






一、正则表达式概念
1、正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为regex、regexp 或 RE正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持正则表达式,例如 Linux 系统中常见的文本处理器(grep、egrep、sed、awk)以及应用比较广泛的 Python 语言。正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。
2、正则表达式用途
对于一般计算机用户来说,由于使用到正则表达式的机会不多,所以无法体会正则表达式的魅力,而对于系统管理员来说,正则表达式则是必备技能之一。
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败""服务启动失败"等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
目前很多软件也支持正则表达式,最常见的就是邮件服务器。在Interet中,垃圾/广告邮件经常会造成网络塞车,如果在服务器端就将这些问题邮件提前剔除的话,客户端就会减少很多不必要的带宽消耗。而目前常用的邮件服务器 postfix 以及支持邮件服务器的相关分析软件都支持正则表达式的对比功能。将来信的标题、内容与特殊字符串进行对比,发现问题邮件就过滤掉。
除邮件服务器之外,很多服务器软件都支持正则表达式。虽然这些软件都支持正则表达式,不过字符串的对比规则还需要系统管理员来添加,因此正则表达式是系统管理员必须掌握的技能之一。
二、基础正则表达式
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用正则表达式最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep与 awk 支持扩展正则表达式。掌握基础正则表达式的使用方法,首先必须了解基本正则表达式所包含元字符的含义,下面通过grep 命令以举例的方式逐个介绍。
1.基础正则表达式示例
下面的操作需要提前准备一个名为 test.txt 的测试文件,文件具体内容如下所示。


(1)查找特定字符
查找特定字符非常简单,如执行以下命令即可从 test.txt 文件中查找出特定字符“the”所在位置。其中“-n"表示显示行号、“-i"表示不区分大小写。命令执行后,符合匹配标准的字符,字体颜色会变为红色(本章中全部通过加粗显示代替)。

若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v"选项实现,并配合“-n”一起使用显示行号。

(2)利用中括号“口”来查找集合字符
想要查找“shirt”与"short”这两个字符串时,可以发现这两个字符串均包含“sh"与“rt"。此时执行以下命令即可同时查找到"shirt"与"short"这两个字符串,其中“!"中无论有几个字符,都仅代表一个字符,也就是说“[io]"表示匹配“i”或者“o”

若要查找包含重复单个字符“oo”时,只需要执行以下命令即可

若查找“o0”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]"来实现该目的。例如执行“grep -n'[^w]oo'test.txt"命令表示在 test.txt 文本中查找“00"前面不是"w"的字符串

在上述命令的执行结果中发现“woood”与"wooooood”也符合匹配规则,二者均包含“w”其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知,“#woood #”中加粗显示的是“000”,而“o0”前面的“o”是符合匹配规则的。同理“#woooooood #”也符合匹配规则。
若不希望“00”前面存在小写字母,可以使用“grep -n'[^a-z]oo'test.txt”命令实现,其中'a-z"表示小写字母,大写字母则通过“A-Z”表示。

查找包含数字的行可以通过“grep -n'[0-9]'test.txt”命令来实现。

(3)查找行首 “^” 与行尾字符 “$”
基础正则表达式包含两个定位字符:“^” (行首) 与 “$” (行尾) 。 在上面的示例中,查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为首的行,则可以通过“^”元字符来实现。

查询以小写字母开头的行可以通过“^[a-z]"规则来过滤,查询大写字母开头的行则使用“^[A-Z]"规则,若查询不以字母开头的行则使用“^[^a-zA-Z]”规则。


"^”符号在元字符集合“"”"符号内外的作用是不一样的,在“”符号内表示反向选择,在"[符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。例如,执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.)在正则表达式中也是一个元字符(后面会讲到),所以在这里需要用转义字符""将具有特殊意义的字符转化成普通字符。

当查询空白行时,执行“grep -n“$'test.txt”命令即可。

(4)查找任意一个字符“.”与重复字符“*”
前面提到,在正则表达式中小数点(.)也是一个元字符,代表任意一个字符。例如执行以下命令就可以査找“w??"的字符串,即共有四个字符,以 w开头 d结尾。


在上述结果中,“wood"字符串"w..d”匹配规则。若想要査询 00、000、00000 等资料,则需要使用星号(*)元字符。但需要注意的是,"*”代表的是重复零个或多个前面的单字符"o*"表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep-n'o” test.txt”命令会将文本中所有的内容都输出打印。如果是“oo*”,则第一个o必须存在,第二个o则是零个或多个 0,所以凡是包含 0、00、000、000,等的资料都符合标准。同理,若查询包含至少两个0以上的字符串,则执行“grep -n'ooo*test.txt”命令即可。

查询以w开头d结尾,中间包含至少一个o的字符串,执行以下命令即可实现。

执行以下命令即可查询以w开头d结尾,中间的字符可有可无的字符串

执行以下命令即可查询任意数字所在行。

(5)查找连续字符范围“{}
在上面的示例中,使用了".”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个o的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}"在 Shel 中具有特殊意义,所以在使用“”字符时,需要利用转义字符"",将““"字符转换成普通字符。"{"字符的使用方法如下所示。
① 查询两个o的字符。

查询以w开头以 d结尾,中间包含2~5个o的字符串:

查询以w开头以d结尾,中间包含2个或2个以上o的字符串。


2.元字符总结
通过上面几个简单的示例,可以了解到常见的基础正则表达式的元字符主要包括以下几个,如表所示。

三、 扩展正则表达式
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。例如,使用基础正则表达式查询除文件中空白行与行首为“#之外的行(通常用于査看生效的配置文件),执行“grep -v^$'test.txt |grep -v^#"”即可实现。这里需要使用管道命令来搜索两次。如果使用扩展正则表达式,可以简化为“egrep-v^$|^#'test.txt”,其中,单引号内的管道符号表示或者(or)
此外,grep命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用egrep或 awk 命令。awk 命令在后面的小节进行讲解,这里我们直接使用 egrep 命令。egrep 命令与 grep 命令的用法基本相似。egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。
与基础正则表达式类型相同,扩展正则表达式也包含多个元字符,常见的扩展正则表达式的元字符主要包括以下几个,如表所示。

三、1、 文本处理器
在 Linux/NIX 系统中包含很多种类的文本处理器或文本编辑器,其中包括我们之前学习过的 VIM 编辑器与 grep 等。而 grep,sed,awk 更是 Shell 编程中经常用到的文本处理工具被称之为 Shell 编程三剑客。
三.2 sed 工具
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于 Shel 脚本中,用以完成各种自动化处理任务。
sed 的工作流程主要包括读取、执行和显示三个过程。
-
读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
-
执行:默认情况下,所有的sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
-
显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
1.sed 命令常见用法
通常情况下调用 sed 命令有两种格式,如下所示。其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,"分隔:而 scriptfile 表示脚本文件,需要用“-f选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。

常见的 sed 命令选项主要包含以下几种。
-
-e或--expression=:表示用指定命令或者脚本来处理输入的文本文件
-
-f或--file=:表示用指定的脚本文件来处理输入的文本文件。
-
-h或--help:显示帮助。
-
-n、--quiet或silent:表示仅显示处理后的结果
-
-i:直接编辑文本文件。
“操作”用于指定对文件操作的动作行为,也就是sed 的命令。通常情况下是采用的“[n1[,n2]]"操作参数的格式。n1、n2 是可选的,代表选择进行操作的行数,如操作需要在 5~20 行之间进行,则表示为“5,20动作行为”。常见的操作包括以下几种。
-
a:增加,在当前行下面增加一行指定内容。
-
c:替换,将选定行替换为指定内容。
-
d:删除,删除选定的行。
-
i:插入,在选定行上面插入一行指定内容。
-
p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCI 码输出。其通常与“-n”选项一起使用。
-
s:替换,替换指定字符。
-
y:字符转换。
2.用法示例
在本小节中依旧以 test.txt 文件为例进行演示。
(1)输出符合条件的文本(p表示正常输出)

替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到s(字符串替换)、c(整行/整块替换)、y字符转换)命令选项,常见的用法如下所示。


迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数:
具体操作方法如下所示。

四、 awk 工具
1.awk 常见用法
通常情况下 awk 所使用的命令格式如下所示,其中,单引号加上大括号"。”用于设置对数据进行的处理动作。awk可以直接处理目标文件,也可以通过“-f"读取脚本对目标文件进行处理。

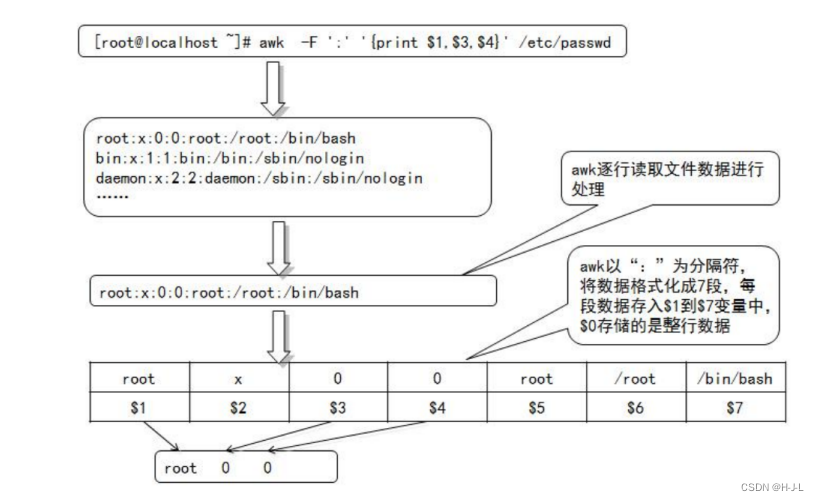
awk 从输入文件或者标准输入中读入信息,与sed 一样,信息的读入也是逐行读取的。不同的是 awk 将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字段(域)。为了操作这些不同的字段,awk 借用 shell 中类似于位置变量的方法,用$1、$2、$3...顺序地表示行(记录)中的不同字段。另外 awk用$0 表示整个行(记录)不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk 允许在命令行中用“-F 分隔符”的形式来指定分隔符。在上述示例中,awk 命令对/etc/passwd 文件的处理过程如图所示。
awk 包含几个特殊的内建变量(可直接用)如下所示:
-
FS:指定每行文本的字段分隔符,默认为空格或制表位。
-
NF:当前处理的行的字段个数。
-
NR:当前处理的行的行号(序数)。
-
$0:当前处理的行的整行内容。
-
$n:当前处理行的第n个字段(第n列)
-
FILENAME:被处理的文件名。
-
RS:数据记录分隔,默认为\n,即每行为一条记录。
2.用法示例
(1)按行输出文本

sort 工具
在 Linux 系统中,常用的文件排序工具有三种:sort、unig、wc。本章将介绍前两种工具的用法。
sor 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如数据和字符的排序就不一样。sort 命令的语法为"sort [选项]参数”,其中常用的选项包括以下几种。
-
-f:忽略大小写;
-
-b:忽略每行前面的空格;
-
-M:按照月份进行排序;
-
-n:按照数字进行排序:
-
-r:反向排序;
-
-u:等同于 unig,表示相同的数据仅显示一行;
-
-t:指定分隔符,默认使用[Tab]键分隔;
-
-0<输出文件>:将排序后的结果转存至指定文件;
-
-k:指定排序区域。





























 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









