






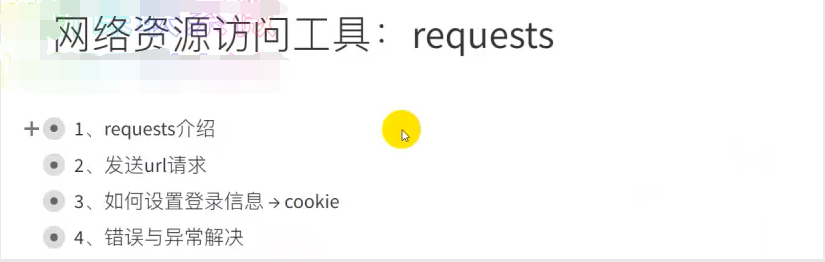
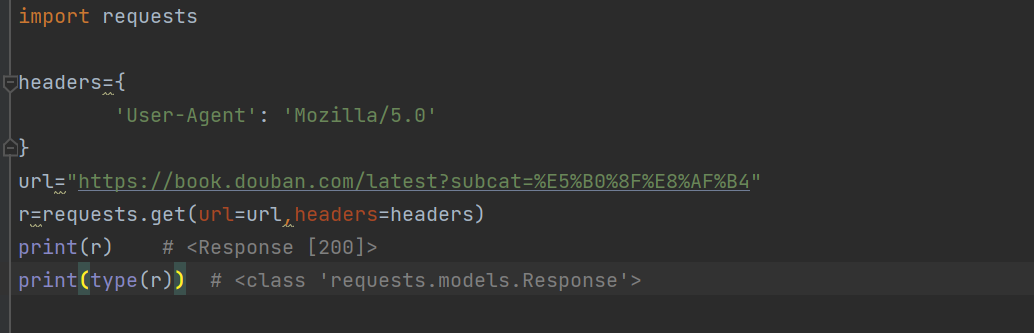

import requests
headers={
'User-Agent': 'Mozilla/5.0'
}
url="https://book.douban.com/latest?subcat=%E5%B0%8F%E8%AF%B4"
r=requests.get(url=url,headers=headers)
print(r) # <Response [200]>
print(type(r)) # <class 'requests.models.Response'>
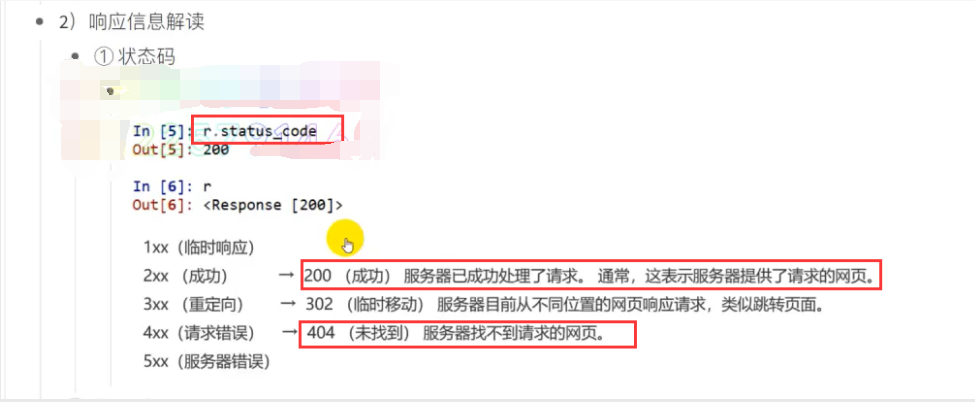
print(r.status_code) # 200
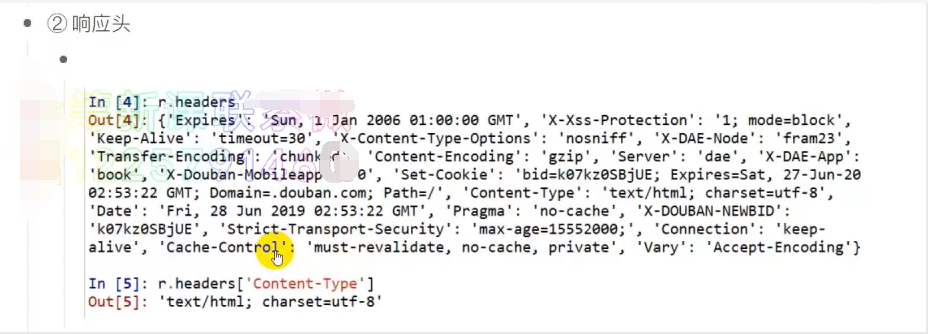
print(r.headers)
print(r.headers['pragma']) # no-cache
print(r.text) # 查看网页源代码
print(r.encoding) # utf-8
print(r.apparent_encoding) # utf-8 查看真实编码
'''
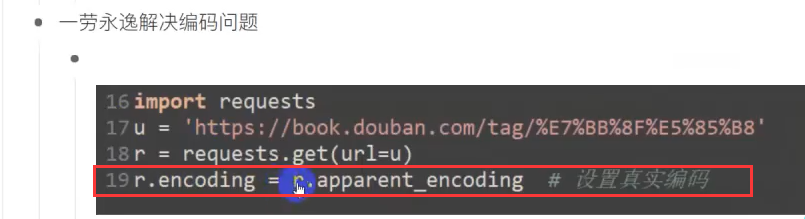
如果遇到真实编码,加上这一句就可以:
r.encoding=r.apparent_encoding # 设置真实编码
'''
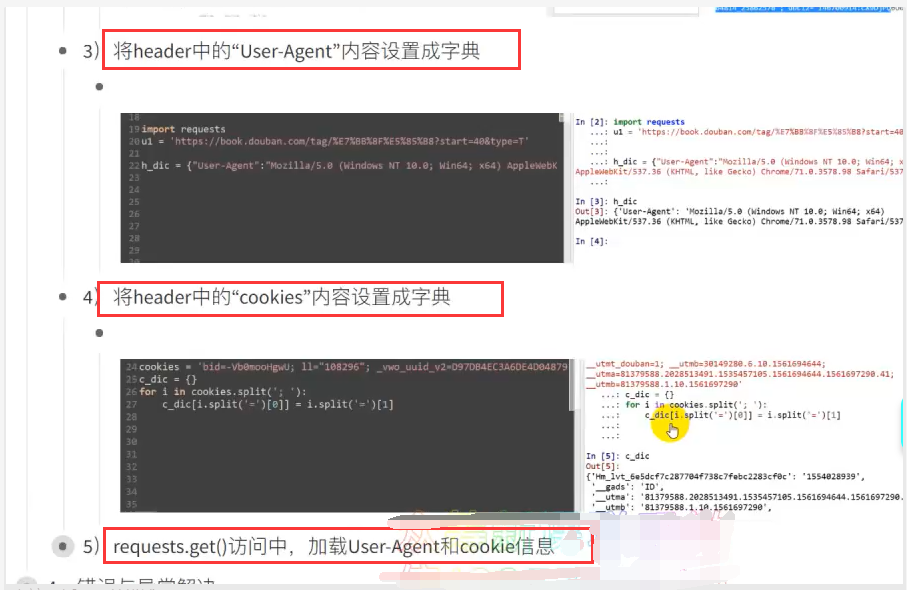
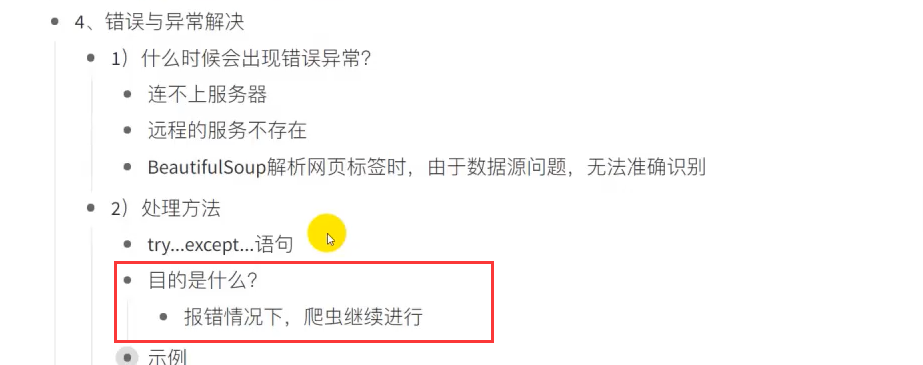
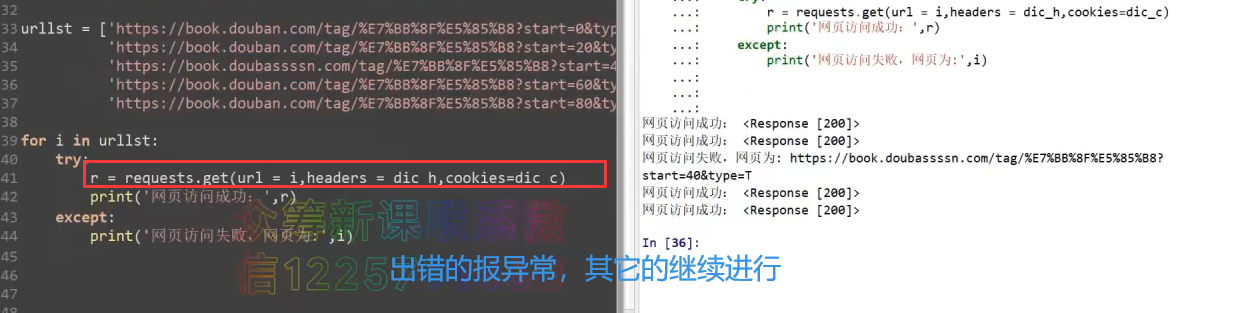
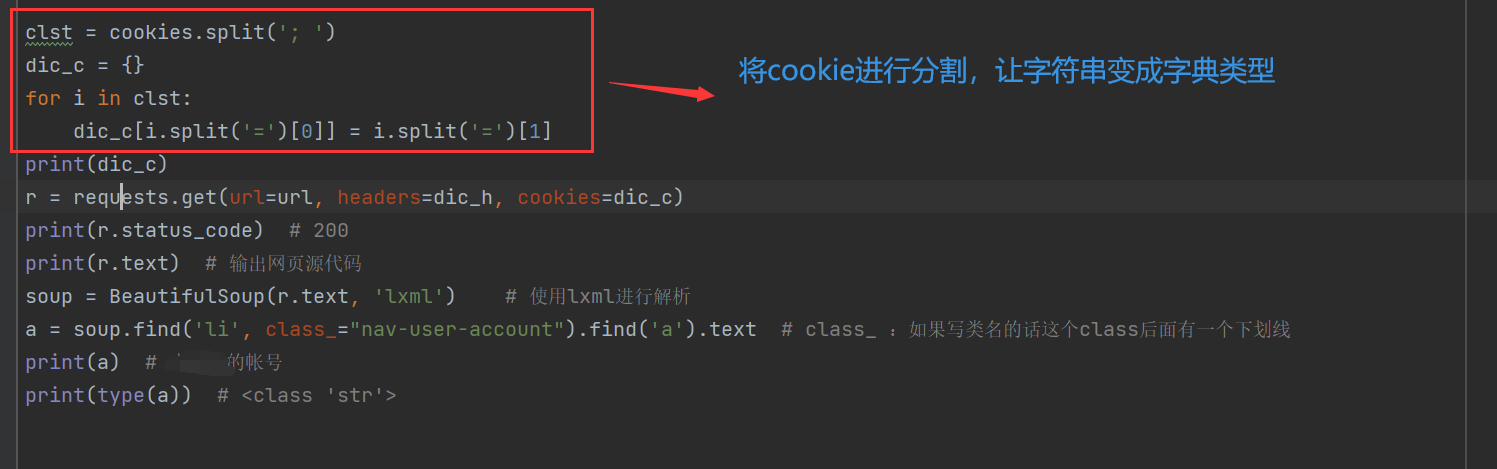
clst = cookies.split('; ')
dic_c = {}
for i in clst:
dic_c[i.split('=')[0]] = i.split('=')[1]
print(dic_c)
r = requests.get(url=url, headers=dic_h, cookies=dic_c)
print(r.status_code) # 200
print(r.text) # 输出网页源代码
soup = BeautifulSoup(r.text, 'lxml') # 使用lxml进行解析
a = soup.find('li', class_="nav-user-account").find('a').text # class_ :如果写类名的话这个class后面有一个下划线
print(a) # 赤~~的帐号
print(type(a)) # <class 'str'>















 8613
8613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









