







对于B+树和数据结构的对比与了解在面试中问的很多,也是我们平常理解为什么要使用这种数据结构的关键。为此通过学习一些文章,对其进行一个全面的解读。
什么是B树,B+树?
B 树(B- 树) 指的是 Balance Tree,又名多路平衡(即不止两个子树)查找树,并且所有叶子节点位于同一层。
B+ 树基于B 树和叶子节点顺序访问指针进行实现,具有 B 树的平衡性,并且通过顺序访问指针来提高区间查询的性能。通常用于数据库和操作系统的文件系统中。
B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
B树,B+树的特征
B 树的特征
● 一个m阶的B树有如下几个特征:
○ 若根结点不是终端结点,则至少有2棵子树。
○ 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
○ 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
○ 所有的叶子结点都位于同一层。
○ 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
● B 树(3阶)示例:

B+ 树的特征
● 一棵m阶B+树具有如下几个特征:
○ 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
○ 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
○ 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
● B+ 树(3阶)示例:

解释:B+ 树始终要保持最大元素在根节点当中。B+ 树的叶子节点包含了全量元素信息。并且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序链表。
无论是B树还是B+树,最底层呈现的都是有序序列。
B+树的优点
优点一: B+树的磁盘读写代价更低:B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。
优点二: B+树带有顺序访问指针:B+树所有的Data域在叶子节点,并且所有叶子节点之间都有一个链指针。 这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。在数据库中基于范围的查询是非常频繁的,而B树不支持这样的遍历操作。
优点三:B+树的查询效率更加稳定:由于非叶子节点并不是最终指向文件内容的节点,而只是叶子节点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。而B树因为非叶子节点也存在数据Data域,有可能在非叶子节点中就可获取数据并返回。
B树,B+树的使用场景
文件系统和数据库系统中常用的B/B+ 树,他通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
● Windows:HPFS 文件系统
● Mac:HFS,HFS+ 文件系统
● Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统
● 数据库:ORACLE,MYSQL,SQLSERVER 等中
● 数据库:ORACLE,MYSQL,SQLSERVER 等中
具体场景:
● B树
○ MongoDB数据库使用,单次查询平均快于MySQL (但侧面来看 MySQL 至少平均查询耗时差不多)
○ ORACLE 数据库
● B+树
○ MySQL数据库普遍使用B+树来实现索引结构
■ MyISAM 索引实现
■ InnoDB 索引实现
这里注意了,Redis 用的是 skiplist(跳表) 作为底层,而没有使用平衡树这一结构
B 树如何迎合磁盘
磁盘概述
我们都知道,计算机的存储管理是分层的,各层次之间的速度差距比较大,尤其是辅存(磁盘)和主存之间的速度。我们也知道磁盘访问比较慢,为什么会慢呢?
● 关于访存CPU访问磁盘时,磁盘主要干了这些事:
a. 寻道:磁头摆一摆,找到对应的柱面
b. 定位:盘面转一转,磁头定位到指定扇区
在访存的两个步骤中,因为是机械操作比不上主存的电信号传播,所以自然就慢了不少,磁盘访问慢了,访问效率自然就跟不上了。
那么能不能再不改变这种机械运动的情况下提升访存效率呢?
能。使用索引就可以。
● **什么是索引?**索引就好比是书的目录,比如当我们查看一本字典的时候,目录就相当于我们的对照表。索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。
所以这就要求我们建立一个好的索引来帮助我们提升访存效率。
磁盘读写原理
● 局部性原理:在一小段时间里,程序执行所访问的存储空间局限于某个内存区域。(在这一小段时间内程序只会用这一部分内存的这一小撮数据)
● 磁盘预读:在有了局部性原理之后,程序执行依次要一个数据,现在我们知道它要的数据基本都是一堆一堆的凑在一起的,那我就可以在它要之前我这个磁盘先读着我这个扇区下面的内容,不管程序是否需要。这个就是磁盘预读,预读的长度一般为页(page)的整数倍。(页是数据存储的单位。页面从主存储器加载到处理器中。页由单元块或块组组成。)
在了解了磁盘以后,我们知道问题是如何利用索引来提高访存速度。而 B,B+树就是为了解决这个问题而存在的。
如何迎合磁盘
索引的效率依赖于磁盘 IO 的次数,快速索引需要有效的减少磁盘 IO 次数。
索引的原理?B树是如何快速索引的?
索引的原理其实是不断的缩小查找范围,就如我们平时用字典查单词一样,先找首字母缩小范围,再第二个字母等等。
平衡二叉树是每次将范围分割为两个区间。为了更快,B树每次将范围分割为多个区间,区间越多,定位数据越快越精确。那么如果节点为区间范围,每个节点就较大了。
实际设计中,我们把一个节点设为一个页,直接申请页大小的空间。(磁盘存储单位是按 block 分的,一般为 512 Byte。磁盘 IO 一次读取若干个 block,我们称为一页,具体大小和操作系统有关,一般为 4 k,8 k或 16 k)
计算机内存分配是按页对齐的,这样就实现了一个节点只需要一次 IO。
多叉的好处非常明显,有效的降低了B树的高度。现在的高度为底数很大的 log n,底数大小与节点的子节点数目有关,一般一棵B树的高度在 3 层左右。 层数低,每个节点区确定的范围更精确,范围缩小的速度越快(比二叉树深层次的搜索肯定快很多)。
上面说了一个节点需要进行一次 IO,那么总 IO 的次数就缩减为了 log n 次。
B树的每个节点是 n 个有序的序列(a_1,a_2,a_3…a_n),并将该节点的子节点分割成 n+1 个区间来进行索引(X_1< a_1, a_2 < X_2 < a_3, … , a_{n+1} < X_n < a_n, X_{n+1} > a_n)。
解释:B树的每个节点,都是存多个值的,不像二叉树那样,一个节点就一个值,B树把每个节点都给了一点的范围区间,区间更多的情况下,搜索也就更快了,比如:有1-100个数,二叉树一次只能分两个范围,0-50和51-100,而B树,分成4个范围 1-25, 25-50,51-75,76-100 一次就能筛选走四分之三的数据。所以作为多叉树的B树是更快的
所以,B树就是一个很好的索引结构,因为它有效的减少了磁盘 IO 次数!
为什么使用B,B+树?
根据上面的章节可以得到,传统用来搜索的平衡二叉树有很多,如 AVL 树,红黑树等。这些树在一般情况下查询性能非常好,但当数据非常大的时候它们就无能为力了。(这些树的高度比较高)
原因当数据量非常大时,内存不够用,大部分数据只能存放在磁盘上,只有需要的数据才加载到内存中。一般而言内存访问的时间约为 50 ns,而磁盘在 10 ms 左右。速度相差了近 5 个数量级,磁盘读取时间远远超过了数据在内存中比较的时间。这说明程序大部分时间会阻塞在磁盘 IO 上。
那么我们如何提高程序性能?减少磁盘 IO 次数,像 AVL 树,红黑树这类平衡二叉树从设计上无法“迎合”磁盘。
平衡二叉树是通过旋转来保持平衡的,而旋转是对整棵树的操作,若部分加载到内存中则无法完成旋转操作。 其次平衡二叉树的高度相对较大为 log n(底数为2),这样逻辑上很近的节点实际可能非常远,无法很好的利用磁盘预读(局部性原理) 。
在最坏的情况下,一次IO就只能获得一个结点的值,所以在最坏的情况下,不管是红黑树还是AVL树、B树、B+树,他们对应的磁盘操作是树的高度。而B树和B+树的高度是低的,适应数据库和文件系统的。
所以 AVL 树,红黑树这类平衡二叉树在数据库和文件系统上的选择就被 pass 了。
B树 vs B+树
● B+树的磁盘读写代价更低 :(节点结构不同决定)B+树的非叶子节点不存储数据,所以其内部结点相对B树更小,如果把所有同一非叶子结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。相对来说IO读写次数也就降低了,查找速度更快了。
● B+树查询效率更稳定:B+树内非叶子节点不存储数据,而是只是叶子结点关键字的索引,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。 所以B+树中任何关键字的查找必须走一条从根结点到叶子结点的路,所有关键字查询的路径长度相同,导致每一个数据的查询效率相当,而对于B树来说,因为每个结点都存有具体的数据,因此其查询速度不稳定,可能很快也可能很慢。举个例子:我们查询 9 这个元素,从上图可以看出,key 为 9 的节点就在第一层,B树只需要一次磁盘 IO 即可完成查找。所以说B树的查询最好时间复杂度是 O(1)。由于B+树所有的 data 域都在根节点,所以查询 key 为 9的节点必须从根节点索引到叶节点,时间复杂度固定为 O(log n)。
● B+树便于范围查询:B树在提高了IO性能的同时,并没有解决元素遍历效率低下的问题。为了解决这个问题,B+树应运而生。B+树只需要遍历叶子结点就可以实现整棵树的遍历(B+树叶子结点维护有序链表。在数据库中基于范围的查找也是非常频繁的,因此MySQL的Innodb引擎就使用了B+树作为其索引的数据结构。
AVL树 vs B树
AVL 树(左),B 树(右)
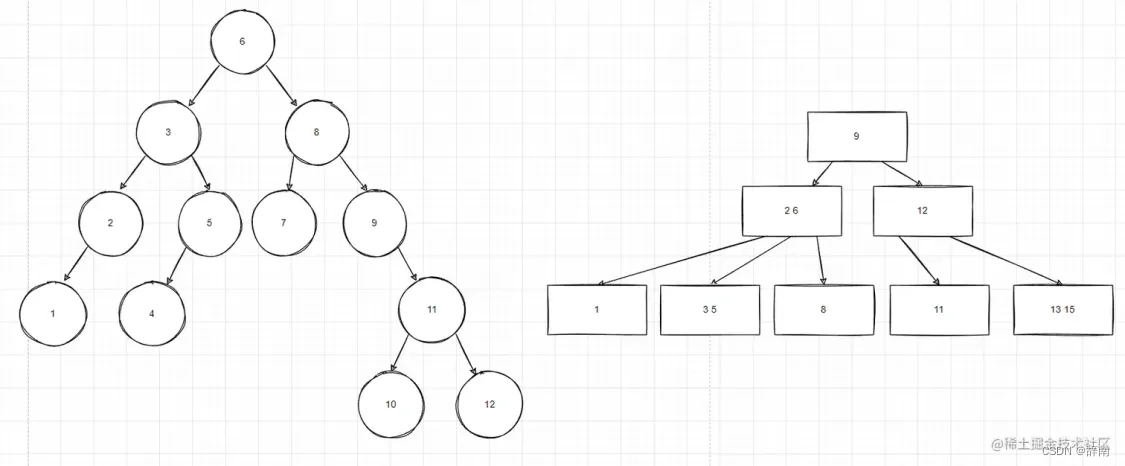
● B树的节点和AVL树的节点结构不同:平衡二叉树的节点,每个最多有一个数据和最多两个子树。B树的节点,每个节点可以有不止一个数据,同时可以拥有的子树数量是阶数决定的。
● B树的查找效率更高:B树的每个节点可以表示的信息更多,因此整个树更加“矮胖”,这在从磁盘中查找数据(先读取到内存、后查找)的过程中,可以减少磁盘 IO 的次数,从而提升查找速度。
== 如果要对比 AVL 树和 B+ 树,那就再加上上面 B 树和 B+ 树的对比就好啦!==
B+树 VS 红黑树
AVL 树(平衡二叉树)和红黑树(二叉查找树)基本都是存储在内存中才会使用的数据结构。在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。
为什么会出现这样的情况?
那就又回到上面的磁盘IO,数据库系统的设计者巧妙利用了磁盘预读原理和局部性原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
磁盘和内存选择B+ 树的原因
- B+树的高度要比红黑树小,有效减少了磁盘的随机访问
- B+树的数据节点相互临近,能够发挥磁盘顺序读取的优势(缓存)
- B+树的数据全部存于叶子结点,而其他节点产生的浪费在经济负担上能够接收,红黑树存储浪费小
红黑树优点: 红黑树常用于存储内存中的有序数据,增删很快
B+树这些特性适合用于数据库的索引,mysql底层数据结构就是B+树。
B树更适用于磁盘读取,红黑树更适用于内存读取
B+树 VS Redis 跳表
B+树是一种自平衡的搜索树,特别适用于读写大量数据的系统。而跳表是一种可以快速搜索的表结构,它通过维护多个"快速通道"的链表来实现对数据的高效访问。
对比:
- 数据存储和I/O操作:B+树中,所有键值对都存储在叶子节点,中间节点仅存储对键的引用,一次磁盘I/O可以读取一个节点的大量数据,效率高。而跳表的数据分散存储,一次磁盘I/O只能读取极少数据,导致I/O浪费严重。
- 区间扫描:B+树所有叶子节点构成了一个有序链表,可以在O(log n)时间内完成区间查询。跳表虽然也可以执行区间查询,但由于数据分散存储,会涉及多次磁盘I/O,效率较低。
- 稳定性:B+树查询、插入和删除的时间复杂度都是稳定的O(log n),性能稳定。而跳表由于层数随机,最坏情况可能需要线性查找,存在性能波动。
因此,对于需要高效读写大量数据并执行区间查询的数据库系统,B+树因其高效的磁盘I/O利用率、有序的区间扫描能力和稳定的表现,通常是更好的选择。虽然跳表执行简单查询的效率很高,这在主存数据结构中很有优势,但在数据库这种需要频繁磁盘I/O和区间查询的场景下,它的表现则相对较差。
B+ 树层数计算
在实际的数据库系统中,B+树的层数取决于多种因素,其中包括:
阶数(Order):这是B+树中最重要的参数之一,表示每个节点(除叶节点外)最多可以有多少子节点。对于叶节点,它表示节点最多可以包含多少键值对。阶数通常受到底层存储系统的块大小影响。
键(Key)和指针(Pointer)的大小:键和指针的大小直接影响一个节点能存储的键值对数目和指针数量,因此也影响树的深度。
数据量:数据总量的大小决定了需要多少个叶节点来存储所有数据。
在一个典型的关系型数据库中,阶数的大小能够使得每个节点能够存储数百到数千个键值对。这意味着即使对于庞大的数据集,B+树也通常只有几层深度。例如:
对于小到中等规模的数据库,B+树的深度可能在3到4层左右。
对于大型数据库,即便是有数亿记录,B+树的层数一般也不会超过10层。
确切的层数会根据具体的实现和存储需求而有所不同。在设计数据库索引时,B+树的高度保持在尽可能低的水平是非常重要的,因为每增加一层,查询数据所需的磁盘IO次数就会增加,这会影响查询效率。因此,实现高效的数据库索引需要精心设计B+树的参数,以保持树的平衡和查找效率。
需要注意的是,由于B+树的分叉性很高,其层数与平均的二叉搜索树相比,要少得多。这是B+树特别适用于数据库索引的原因之一:尽管数据量巨大,但是由于其高阶,查找效率仍然非常高。
800W数据要多少层B+树?
B+树的层数与树的阶数(即每个节点能包含的最大子节点数)有关,也与数据本身的分布、节点的填充情况有关。在实际应用中,B+树的节点在磁盘中通常对应一个磁盘的块大小,比如4KB。
为了计算800万(8,000,000)数据大概需要多少层B+树,我们需要知道以下几点信息:
B+树的阶数(m):这通常是由磁盘块的大小和键值对以及指针大小决定的。阶数表明了一个节点最多能有多少个子节点。
每个块中能够包含的键的数量:也就是叶子节点能包含的数据量(n)。
节点的使用效率:节点可能不会完全填满,可能有介于50%到100%之间的填充因子。
由于真实值通常不能完全填充一个节点,假设我们的填充因子是100%来简化计算。如果B+树的阶数为m,那么:
第一层(叶子层)可以有m个元素。
第二层可以有m^2个元素。
第三层可以有m^3个元素。
… 以此类推。
如果只有叶子层(第一层),那么需要满足m >= 8,000,000。第二层则需要m^2 >= 8,000,000,以此类推。我们可以使用对数来计算需要多少层来包含800万个元素。
举一个简化的例子:假设每个节点可以存储1000个键值对,这意味着B+树的阶数大约是1000(这仅仅是为了演示计算过程,真实的阶数取决于键和指针的实际大小)。那么层数(L)的计算公式是:
1000^L >= 8,000,000
求解L就可以得到:
L >= log_1000(8,000,000)
L >= log(8,000,000) / log(1000)
L >= 3.903 / 3
L > 1.3
由于层级数必须是整数,我们要取大于1.3的下一个整数,所以我们需要2层,也就是数据层和一个索引层。当然,如果数据节点不是完全填满,或树的阶数大不同于1000,则层级数可能不同。这仅是为了说明如何根据不同的数据量和阶数来估计B+树可能的高度。在实际的数据库系统中,B+树的层数通常很少,因为其高阶数意味着每个节点可以存储大量的键。
参考文章:
1、8分钟,复习一遍B树,B+树! - 掘金
2、B+树详解















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









