






mysql的索引可以大大提高mysql的检索速度。
索引好比字典上的目录,我们可以利用笔画,偏旁部首或者首字母查到自己想要找的字。
mysql的索引分为单列索引和复合索引。单列索引指的是表中的任何一列都可以当做索引。
复合索引指的是索引中包含很多列。
在centos6以后,mysql用的是引擎是innodb。innodb用的索引是聚簇索引
聚簇索引
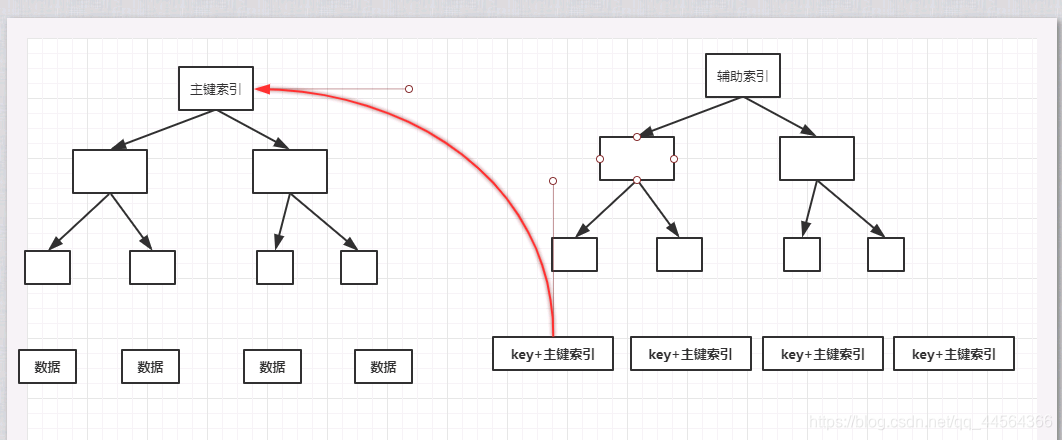
聚簇索引是说将主键组织到一颗B+树上,数据放在主键索引上的树叶节点上。例如你在使用id做主键索引,直接查找id=1的数据时。B+树直接通过主键索引来查找到相应的数据。
主键索引可以其实就是你在数据库中定义的PRIMARY KEY。一旦你定义了某个字段为PRIMARY KEY。无论你输入的顺序是什么,它都会按照一定的顺序进行排序。
因为主键索引直接连接着数据,所以你的PRIMARY KEY才是唯一的,不允许有重复。
辅助索引,就是你在主键之外的建立的索引。利用辅助索引查找想要的数据时,它会在辅助索引上找到数据所对应的主键索引。 然后在通过主键索引查到相应的数据。
所以辅助索引是不存储数据的,它是指向了主键索引。
非聚簇索引
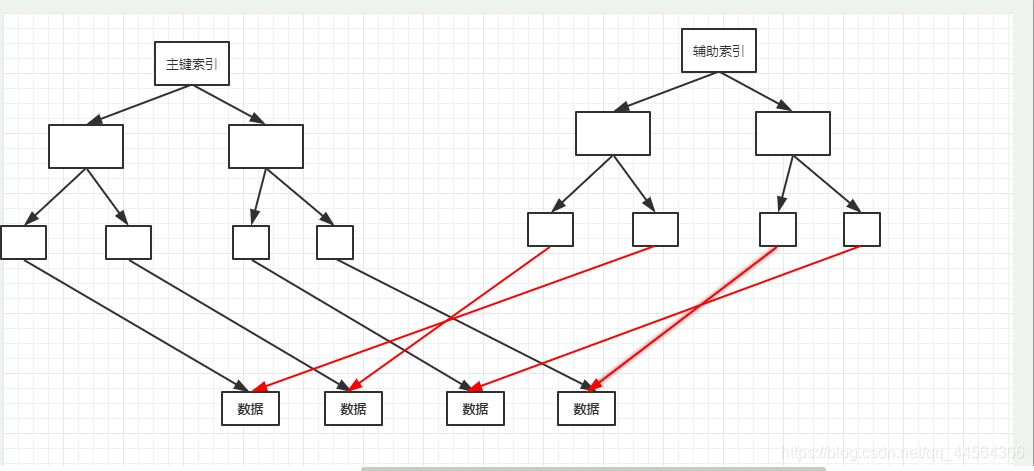
centos6用的myism引擎,它使用的是非聚簇索引。
非聚簇索引和聚簇索引类似,但是它的主键索引和辅助索引都是指向了数据。即主键索引和辅助索引通通不存储数据。都是指针指向。 需要注意的是,主键索引的数据时严格按照一一对应的。辅助索引则不是,它是不规则指向。
B+树

b+树的查找过程:如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分法查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据。(转载)
可以使用B-Tree树索引的查询类型:
- 全值匹配:精确所有索引项
- 匹配最左前缀:即只是用索引的第一列。复合索引只能匹配第一列,第二列索引不能用。
- 匹配列前缀:只匹配一列值开头部分,如:姓以w开头的
- 匹配范围值:如:姓ma和姓wang之间
- 精确匹配某一列并范围匹配另一列:如:姓wang,名以x开头的
B-Tree树索引的限制:
-
如果不是从最左列开始,则无法使用索引。例如,查找姓名xiaochun,或姓名为g结尾。
-
不能跳过索引中的列。
-
如果查询中某个列时范围查询,那么其右侧的列都无法在使用索引。如:姓wang,名x%,年龄30,只能利用姓和名上面的索引
-
建议:
-
索引列的顺序和查询语句的写法应相匹配,才能更好的利用索引
-
为优化性能,可能需要针对相同的列但顺序不同创建不同的索引来满足不同类型的查询需求。对于经常需要查询的,我们最好来建立索引来满足查询。
EXPLAIN
EXPLAIN SELECT clause
获取查询执行计划信息,用来查看查询优化器如何执行查询
示例:
MariaDB [hellodb]> EXPLAIN SELECT name FROM students WHERE stuid > 10\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: students
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 15
Extra: Using where
table:SELECT查询关联的表
/* type:关联类型或者访问类型,即mysql决定的如何去查询表中的行的方式。以下顺序,性能由高到低
ALL:全表扫描
index:根据索引的次序进行全表扫描,如果在extra列出现‘Using index’表示使用覆盖索引,而非全表索引。
range:有范围限制的根据索引实现范围扫描,扫描位置始于索引中的某一点,结束于另一点。
ref:根据索引返回表中匹配某个值得所有行
eq_ref:仅返回一个行,但于需要额外于某个参数值做比较
const,system:直接返回单个行
*/
possible_keys:查询可能会用到的索引
key:查询中使用的索引
key_len:在索引使用的字节数
ref:在利用key字段所表示的索引完成查询时所用列或某常量值
rows:mysql估计为找所有的目标行而需要读取的行数
extra:额外信息
Using index :mysql将会使用覆盖索引,以避免访问表
Using where :mysql服务器将在存储引擎检索后,再进行一次过滤
Using temporary:mysql对结果排序时会使用临时表
Using filesort:对结果使用一个外部索引排序
管理索引
1)创建索引
CREATE INDEX index_name ON tbl_name (index_col_name,…);
MariaDB [hellodb]> CREATE INDEX index_name ON students (name(5));
2)查看索引
SHOW INDEXES FROM [db_name.]tbl_name;
MariaDB [hellodb]> SHOW INDEX FROM students\G;
3)删除索引
DROP INDEX index_name ON tbl_name;
MariaDB [hellodb]> DROP INDEX index_name ON students;
4)查看索引统计的信息
MariaDB [hellodb]> SHOW INDEX_STATISTICS;
+--------------+--------------+------------+-----------+
| Table_schema | Table_name | Index_name | Rows_read |
+--------------+--------------+------------+-----------+
| hellodb | students | index_name | 10 |
| mysql | columns_priv | PRIMARY | 2 |
| hellodb | students | PRIMARY | 1 |
| mysql | tables_priv | PRIMARY | 1 |
+--------------+--------------+------------+-----------+
如果要使用统计信息,需要将userstat写入到配置文件中
[root@ansible ~]# cat /etc/my.cnf
[mysqld]
userstat=1














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









