开窗范围,每行的开窗范围为从起点到当前行,同理,rows between current row and unbouned following表示从当前行到终点。
over(partition by name order by buydate rows between UNBOUNDED PRECEDING and current row)可以简写为over(partition by name order by orderdate)。
4.查看顾客上次的购买时间
这个需求需要结合
- LAG(col,n,default_val):col字段往前第n行数据,如果没有则default替代;
- LEAD(col,n, default_val):col字段往后第n行数据,如果没有则default替代;
关键字使用over()。

每行开窗范围如下所示,按姓名分区日期排序后,开窗范围为起点到当前行,lag选择开窗范围中的buydate字段的前一个,即为上一次购买的日期。

select name,buy_date,cost,
lag(buydate,1,'null') over(partition by name order by buydate) as before_time
from over_table;5.查询前 20%时间的订单信息
select name,orderdate,cost,
ntile(5) over(order by orderdate) sort_num
from business

ntile(num)会将结果集分为num个部分,结果集中每一行都有一个编号,表示所属部分。如上查询集被分为5部分,因为行数限制,第五部分不足3行,所以属于第五部分的只有2行,那么查询前20%就等于取五份中的一份。
select * from(
select name,orderdate,cost,
ntile(5) over(order by orderdate) sort_num
from business) t1
where t1.sort_num=1















 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









