






准备
python爬虫需要安装的相关库
python爬虫涉及的库有:
请求库,解析库,存储库,工具库
请求库
urllibr:模拟浏览器发送请求的库,Python自带
re:re库是Python的标准库,主要用于字符串匹配
requests:requests是python实现的最简单易用的HTTP库
selenium:selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截 屏,或者判断网站上某些动作是否发生。
其中 urllib,re库python自带
检查库
命令提示符中进行。win+r 输入 cmd ……

安装requests
pip install requests
出错!
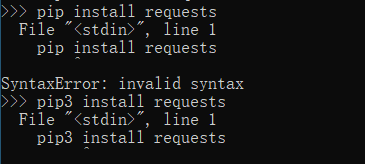
退出python,在提示符中输入指令

报错!
.ReadTimeoutError: HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.

因为服务器在国外的原因,国内下载可能会超时。设置一下timeout时间

输入如下命令
pip3 install requests --timeout 1000

成功显示:
Successfully installed certifi-2020.4.5.1 chardet-3.0.4 idna-2.9 requests-2.23.0 urllib3-1.25.9
安装selenium
吸取安装requests库的经验,输入下面的代码
pip3 install selenium --timeout 1000

接下来安装我需要的Chrome dirver
下载链接:
地址1
地址2
下载成功并运行

把 exe 文件放置到如下位置之一:(只要这个位置在系统设置的环境变量下面都可以,不一定要在下面引用的这两个位置)

chrome 的安装目录(eg:C:\Program Files (x86)\Google\Chrome\Application)
Python 的安装目录的scripts目录下面(因为python要用,然后这个目录又有很多类似的文件,所以放在这里很合理)
不知道python的安装目录的可以执行一下
where python
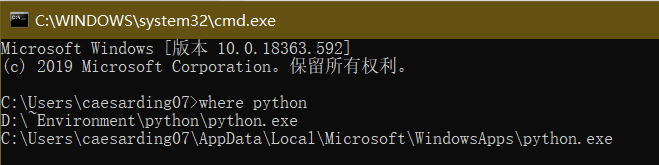

安装完成验证一下
import selenium
from selenium import webdriver
driver = webdriver.Chrome()

安装成功
ps:安装其他浏览器可以参考一开始的链接
解析库
lxml
lxml使用xpath选择器
lxml是一个Python库,使用它可以轻松处理XML和HTML文件,还可以用于web爬取。市面上有很多现成的XML解析器,但是为了获得更好的结果,开发人员有时更愿意编写自己的XML和HTML解析器。这时lxml库就派上用场了。这个库的主要优点是易于使用,在解析大型文档时速度非常快,归档的也非常好,并且提供了简单的转换方法来将数据转换为Python数据类型,从而使文件操作更容易。
# 安装lxml
pip3 install lxml==3.6.0
如果上面的下载不了,可以试试下面的换地址下载
pip install -i https://pypi.douban.com/simple lxml
ps:python3安装lxml库需要指定版本。参考
beautifulsoup
BeautifulSoup使用CSS选择器
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
|
|
| lxml XML 解析器 |
|
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
pyquery
pip3 install pyquery
pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档。
存储库
pymysql
将数据存储到MySQL中,需要借助PyMySQL来操作。
pip3 install pymysql
pymongo
和MongoDB进行交互,需要借助PyMongo库。
pip3 install pymongo
redis
操作redis数据库,需要使用redis库
pip3 install redis
工具库
flask
Flask是一个使用 Python 编写的轻量级 Web 应用框架
Django
Django 是用Python开发的一个免费开源的Web框架。
jupyter
Jupyter Notebook是一个Web应用程序,允许您创建和共享包含实时代码,方程,可视化和说明文本的文档。
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











