







SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detection
目录
3.3.3 综合推理(Composed Reasoning)
1. 引言
近年来,Deepfake 等媒体操纵技术引发广泛关注,但更常见且易于传播的错误信息形式是 脱离语境错误信息(Out-of-Context Misinformation,OOC),即将真实图片与错误文本配对。例如,在社交媒体上,某些旧照片被用于新的不相关新闻情境,以误导公众认知。
当前研究主要专注于 学习统一的跨模态表征空间 来检测图文一致性,但这些方法大多 缺乏对错误信息的解释能力,这对于提高公众信任度和澄清事实至关重要。多模态大语言模型(MLLMs) 在视觉推理和解释生成方面具有优势,但在检测微妙的跨模态差异方面仍然存在局限性。
为了解决这一问题,本文提出 SNIFFER,一种结合 MLLMs 与外部知识 的可解释 脱离语境错误信息 检测系统。它利用 GPT-4 生成的指令数据进行微调,并通过外部检索增强模型能力,不仅能够检测图文不一致,还能提供准确、清晰的解释。
实验表明,SNIFFER 在检测准确率上超越了现有的最先进方法,尤其在可解释性方面表现突出。

图 1. SNIFFER 与其他检测器的比较。
- 在此脱离语境错误信息示例中,图像中的人物是 Harry Thomas Jr,但图片标题(caption)中描述的内容与之矛盾。现有的检测器通常只给出判断结果,而不提供解释。虽然 InstructBLIP 和 GPT-4V 能够正确识别出图文不一致的元素(即人物),但它们却错误地将图中人物与标题中提到的另一位人物混淆。
- 与此不同,SNIFFER 同时分析 图文内容的一致性 和 文本与证据之间的关联性,成功识别出图像中的人物是 Harry Thomas Jr,并提供了精确且有说服力的解释。
1.1 关键词
多模态大模型(MLLM)、错误信息检测、跨模态不一致、图文匹配、SNIFFER、指令微调、可解释性
2. 相关工作
2.1 脱离语境错误信息检测
当前方法主要依赖以下策略:
- 内部检测(Internal Checking):使用多模态预训练模型(如 CLIP、VisualBERT)检测图文是否匹配。
- 外部检测(External Checking):通过网页检索、知识库等外部资源验证文本和图像的真实性。
然而,大多数方法 只能给出判断,而无法解释理由,使得模型在澄清事实时缺乏公信力。
2.2 MLLM 指令微调
MLLMs 通过 指令微调(Instruction Tuning) 提高任务适应能力。然而,传统的指令微调主要用于一般性视觉语言任务,如图像描述和视觉问答,而 OOC 检测需要更精确的跨模态推理能力。
NIFFER 通过两阶段指令微调,使 MLLM 适应新闻领域和 OOC 任务。
3. 方法
3.1 SNIFFER 模型架构
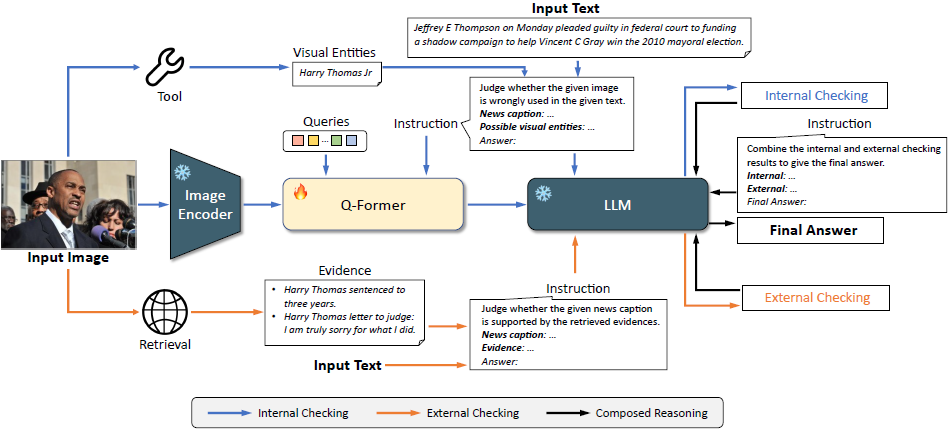
图 2. 提出框架 SNIFFER 的架构。对于给定的图文对,SNIFFER 采用 双重分析策略:
- 内部检测(Internal Checking):检查图像与文本内容之间的语义一致性。
- 外部检测(External Checking):分析通过图像检索获得的证据与给定文本之间的相关性。
SNIFFER 将这两种验证过程的结果进行组合推理(Composed Reasoning),以得出 最终判断 和 解释说明。
SNIFFER 以 InstructBLIP 作为基础模型,该模型包含:图像编码器、Query Transformer(Q-Former)、大语言模型(LLM)
3.2 指令微调
3.2.1 阶段 1:新闻领域对齐
由于 InstructBLIP 主要使用通用名词(如“人”、“男人”),难以区分具体新闻人物。
通过 GPT-4 生成指令数据,使模型能理解新闻事件中的具体实体,提高 OOC 误导信息检测能力。
- 对于图像 I 及其对应的标题 T_c,我们会 随机抽取 一个问题 T_q 来构造相应的指令,如下所示:
![]()
- 在训练过程中,我们保持 图像编码器(Image Encoder) 和 大语言模型(LLM) 不变,仅更新 Q-Former。
- 通过这种方式,新闻领域中的大量视觉概念所对应的图像特征 可以与 预训练 LLM 中的细粒度实体名称的文本嵌入 对齐。
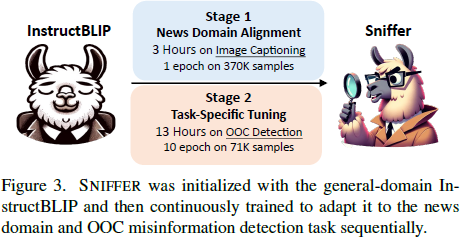
3.2.2 阶段 2:OOC 任务微调
现有数据集缺乏关于图文不一致的详细解释,因此 SNIFFER 采用 GPT-4 生成虚假样本的解释数据。该方法使模型能够 同时学习判断 OOC 误导信息,并生成解释。
NewsCLIPpings 数据集通过以下方式生成虚假样本:
- 将真实图文对中的 img1(即配对中的图片)替换为来自另一个 相似但不同的图文对(cap2, img2)中的 img2,从而构造出一个 伪造图文对(cap1, img2)。
- 尽管这些样本提供了真实性标签,但却 未明确标识 cap1 与 img2 之间的具体不一致之处,而这正是错误信息的关键所在。
为此,我们创新性地通过提示 GPT-4(语言模型) 来识别 cap1 和 cap2 之间的差异。
如图 4 所示:
- 我们将 cap1、cap2 以及 InstructBLIP 生成的 img2 基本描述 输入 GPT-4,提示其生成 cap1 与 img2 之间的不一致信息,模拟 GPT-4 能看到图像的情景(尽管 GPT-4 实际上仅能访问文本)。
- 我们精心设计了 少样本示例(Few-Shot Examples),并对输出格式进行约束,要求其识别 新闻内容中不一致的元素 以及 相关的具体实体。
- 尽管 cap1 和 img2 之间 可能存在多个不一致之处,但为了保证输出的清晰性,我们要求 GPT-4 仅生成最可能的不一致元素。

最终,我们获得了 35,536 个由 GPT-4 辅助生成的跨模态错误信息检测指令,并为真实样本补充了 同样数量的说明性指令(例如:“不,这张图片被正确地用于当前新闻语境。”)。
3.3 推理
为了有效应对 跨模态误导信息(OOC)检测 的挑战,SNIFFER 采用了一个融合 内部验证 和 外部验证 的 综合推理策略,具体如下:
3.3.1 内部验证(Internal Checking)
SNIFFER 通过 两阶段指令微调,具备了识别图文不一致的能力。然而,模型受到训练语料的限制,无法访问最新的新闻信息。
为弥补这一不足,SNIFFER 集成了 Google Entity Detection API 来识别图像中的 视觉实体(Visual Entities),并将识别到的实体作为补充信息加入到指令中,协助模型更精准地判断图文是否一致。
3.2.2 外部验证(External Checking)
除了 图文内部检测 外,外部验证 是确保检测结果可靠的关键环节。如前人研究所指出的,图像的原始新闻背景(context)对识别 OOC 误导信息 极为重要。
- SNIFFER 使用 反向图像搜索(Reverse Image Search) 来检索 图像曾出现过的新闻网页内容。
- 这些网页内容通常揭示了 图像真实的语境,从而可以帮助模型判断给定文本是否描述了该图像的真实背景。
在实际操作中,SNIFFER 将 新闻标题 和 检索到的网页内容 一并输入 大语言模型(LLM),以判断 新闻标题是否被检索到的证据所支持。
3.3.3 综合推理(Composed Reasoning)
内部验证 和 外部验证 从不同角度分析图文对,可能得出不同的结论。
为解决这一潜在分歧,SNIFFER 采用了基于 LLM 的 可解释推理机制:
- 将 内部检测 和 外部检测 的结果,以及 原始新闻标题,再次输入 LLM。
- LLM 会综合各方信息,生成 最终判断 和 解释说明,并明确揭示其推理过程。
4. 性能评估
4.1 主要研究问题
SNIFFER 主要围绕以下问题展开评估:
- 能否提升 OOC 误导信息检测的准确率?
- 不同模块对检测性能的贡献如何?
- SNIFFER 生成的解释是否准确、具有说服力?
- 在数据有限的情况下,SNIFFER 是否仍然有效?
- SNIFFER 在其他数据集上的泛化能力如何?
- SNIFFER 相较于 GPT-4V 的表现如何?
4.2 结果分析
SNIFFER 在检测准确率上超过所有基线模型:比当前最优方法 CCN 高 3.7%
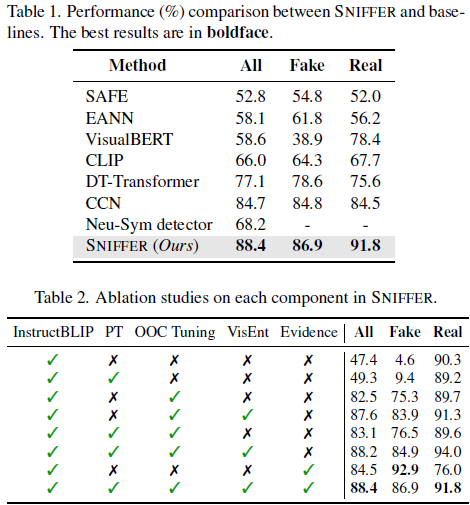
消融实验表明:
- OOC 任务微调对检测能力提升最大(提高 35%)。
- 引入 外部检索工具 使准确率再提升 5%。
解释能力评估:
- SNIFFER 成功识别错误实体。
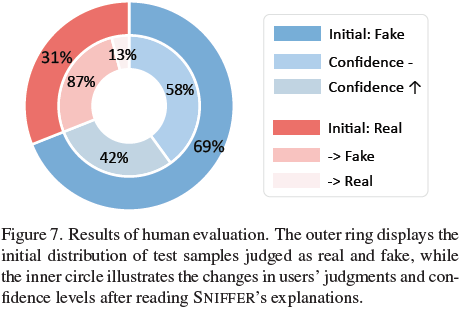
- 人类评估实验显示,SNIFFER 解释能够显著提高用户对错误信息的识别能力(87% 用户在阅读解释后修正判断)。
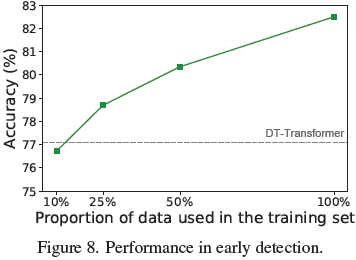
数据有限时的表现:仅使用 10% 训练数据,SNIFFER 仍能达到接近最优模型的表现。
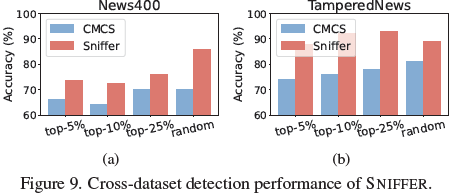
跨数据集泛化能力:在 News400 和 TamperedNews 数据集上均超越 SOTA 方法,证明了较强的泛化能力。
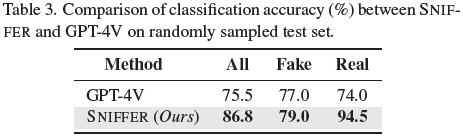
与 GPT-4V (Q6) 的对比:SNIFFER 在分类准确率方面比 GPT-4V 高出 11%。
5. 结论
SNIFFER 是首个基于 多模态指令微调 的 OOC 误导信息检测模型,主要贡献包括:
- 提出了一种基于 GPT-4 生成的指令微调方法,使 MLLM 适应 OOC 误导信息检测
- 结合内部检测(图文一致性)与外部检索(网页证据),提高检测准确率
- 提供详细的可解释性分析,使检测结果更具说服力
SNIFFER 不仅超越现有方法,在 检测准确率、可解释性、训练效率、泛化能力 方面均表现优异,还能 在数据有限的情况下保持高效检测能力,为未来多模态错误信息检测提供了新思路。
未来研究方向:
- 增强外部知识集成:结合 实时新闻数据 提高新事件检测能力。
- 提升实体识别能力:进一步优化图像实体检测,提高 OOC 误导信息的识别精度。
- 跨领域适应:将 SNIFFER 应用于 社交媒体、法律、医疗 等其他需要跨模态信息检测的领域。
论文地址:https://arxiv.org/abs/2403.03170
项目页面:https://pengqi.site/Sniffer/
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









