







最近学了个小玩意——数据爬虫
暑假在家没学多少算法,迷上了编程的一些实战,第一个就是数据爬虫
数据爬虫就是一只网页蜘蛛,用于爬取网页数据。我原先是用Python编写,后来逻辑清晰后感觉Java写这东西也是绰绰有余啊。
有一个小工程:获取京东商品——手机的数据并写入文件中,在这里是使用 jar包 Jsoup来实现,方法比较简单,大致可以分为以下几步——获取URL——建立连接——获取HTML——解析HTML。
工程开始
首先我们得到一个URL
URL urlmode=new URL("https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8");
我们需要分析一下网页,观察翻页后网址的变化,不难看出翻页规则是 2*i-1


于是就可以得到每一页的URL
URL url=new URL(urlmode.toString()+"&page="+String.valueOf(2*i-1));
随后我们需要观摩一下京东前端同学写的HTML源码,以获取我们想要的数据,通过控制台可以找到我们想要数据在标签树的位置
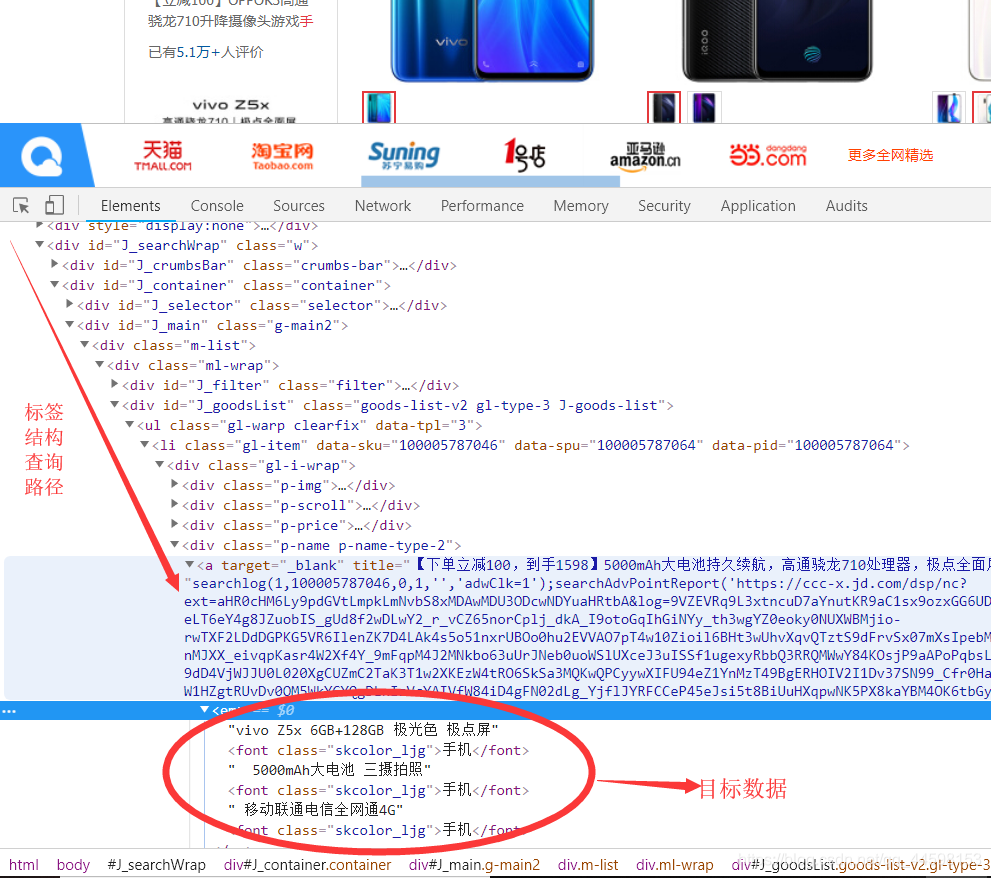
然后观察一下源代码,准备工作就结束了。
开始实现
这里暂且只抓取商品名字,因为 Jsoup 的方法比较多,就不再说明。其实细想一下这个工程也没有多少东西,无非就是拿到网页,然后解析。最后 引用IO流 把爬到的数据写入到文件中去。
package BaiDuPic;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.net.URL;
import java.util.List;
import java.util.Scanner;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Demo1 {
public static void main(String[] args) throws Exception {
Scanner sc=new Scanner(System.in);
System.out.println("起始页:");
int start=sc.nextInt();
System.out.println("结束页:");
int end=sc.nextInt();
//引用IO流
BufferedWriter bw=new BufferedWriter(new FileWriter("src\\jdphone.txt"));
//目标URL
URL urlmode=new URL("https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8");
for(int i=start; i<=end; i++) {
//根据京东翻页建立每一页的URL
URL url=new URL(urlmode.toString()+"&page="+String.valueOf(2*i-1));
System.out.println("开始抓取第"+i+"页商品数据");
//伪装成浏览器并建立连接
Connection connect=Jsoup.connect(url.toString()).userAgent("Mozilla/5.0");
//获取网页Document
Document doc=connect.get();
//System.out.println(doc.text());
//解析网页
Elements elements=doc.getElementsByClass("p-name p-name-type-2");
//选择器获取文本并以字符串形式存入List
List<String> link=elements.select("em").eachText();
bw.write("=======第"+i+"页商品数据如下:"+"======="+'\n');
//打印商品数据
for(int j=3; j<link.size(); j+=2) {
String str=link.get(j)+'\n';
bw.write(str);
System.out.print(str);
}
Thread.sleep(1000);
System.err.println("第"+i+"页共"+link.size()+"件商品全部写入文件中");
}
//关闭
bw.close();
sc.close();
}
}
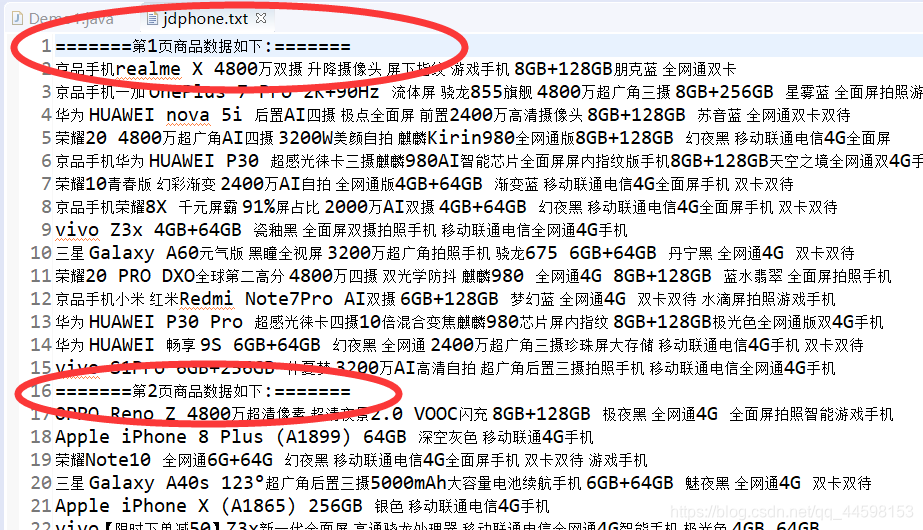
收尾检验
窗口输出的爬取结果

文件写入检查














 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









