






Dense Vision Transformer Compression with Few Samples
研究目的和相关工作
研究目标是在少样本情况下开发一种新颖而有效的框架,实现Vision Transformers (ViTs)和Convolutional Neural Networks (CNNs)的密集压缩。该方法旨在实现高精度和高密度的压缩。密度指的是在目标压缩范围内压缩多个模型的能力,而稀疏方法只能输出少量模型。避免浪费计算资源是非常重要的,因为稀疏方法可能导致未使用的计算能力和较低的精度,而无法充分利用计算预算。
现有的少样本CNN压缩方法(如PRACTISE)提供稀疏压缩选项,并在精度上取得了显著的改进。然而,它们只能通过丢弃不同数量的块来在目标范围内生成有限数量的压缩模型。另一方面,现有的基于滤波器级别的少样本CNN剪枝方法可能实现了密集压缩,但与基于块级剪枝方法相比,在精度上存在显著降低的问题。
提出的Dense Compression of Vision Transformers (DC-ViT)引入了一种新颖而有效的方法,实现了ViTs和CNNs的密集压缩。该方法可以生成不同尺寸的压缩模型,密集地覆盖了目标计算资源(MACs)的范围。此外,还引入了一种衡量块重要性的新指标,该指标与压缩不同块后微调模型的实际性能相一致。据作者所知,DC-ViT是第一篇解决ViTs和CNNs密集少样本压缩问题的工作。
1.目的:研究ViT模型的Few-Shot压缩方法,要求保证精度并降低延迟
通过网络压缩技术减少技术和内存成本以便适用小型设备,同时为了应对数据获取不方便(包含敏感数据如医疗,商业),将少样本的压缩方法从之前主要集中在CNN转向ViT模型扩展,并克服稀疏压缩方法只能生成限定的压缩模型。限定的压缩模型会造成可选的算力压缩很少导致算力浪费准确度较低的缺点。
2.相关技术:
CNN领域:
① PRACTISE:块级少样本剪枝,精度更好,稀疏压缩,丢弃不同数量的块产生四个模型。
② RegNetY-16GF:RegNetY-16GF是一种基于RegNet架构的模型。RegNet是一种经验设计的神经网络架构,旨在提供高性能和高效率的解决方案。(滤波器级获得密集型)
③ FSKD(Few-shot Knowledge Distillation)[51]:FSKD是一种少样本知识蒸馏方法,用于压缩CNN模型。它通过将大型教师网络的知识转移给小型学生网络,以减少学生网络的参数量和计算开销。(滤波器级获得密集型)
④ CD(Collaborative Distillation):CD是一种协作蒸馏方法,用于少样本CNN压缩。它通过联合训练教师网络和学生网络,以提高学生网络的表示能力和泛化性能。CD方法通过优化协作蒸馏损失,使学生网络能够从教师网络中获取更多的知识,并减少学生网络的参数量。(滤波器级获得密集型)
⑤ MiR(Model Reuse):MiR是一种少样本CNN剪枝方法,它通过模型重用的策略来压缩网络。具体来说,MiR利用预先训练好的大型模型,在少量样本上进行微调,并通过剪枝和修剪操作来减少网络的参数量。MiR方法通过模型重用和剪枝操作,实现了在少样本情况下的高效压缩。(滤波器级获得密集型)
ViT领域:
① Mini-DeiT-B:基于DeiT(Training data-efficient image transformers)架构的模型。DeiT是一种用于图像分类任务的Transformer模型,它通过在大规模预训练数据上进行预训练,并在较少的数据上进行微调,实现了高效的图像分类性能
② VTP:渐进式训练策略的Vision Transformer模型。渐进式训练通过分阶段地增加训练数据的难度和复杂度,逐步提高模型的泛化能力和性能。VTP模型使用Vision Transformer架构,并结合渐进式训练的方法来提高图像分类任务的性能
③ S2ViTE-B:图像分类任务的Transformer模型,它通过将图像分割为小块,并在每个块上进行局部自注意力计算,以减少全局自注意力的计算复杂度
④ AutoFormer-B:基于AutoFormer架构的模型。AutoFormer是一种自动化设计的Transformer架构,它使用神经架构搜索(NAS)技术来优化网络结构。AutoFormer利用搜索算法进行网络结构的探索,并自动选择最佳的特征表示和注意力机制。
DC-ViT:第一个块级密集型少样本压缩方法(在ViT和CNN上)
理论方法
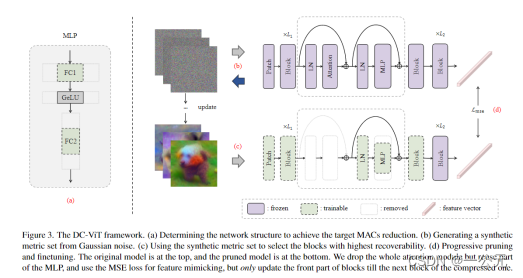
一、确定网络结构:1.删除k个block ,用mlp代替,同时对block中的mlp模块进行缩减,缩减比例为rd,作为ViT块中的MLP有2个完全连接的(FC)层,特征的维度从d到4d,然后再回到d。我们将中间结果的维数从4d改为4d(1−rd)。(从4d中随机选取4d(1−rd)节点)。
二、选取要删除的块:
(1):根据分组试验程序(block-wise trial procedure)获得块Bi压缩的候选模型Mp(Bi),并创建具有少量没有标签的原始训练集的小的子集Dt,在这个子集上进行C分类的few-shot的任务,根据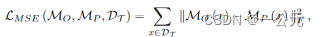 使用均方误差(MSE)损失进行特征模拟,以最小化修剪模型和原始模型之间的特征差距,来达到对所有的Mp(Bi)进行微调。MP (x)和MO (x)分别表示修剪模型和原始模型的所有输出token的并集。尽管 CLS token通常被认为是图像的表示,但使用所有输出token进行特征模拟比只关注 CLS token效果更好。(通过只更新前几个块直到最后一个压缩块,而不是所有块,不仅提高了微调模型的准确性,而且减少了梯度反向传播的时间成本)。
使用均方误差(MSE)损失进行特征模拟,以最小化修剪模型和原始模型之间的特征差距,来达到对所有的Mp(Bi)进行微调。MP (x)和MO (x)分别表示修剪模型和原始模型的所有输出token的并集。尽管 CLS token通常被认为是图像的表示,但使用所有输出token进行特征模拟比只关注 CLS token效果更好。(通过只更新前几个块直到最后一个压缩块,而不是所有块,不仅提高了微调模型的准确性,而且减少了梯度反向传播的时间成本)。
(2):生成综合度量集,用于进行数据增强,增加样本丰富度,用于揭示经过微调的候选模型的性能。在假设深度神经网络可以充分训练和保留数据集中的关键信息的情况下,我们建议在不使用外部数据的情况下,利用原始预训练模型生成合成图像作为块选择的度量集S。生成方式:利用预训练模型的内在知识来高效地生成紧凑的合成图像,形成一个鲁棒的度量数据集。给定一批高斯噪声作为初始合成图像S = {φ x1, φ x2,···,φxn},任意目标标签Y = {y1, y1,···,yn},通过公式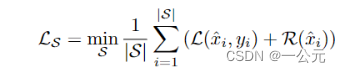 对合成图像进行更新。
对合成图像进行更新。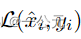 是预测概率和目标标签的交叉熵,
是预测概率和目标标签的交叉熵,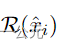 是正则化项
是正则化项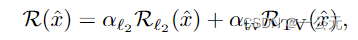 ,
,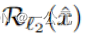 是图像先验正则器(L2正则),提高图像的稳定性。
是图像先验正则器(L2正则),提高图像的稳定性。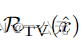 是总变分,用于控制合成数据的清晰度,去锐度。
是总变分,用于控制合成数据的清晰度,去锐度。
(3):选择压缩块的标准。由于vit块在同一模型中都相同,所以压缩不同块导致的延迟差异很小,不适合用作选择压缩块的度量。于是用(2)中得到的度量集,利用下面的公式衡量候选模型在该度量集上的表现。
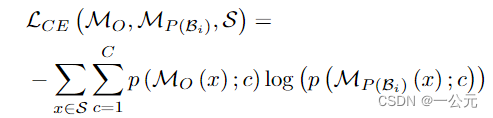
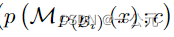 表示训练样本x被第i个候选模型分类到第c类的概率,该概率使用输出CLS令牌计算,然后进行线性和softmax变换。
表示训练样本x被第i个候选模型分类到第c类的概率,该概率使用输出CLS令牌计算,然后进行线性和softmax变换。
三、修建和微调方法:逐步剪枝和微调。由于Few-Show压缩是一个微妙的过程,因此在单个阶段将对模型结构的广泛修改 最小化是有益的。采用渐进式压缩方法不仅可以降低潜在风险,而且性能更优。算法如下:
输入:原始模型MO,小型训练集DT,合成度量集合S,要压缩的块数k,MLP节点的丢弃率rd
输出:压缩后的模型MP
1.将原始模型MO赋值给MP,创建一个空列表mList。
2.对于MP中的每个块Bi,执行以下操作:
a. 从Bi中删除注意力机制,并从MLP节点中(随机地)丢弃一部分(根据rd比例)。
b. 最小化损失函数Lmse(MO, MP(Bi), DT)来更新MP(Bi),即对Bi进行微调。
c. 计算度量损失Lm = LCE(MO, MP(Bi), S)。
d. 将(Lm, i)的对加入到mList中,其中i表示块Bi的索引。
3.根据每个块的度量损失对mList进行排序。
4.选择mList中度量损失最小的前k个块的索引,存储在C中,表示要压缩的块。
5.逐步压缩MP中的C中的块。
6.返回压缩后的模型MP。

在这个算法中就清晰地说明了修建和微调模型的方法和依据。
实验过程
DeiT代表"Training data-efficient image transformers",是一种用于图像分类任务的Transformer模型。DeiT的设计旨在通过使用较少的训练数据实现高效的图像分类其核心是提出了针对 ViT 的教师-学生蒸馏训练策略。
1.选取实验模型架构:基础vit,更小或更大的vit变体,DeiT-B,Swin-B,还有CNN结构
2.数据集:微小训练集Dt为Imagenet上随机抽取,并用了验证集评估修剪模型,标准差和平均精度选取了五个随机种子进行验证提高可信度。
3.实验超参数:在224*224分辨率上进行
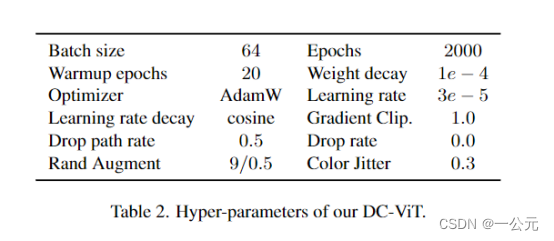
4.往前研究缺乏Few-Shot的vit压缩方法,绝大多数依赖完整数据集,在Few-Shot上效果不行。比如原本sota的vit压缩方法s2pvit,evit在全样本时在DeiT上取得了好的性能,但在1000个训练样本时就都没有收敛(相比Few-Shot,1000个样本已经比较大了),同时一些好的对CNN模型进行Few-Shot的方法由于结构不同不能很简单的用在ViT上,都涉及到卷积。因此,作者采用了最先进的少样本CNN剪枝方法PRACTISE ,并将其直接扩展到ViT作为一个强有力的基准方法。为了进一步验证DC-ViT的有效性,作者还将DC-ViT扩展到CNN架构,并将其与一些著名的少样本CNN剪枝方法进行了性能对比,包括FSKD [51]、CD [2]和MiR [44]。与其他少镜头剪枝方法相比,我们主要关注剪枝模型的延迟精度权衡。修剪模型的延迟是使用 64 的批量大小来衡量的,并在 500 次运行中记录了平均推理时间。
5.实验结果对比:
(1):DC-VIT与PRACTISE方法在VIT-B上的效果:
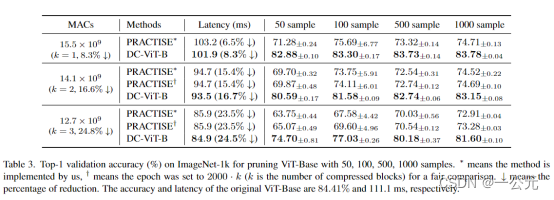
由于DC-VIT时逐块微调,每次迭代2000echo,所以总的echo为2000*k
(2):DC-VIT方法扩展用在CNN结构上与传统sota方法比较:

由于 CNN 的结构不利于像 DC-ViT 这样的密集压缩重用 MLP 节点,我们测试了我们的方法消除了整个块的情况
(3):DC-VIT用在变体vit上:
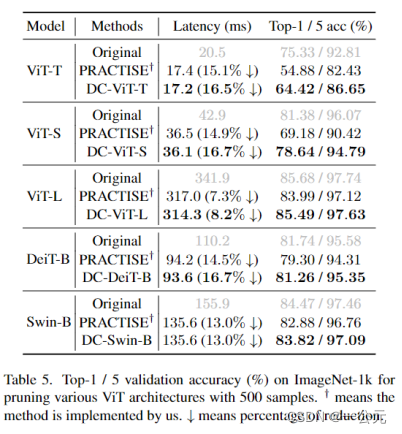
为了确保与 PRACTISE [43] 进行公平比较,我们在 DC-ViT 中统一设置修剪后的模型的 MAC 以匹配 PRACTISE 丢弃 2 个整个块的场景中。然而,由于Swin的结构复杂(计算量过高,要多删除几个块才能达到压缩的MACs),我们直接选择和消除两对连续的Swin块,即总共4个完整的块。
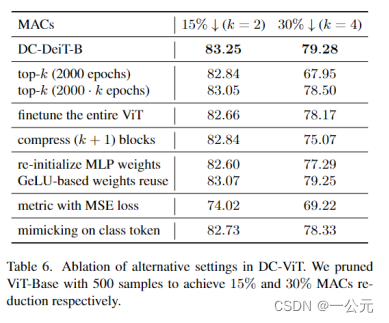
6.消融实验
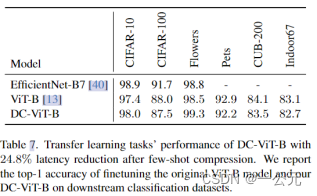
7.对不同数据集的泛化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









