







摘要
对于从事Java开发的小伙伴而言,“线程池”一词应当不陌生,虽然在实际工作、项目实战中可能很少用过,但是在工作闲暇或吹水之余还是会听到他人在讨论,更有甚者,在跳槽面试等场合更是屡见不鲜,已然成为一道“必面题”。从本文开始我们将开启“Java线程池实战总结”系列文章的分享,帮助各位小伙伴认识、巩固并实战线程池的相关技术要点。
内容
- 吹一波“线程池”
“线程池”,字如其名,是“线程”+“池”合并得来的,“线程”的含义自然不用多说,而“池”其实是一种“设计思想”,即池化设计技术,这种思想简而言之是为了能更好地重复利用资源,减少因资源重复创建而带来的损耗,提高资源重复利用率。
“池化设计”带来的产物有很多,目前在市面上我们经常可以见到的有“数据库连接池”、“Http连接池”、“Redis连接池”以及我们本文要介绍的“线程池”等等,都是对这种设计思想的应用。
线程池提供了一种限制和管理“线程”资源的机制,池里面的每个线程所承担的职责无非就是执行项目、程序中待执行的任务,当待执行的任务数量大于1时,线程池中预先分配好的多个线程便起到了作用,当执行完任务后,线程并不会立即被Kill掉,而是会保留在线程池一段时间,等待下次被重复利用。
- 基于ThreadPoolExecutor实现百万数据的批量插入
接下来,我们以实际项目中典型的业务场景“多线程批量插入随机生成的200w条数据”为案例,初步认识并了解Java中如何使用线程池 ThreadPoolExecutor 做一些事情。
(1)首先,我们得先定义这些事情,也就是“任务” 是什么,特别是要让我们的系统、线程知道待执行的每个“任务”是什么,很显然,我们的任务是“插入数据”,而这些数据将插入数据库表 book中,该数据库表的DDL定义如下所示:
CREATE TABLE `book` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '书名',
`author` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '作者',
`release_date` date DEFAULT NULL COMMENT '发布日期',
`is_active` tinyint(255) DEFAULT '1' COMMENT '是否有效',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='书籍信息表';而这个任务其实可以通过 实现 Runnable 接口或者 Callable 接口来定义,只有通过这种方式定义,我们的系统才认识,如下代码所示:
class insertTask implements Callable<Boolean>{
@Override
public Boolean call() throws Exception {
Book b;
String msg;
for (int i=0;i<50000;i++){
b=new Book();
msg=snowflake.nextIdStr();
b.setName(msg);
b.setAuthor(msg+"-A");
b.setReleaseDate(new Date());
bookMapper.insertSelective(b);
}
return true;
}
}在上述代码中,我们定义了每个线程待执行的“任务”:循环插入 5w 条数据,其中,为了避免多线程并发生成相同的数据,我们采用了雪花算法工具生成了“全局唯一ID”;而200w的数据,需要在外部循环遍历 40次,如果用传统的“单一线程”进行实现,很显然是行不通的(那得插到天昏地暗才能完成….)
(2)有了任务,那么接下来就需要有“线程”去执行,在这里我们需要定义线程执行器 ThreadPoolExecutor 实例,讲给这位大佬安排处理,即用于在线程池创建 N 个线程,并用于执行执行这 40个 任务,其源码如下所示:
@Autowired
private BookMapper bookMapper;
private ArrayBlockingQueue queue=new ArrayBlockingQueue(8,true);
private ThreadPoolExecutor.CallerRunsPolicy policy=new ThreadPoolExecutor.CallerRunsPolicy();
private ThreadPoolExecutor executor=new ThreadPoolExecutor(4,8,10, TimeUnit.SECONDS
,queue,policy);
private static final Snowflake snowflake=new Snowflake(3,2);
@Test
public void testBatchInsert() throws Exception{
List<insertTask> tasks= Lists.newLinkedList();
for (int j=0;j<40;j++){
tasks.add(new insertTask());
}
executor.invokeAll(tasks);
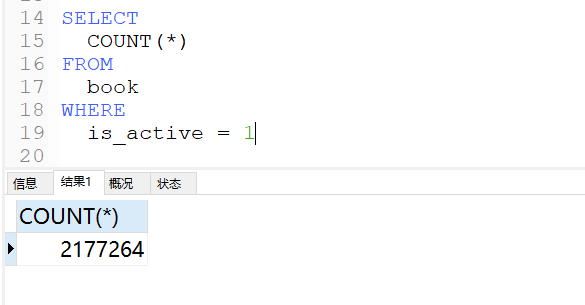
}点击运行该单元测试方法,之后需要等待一定的时间,最终你会在IDEA控制台看到同时会有好几个线程并行插入数据,在数据库表中也最终可以看到其成功插入了 200w 条数据,如下图所示:















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









