






前言
这篇文章,来爬好看的电脑壁纸。还是使用python来进行爬虫。感觉使用python爬很方便。为什么又写爬虫呢,因为我又发现了一个好看的免费的壁纸网站。

目标网站:https://desk.3gbizhi.com/
我是打算获取首页18种类型的所有壁纸。

思路
- 获取18种类型的url和图片总数量
- 处理分页,遍历获取,遍历18个url下的每张缩略图片的详情url
- 获取图片详情页面的图片的url或者下载链接

代码
获取18种类型的url和图片总数量
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/106.0.0.0 Safari/537.36 '
}
# 获取18种类型的url和图片总数量
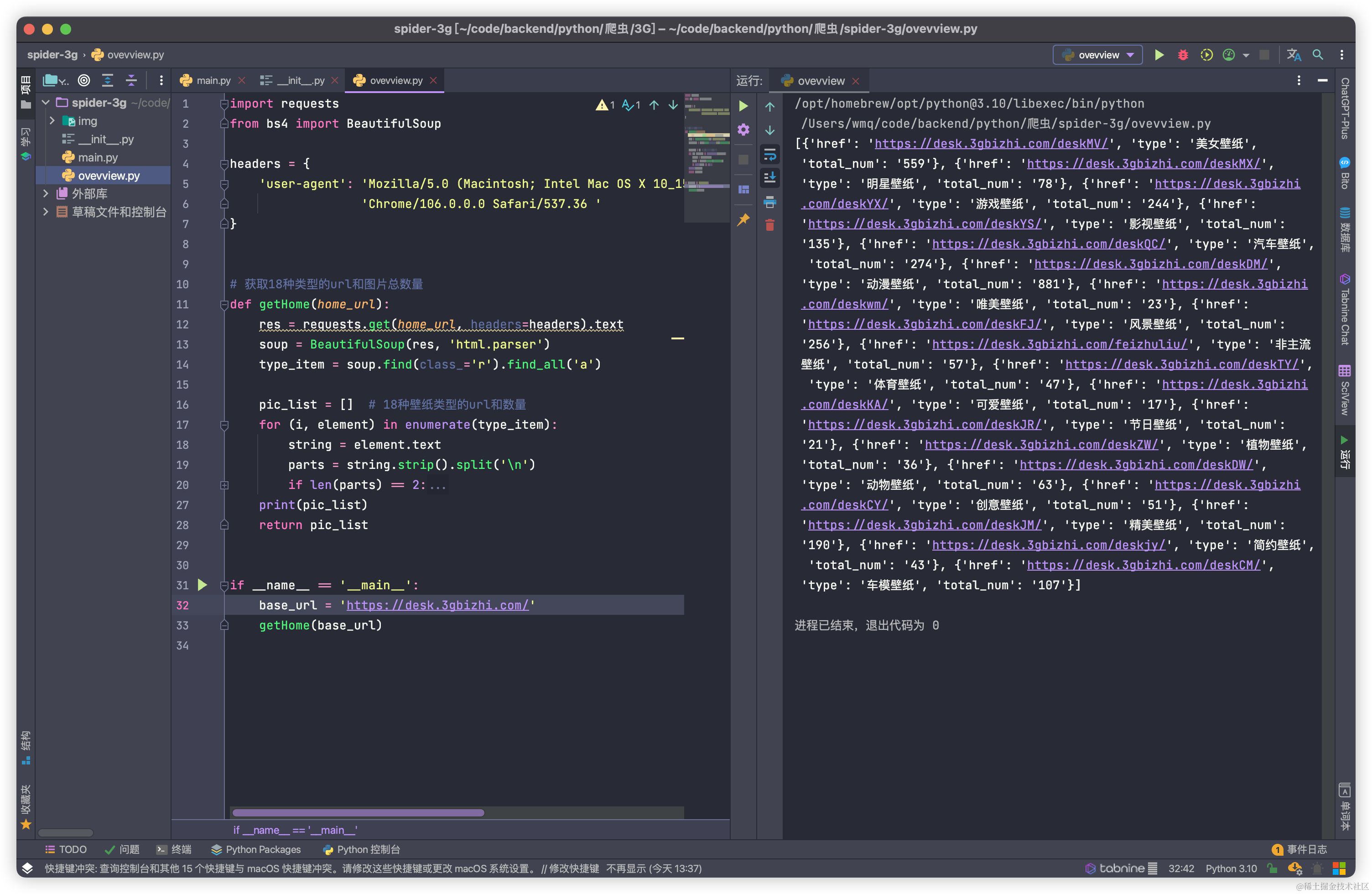
def getHome(home_url):
res = requests.get(home_url, headers=headers).text
soup = BeautifulSoup(res, 'html.parser')
type_item = soup.find(class_='r').find_all('a')
pic_list = [] # 18种壁纸类型的url和数量
for (i, element) in enumerate(type_item):
string = element.text
parts = string.strip().split('\n')
if len(parts) == 2:
name, count = parts[0], parts[1].strip('()张')
pic_list.append({
"href": element.get('href'),
"type": name,
"total_num": count,
})
print(pic_list)
return pic_list
if __name__ == '__main__':
base_url = 'https://desk.3gbizhi.com/'
getHome(base_url)
遍历18个url获取每张缩略图片的详情url
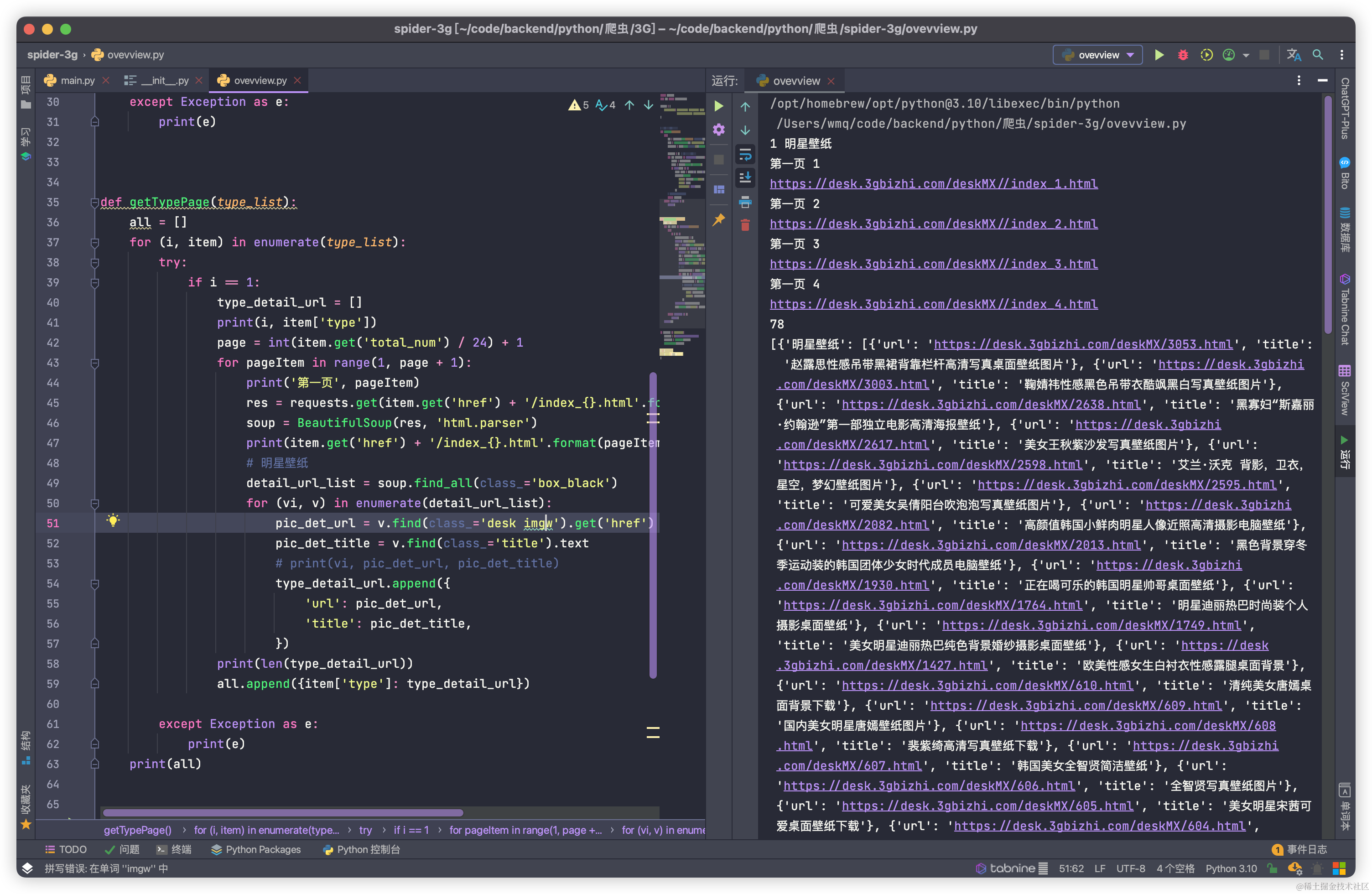
def getTypePage(type_list):
all = []
for (i, item) in enumerate(type_list):
try:
# if i == 1:
type_detail_url = []
print(i, item['type'])
page = int(item.get('total_num') / 24) + 1
for pageItem in range(1, page + 1):
print('第一页', pageItem)
res = requests.get(item.get('href') + '/index_{}.html'.format(pageItem), headers=headers).text
soup = BeautifulSoup(res, 'html.parser')
print(item.get('href') + '/index_{}.html'.format(pageItem))
# 明星壁纸
detail_url_list = soup.find_all(class_='box_black')
for (vi, v) in enumerate(detail_url_list):
pic_det_url = v.find(class_='desk imgw').get('href')
pic_det_title = v.find(class_='title').text
# print(vi, pic_det_url, pic_det_title)
type_detail_url.append({
'url': pic_det_url,
'title': pic_det_title,
})
print(len(type_detail_url))
all.append({item['type']: type_detail_url})
except Exception as e:
print(e)
print(all)
获取详情页面里面的图片
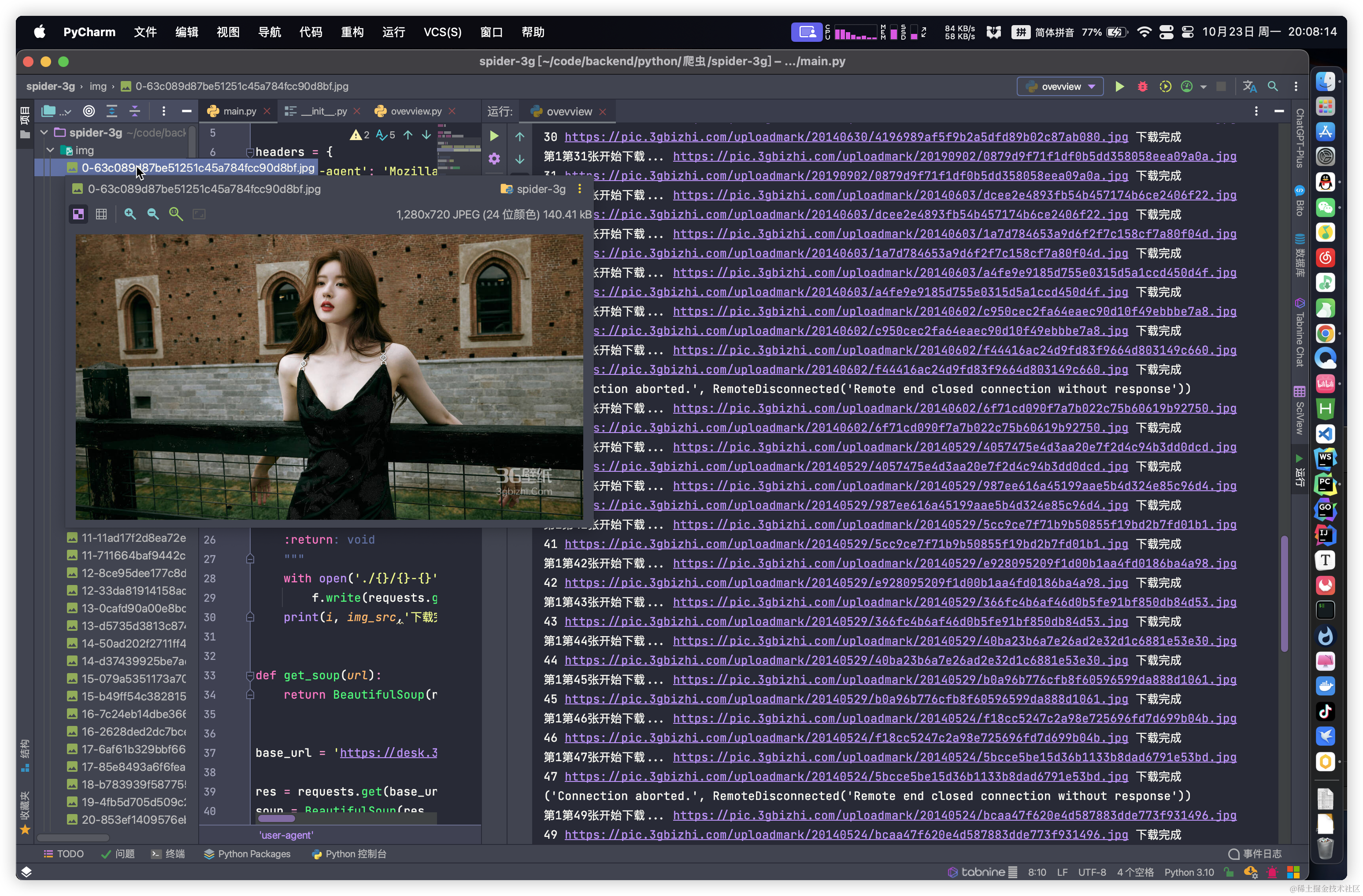
先说思路,把获取到的18种类型的缩略图遍历,先遍历类型再遍历类型里面的缩略图。获取图片详情里面的图片的src地址即可,然后调用写好的图片下载方法就可以把图片下载到本地了
直接上代码
def getDetail(all):
for (i, item) in enumerate(all):
for (son, el) in enumerate(item):
try:
res = requests.get(el.get('url'), headers=headers).text
soup = BeautifulSoup(res, 'html.parser').find(class_='wallphotos').find('img').get('src')
print('第{}第{}张开始下载...'.format(i+1, son), soup)
download_img(soup,son)
except Exception as e:
print(e)
以上就是,整个的壁纸爬虫过程了,代码不过百行,是不是感觉很简单。不过我爬取的不是真正的原图,哈哈哈偷了一下懒,真正的原图要获取下载按钮里面的下载链接。这个网站做了一些反扒机制,要获取原图链接是需要点击下载按钮之后才会返回,而且还需要登录。这个稍微麻烦一些,我下期再介绍如何反扒,欲知后事如何,请听下回分解…
最后给出全部完整代码
完整代码
import os
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/106.0.0.0 Safari/537.36 '
}
# 存放下载图片的文件夹名称
new_folder = 'img'
# 获取当前目录
current_dir = os.getcwd()
# 新文件夹的名称
# new_folder = 'img_{}'.format(type_list[type_index]) # 创建新文件夹
if not os.path.exists(new_folder):
os.mkdir(os.path.join(current_dir, new_folder))
def download_img(img_src, i):
"""
图片下载
:param img_src: 图片的src
:param i: 序号
:return: void
"""
with open('./{}/{}-{}'.format(new_folder, i, img_src.split('/')[-1]), 'wb') as f:
f.write(requests.get(img_src).content)
print(i, img_src, '下载完成')
def get_soup(url):
return BeautifulSoup(requests.get(url, headers=headers).text, 'html.parser')
# 获取18种类型的url和图片总数量
def getHome(home_url):
try:
res = requests.get(home_url, headers=headers).text
soup = BeautifulSoup(res, 'html.parser')
type_item = soup.find(class_='r').find_all('a')
pic_list = [] # 18种壁纸类型的url和数量
for (i, element) in enumerate(type_item):
string = element.text
parts = string.strip().split('\n')
if len(parts) == 2:
name, count = parts[0], parts[1].strip('()张')
pic_list.append({
"href": element.get('href'),
"type": name,
"total_num": int(count),
})
# print(pic_list[0])
return pic_list
except Exception as e:
print(e)
def getTypePage(type_list):
all = []
for (i, item) in enumerate(type_list):
try:
if i == 1:
type_detail_url = []
print(i, item['type'])
page = int(item.get('total_num') / 24) + 1
for pageItem in range(1, page + 1):
print('第一页', pageItem)
res = requests.get(item.get('href') + '/index_{}.html'.format(pageItem), headers=headers).text
soup = BeautifulSoup(res, 'html.parser')
print(item.get('href') + '/index_{}.html'.format(pageItem))
# 明星壁纸
detail_url_list = soup.find_all(class_='box_black')
for (vi, v) in enumerate(detail_url_list):
pic_det_url = v.find(class_='desk imgw').get('href')
pic_det_title = v.find(class_='title').text
# print(vi, pic_det_url, pic_det_title)
type_detail_url.append({
'url': pic_det_url,
'title': pic_det_title,
})
# print(len(type_detail_url))
# all.append({item['type']: type_detail_url})
all.append(type_detail_url)
except Exception as e:
print(e)
# print(all)
return all
def getDetail(all):
for (i, item) in enumerate(all):
for (son, el) in enumerate(item):
try:
res = requests.get(el.get('url'), headers=headers).text
soup = BeautifulSoup(res, 'html.parser').find(class_='wallphotos').find('img').get('src')
print('第{}页第{}张开始下载...'.format(i + 1, son), soup)
download_img(soup, son)
except Exception as e:
print(e)
if __name__ == '__main__':
base_url = 'https://desk.3gbizhi.com/'
pic_lists = getHome(base_url)
all1 = getTypePage(pic_lists)
getDetail(all1)
放几张壁纸给大家看看,欣赏一下(虽软不是原图)



















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











