






说明:使用从官方下载的 ES/Kibana 来本地安装部署,要跟本地java版本匹配。
1.检查自己是否成功安装Java
#java -version

2.安装es
将下载的安装包解压,另外两台机器相同的步骤操作
#解压
tar xzvf elasticsearch-7.6.2-linux-x86_64.tar.gz
#重命名
mv elasticsearch-7.6.2 es-node1
(另外两台机器重复操作)2.1 创建用户
由于es的特性,需要创建新用户
useradd es #新增用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /home/es/es-node1 #文件夹所有者
chown -R es:es /home/es/es-node2 #文件夹所有者
chown -R es:es /home/es/es-node3 #文件夹所有者
#给最高权限
chmod 775 文件名查看文件权限,是否修改成功
2.2 修改每个节点的es配置文件
修改/home/es/es-node1/config/elasticsearch.yml
# 加入如下配置
##集群名称
cluster.name: cluster-es
###节点名称, 每个节点的名称不能重复
node.name: node-1
###是不是有资格主节点
node.master: true
node.data: true
##ip 地址,填入每个节点的ip
network.host: 192.168.1.1
## 设置对外服务的http端口,默认为9200
http.port: 9200
### 设置节点间交互的tcp端口,默认是9300
transport.port: 9300
##下面修改成自己服务器的目录
path.data: /home/es/es-node1/esdata/data
path.logs: /home/es/es-node1/esdata/logs
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts:["192.168.1.1:9300", "192.168.1.2:9300","192.168.1.3:9300"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
# head 插件需要这打开这两个配置
http.cors.enabled: true
http.cors.allow-origin: "*"2.3 修改每个节点的配置文件
修改/etc/security/limits.conf
# 配置 es 用户打开文件最大数
#(因为es在启动时调用的文件超出普通用户默认打开文件最大数4096,会导致报错)
# 在文件末尾中增加下面内容
es soft nofile 65536
es hard nofile 65536修改/etc/security/limits.d/20-nproc.conf
# 修改单个用户能打开的线程数
# 在文件末尾中增加下面内容
es soft nofile 65536
es hard nofile 65536
* hard nproc 4096
# 注: * 代表 Linux 所有用户名称修改/etc/sysctl.conf
# 系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
# 在文件中增加下面内容
vm.max_map_count=655360
# 重新加载 sysctl -p
查看是否生效
ulimit -Hn2.4 测试集群
分别在不同节点上启动 ES 软件, 一定要切换到es账户
# 切换用户 su es
cd /home/es/es-node2/bin
#启动
./elasticsearch测试启动情况
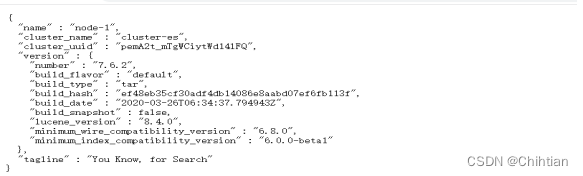
curl -XGET 192.168.1.1:9200/_cat/nodes访问页面http://192.168.1.1:9200
3. 配置https链接
后续更新。。。
4.安装kibana
注意:版本与ES对应
下载地址:https://www.elastic.co/cn/downloads/past-releases
4.1 解压文件
tar xzvf kibana-7.6.2-linux-x86_64.tar.gz4.2 配置文件
编辑配置文件config.xml
# 指定Kibana服务器监听的端口,默认5601
server.port: 5601
# 绑定的主机地址
server.host: "192.168.1.1"
# 连接到的Elasticsearch节点的地址列表
elasticsearch.hosts: ["http://192.168.1.1:9200","http://192.168.1.2:9200","http://192.168.1.3:9200"]
# 通信的请求超时时间
elasticsearch.requestTimeout: 60000
# 指定Kibana界面的语言为中文
i18n.locale: "zh-CN"4.3 启动Kibana
Kibana不能使用root用户启动:
解决方案是:1.用root启动 在后面加上 --allow-root
2.切换用户
创建用户和群组
因此需要创建一个名为 “es” 的用户和一个名为 “es” 的群组,然后将用户添加到该群组中:
# 新建群组
es groupadd es
# 新建用户es并指定群组为
es useradd -g es es
# 设置用户密码
passwd 123456
# usermod 将用户添加到某个组
group usermod -aG root es
安装目录赋权
chown -R es:es /home/kibana/kibana
进入到安装目录后,使用以下命令启动Kibana:
su es ./bin/kibana















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









