







pandas
pandas是数据分析的核心框架,集成了数据结构化和数据清洗以及数据分析的一些方法。pandas在numpy的基础上新增了3个数据结构,Series、DataFrame、Pannel
安装
在黑屏终端使用命令
pip insatll pandas
下载慢的话,使用国内镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
导入pandas
import pandas as pd
# 和numpy联用
import numpy as np
1. Series
series是一种类似于一维数组的对象,由以下两部分构成:
values:一个一维数组(ndarray类型)
index:相关数据的索引
导入
from pandas import Series
1.1 Series的创建
1.1.1 用数组或者列表来创建
在用数组或列表创建Series的时候,需要传两个参数
参数data,必须传,它作为Series的values部分;
参数index,不是必须传的,index作为Series的index部分,如果不传,则默认取数字或者列表的
下标作为index部分(从0开始)
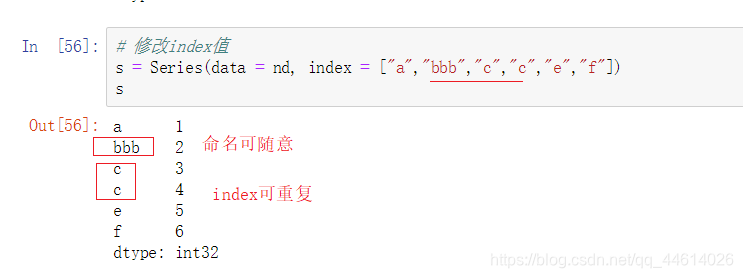
【注】index可以重复
- 数组方式:
首先创建一个数组
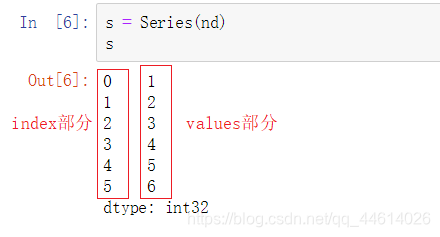
通过数组创建Series
修改index值

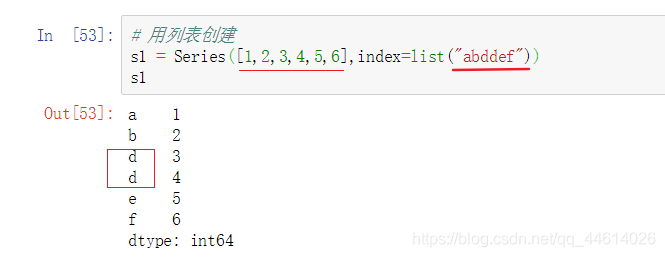
- 列表方式
1.1.2 用字典来创建
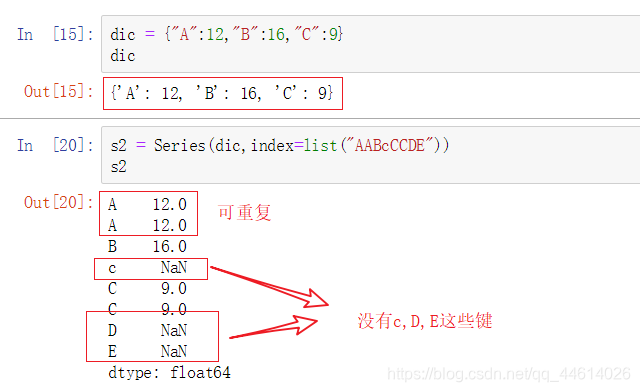
用字典创建,index部分由字典的键(keys)组合而成,values部分由字典的值(values)组合而成
用字典创建index中的个数可以和字典中的键值对个数不一致,不一致的地方字典中对应的键不取,
这些不一致index值对应value是NaN
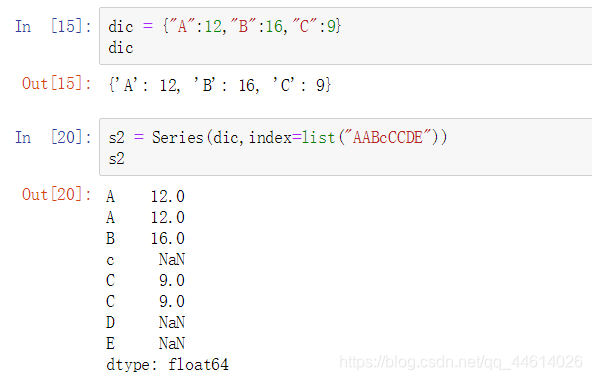
首先创建一个字典
通过字典创建Series

问题:字典、数组、列表创建的时候有没有产生副本拷贝?
- 通过元组创建的对象
由数组创建Series没有产生副本,而是将数组直接作为Series的values部分,所以修改的时候可以直接修改values的值

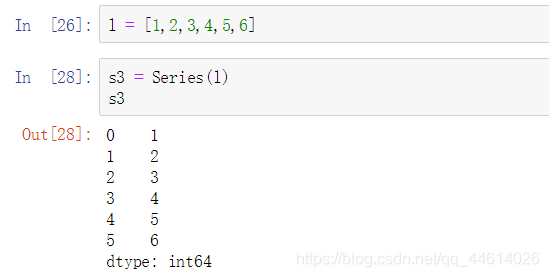
- 通过列表创建的对象
先通过列表l创建一个对象s3
修改一下第一个值,输出列表,发现列表本身并没有变化,所以产生了副本
由列表创建Series产生的副本,列表首先会被拷贝副本,然后将副本创建成一个数组,做为 series的values部分

- 通过字典创建的对象
s2是通过字典创建的Series对象
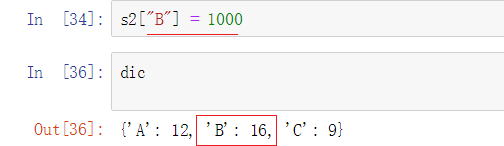
修改一下B的value,查看字典,发现字典本身的 键"B" 对应的value值并没有改变,所以产生了副本
由字典创建Series产生的副本,首先取index,根据index的顺序才能从字典中取键相对应的值,
如果没有用NaN表示,然后把这些相对应的值构成一个数组作为Series的values部分
2、Series的属性
属性:index、values、shape、size
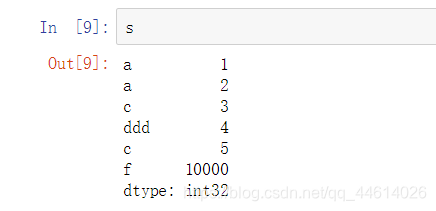
首先看一下s这个对象
2.1 index属性
index是一个index对象里面是一个列表,第二个元素是"c"(从0开始数)

index属性只读,不能随意修改,比如这里修改第二个元素,想将c改成f,直接报错
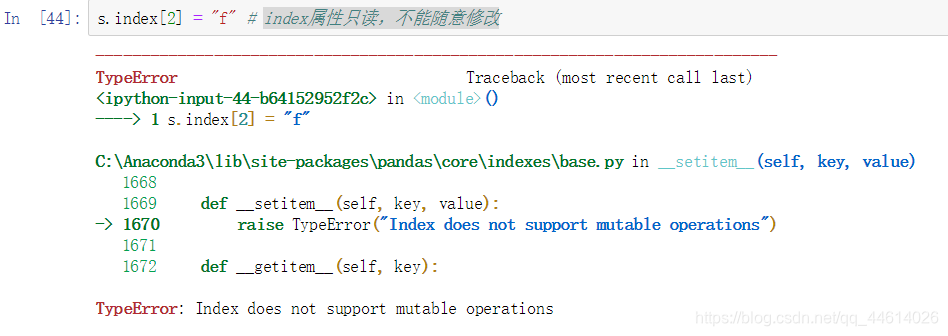
不能随意更改,其实还是可以有方法更改的
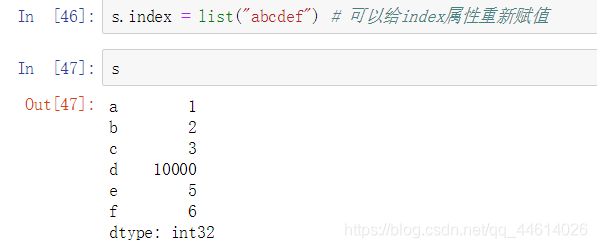
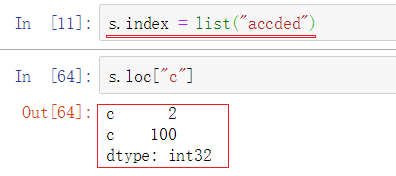
通过给index属性重新赋值的方式更改,这一列的index都改了
2.2 values属性
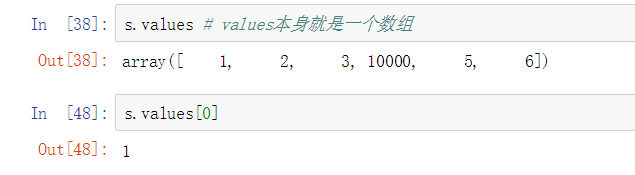
values本身就是一个数组,可通过下标获取对应的value值(从0开始)
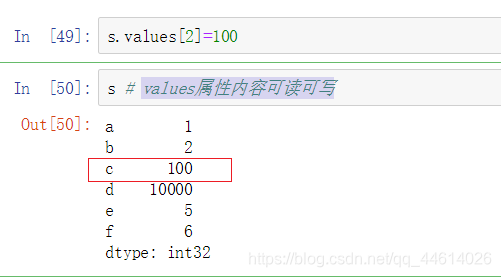
values属性内容可读可写
将第二个元素改为100
2.3 shape、size
shape 形状 size 大小
Series的形状是一维,用于处理对一维数据的整合与分析
3、Series的索引与切片
Series有两种索引方式:隐式索引和显式索引
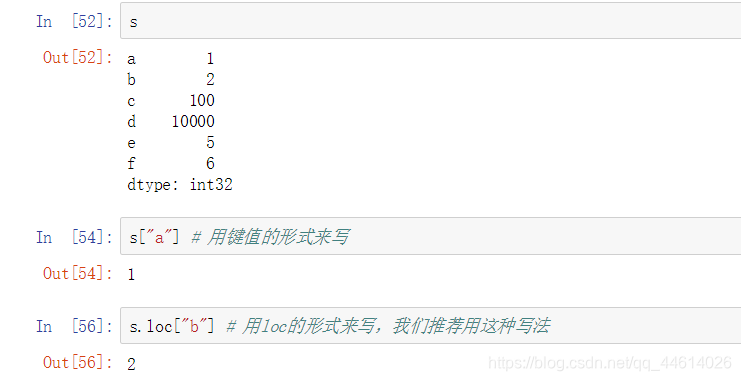
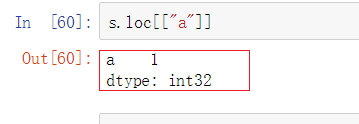
3.1 显式索引
显式索引就是用index值来作为索引
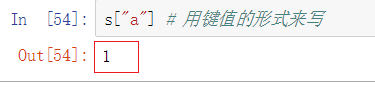
有两种方式:用键值的形式来写和用loc的形式来写,推荐用loc
在进行索引的时候需要注意:
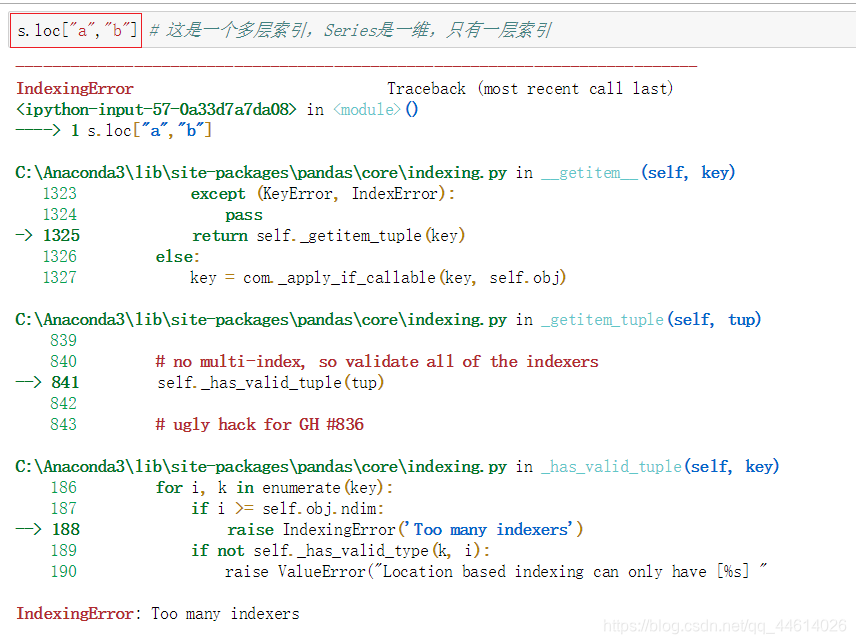
- series是一维数据结构,不能用多层索引
- 如果用一个index值作为索引,这个index值对应的values如果是一个则得到一个具体常数,如果对应的是多个,则得到的是一个Series
- 如果用一个列表中装若干(包含1个)个index值作为Series的索引,则得到的是一个Series
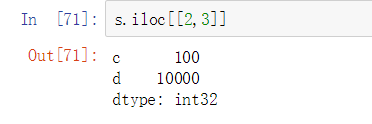
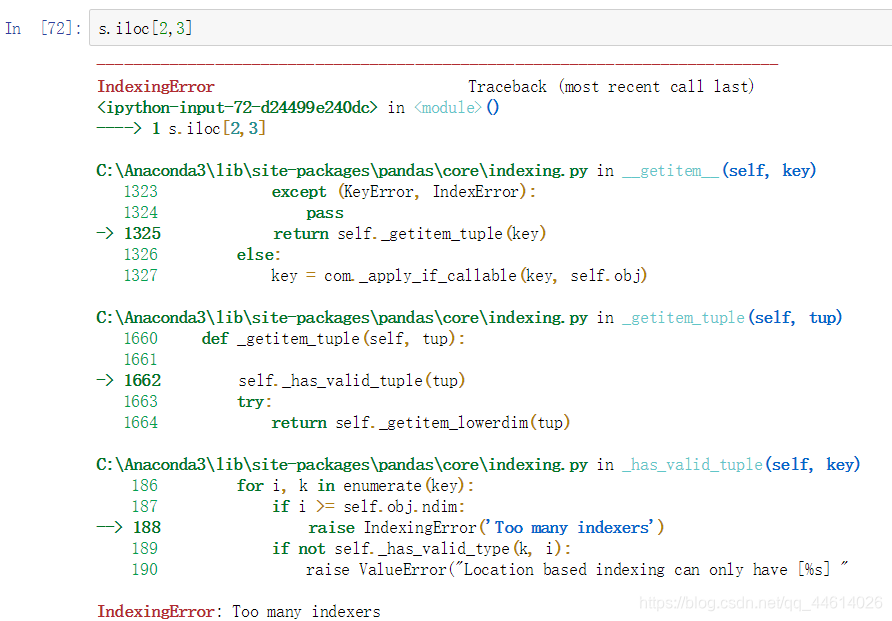
如果要索引多个,并不是加逗号就行了,可以看到报错了,这样去索引的话是一个多层索引,Series是一维,只有一层索引,所以无法进行多层索引,
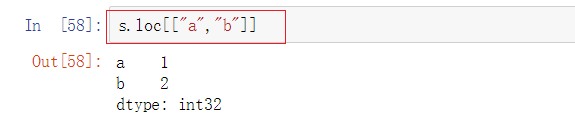
但是就是想取到相应的多个values,怎么做呢?可以通过得到一个Series的方法,但显示的不单单只有values,还有相应的index值
多加一层中括号,就变成了Series
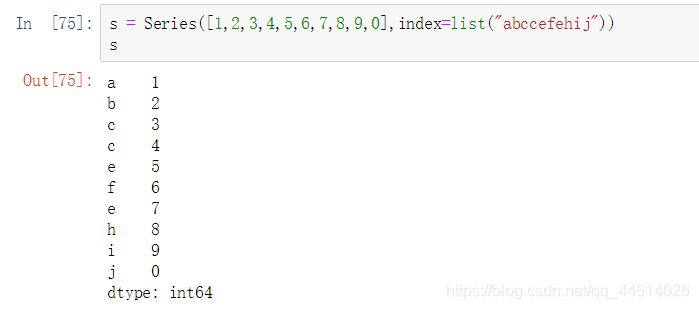
对比一下就i明白什么意思了,这个是Series,以键值的方式显示
对比前面的只有一层中括号,表示的是通过用index值来作为索引显示的是value值
意思就是用一个列表中装若干(包含1个)个index值作为Series的索引去进行索引,得到的是得到的是一个Series
3.2 隐式索引
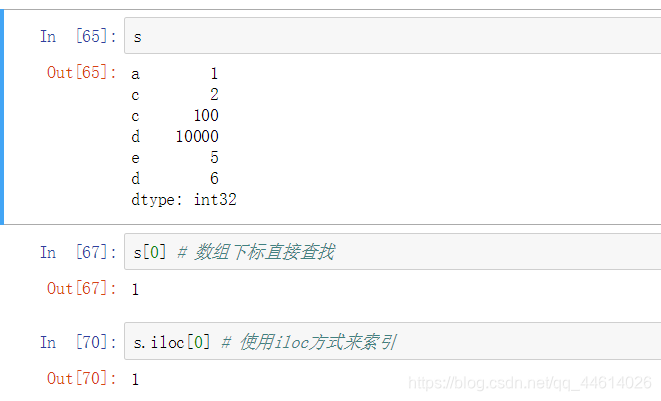
使用values部分的下标来作为索引
同 显式索引,也有两种方法:
通过数组下标直接查找 和 使用iloc方式来索引
如果要索引多个呢?也是和显式索引一样,通过列表的形式
如果直接索引两个,变成了多层索引,会报错
3.3 切片
首先创建一个Series对象
显示索引切片
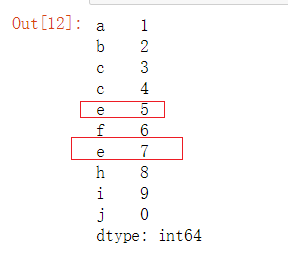
- 显示切片前后都可以取到,即前后都是闭区间
- 如果端点处的索引有多个,切他们连续,则可以切到最后一个
- 如果端点有多个,但是多个端点不连续,则不能用其作为端点
因为这里两个e被 f 隔开了



隐式索引切片

【拓展】
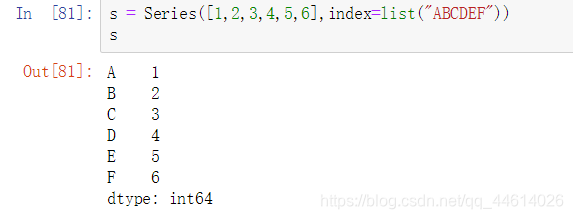
先创建一个Series对象s
再创建一个Series对象s1
s1和s之间index部分完全一致,s1的values部分为bool类型,s的values部分为普通数据
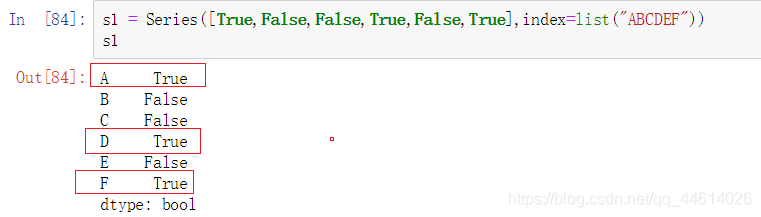
此时s1表达的内容可以是为True的那些索引是需要输出部分
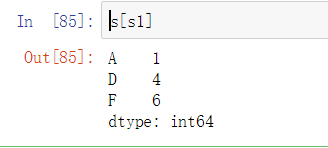
用s1作为s的索引
ndex为True的那些元素被输出
4、Series的数据清洗
数据清洗:主要是清洗数据缺失部分和异常部分
4.1 缺失
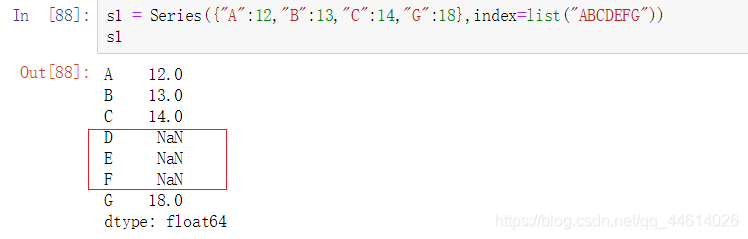
首先创建一个Series对象s1,DEF没有给定数值,默认用NaN补上
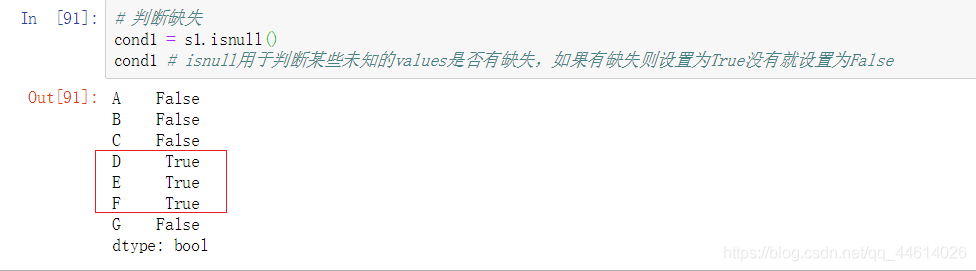
- 判断缺失 isnull()
isnull用于判断某些未知的values是否有缺失,如果有缺失则设置为True没有就设置为False
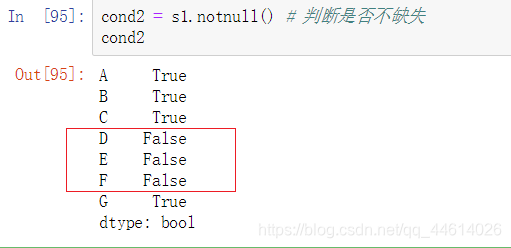
- 判断是否不缺失 notnull()
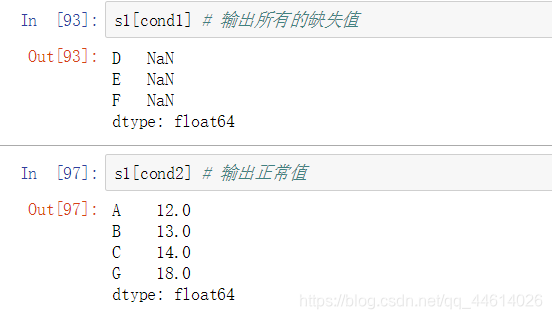
- 输出正常值和缺失值
cond1 缺失值显示True cond2 正常值显示True
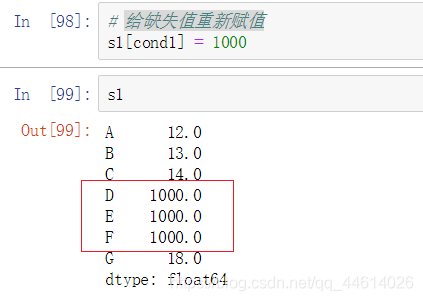
- 给缺失值重新赋值
cond1 缺失值显示True
4.2 异常
异常源于需求:需求分析中说什么情况下是异常,此数据就是异常
创建一个Series对象,其中20个元素为[0~100)的随机整数
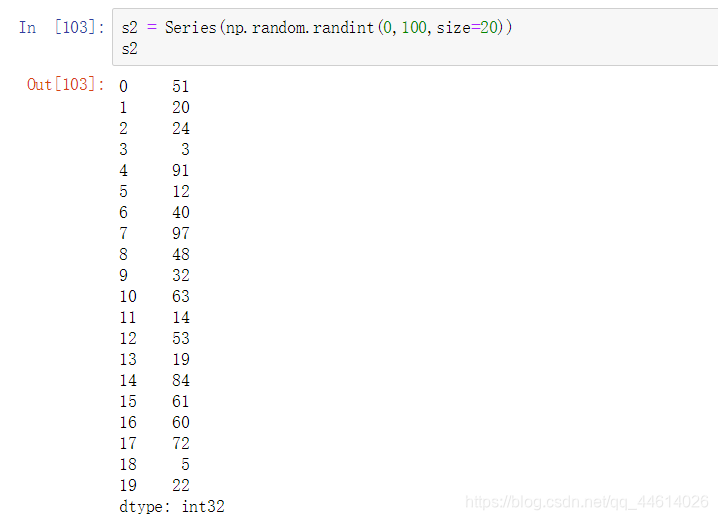
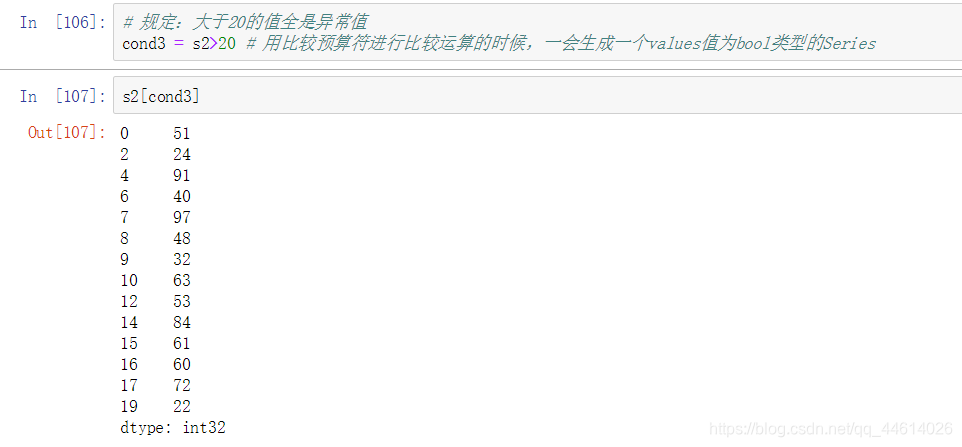
规定:大于20的值全是异常值
用比较预算符进行比较运算的时候,一会生成一个values值为bool类型的Series,将异常值输出
5、Series之间运算
分别创建两个Series对象s1,s2
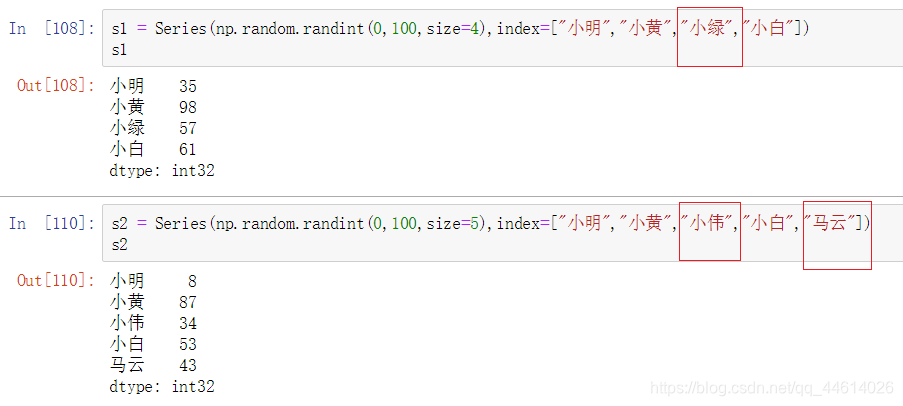
自动补全机制:
两个Series进行算术运算的时候,如果索引有不一致的地方,首先将两个Series中不一致的索引对应的值补NaN
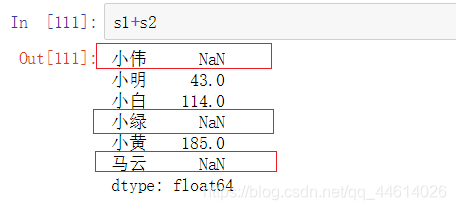
可以看到,只有名字同时在两个对象中的数字进行了相加,其他的都变为了NaN
拓展
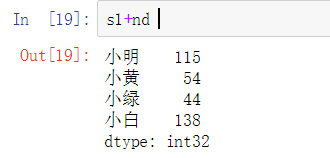
Series和ndarray的运算实际上就是那Series的values部分和ndarray进行运算
Series和数组之间的加减:
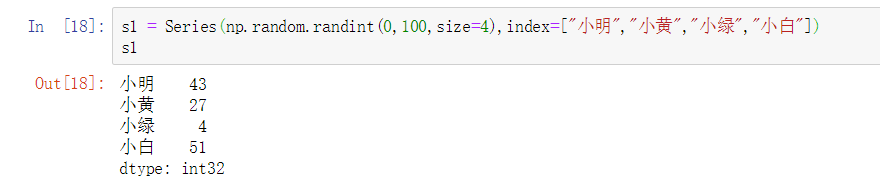
Series对象s1
数组nd
结果
















 7197
7197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









