






import time
import pymysql
import requests
import selenium.common.exceptions
from selenium import webdriver
from lxml import etree
import pandas as pd
jd_browser = webdriver.Chrome('chromedriver.exe')
with open('stealth.min.js', 'r', encoding='utf-8')as f:
js_code = f.read()
jd_browser.get('https://www.jd.com/')
input_jd = jd_browser.find_element_by_id('key')
input_jd.send_keys('创维电视')
cick_job = jd_browser.find_element_by_css_selector('button')
cick_job.click()
jd_browser.implicitly_wait(20)
# 实现滑块滚动,获取动态数据
def drop_down():
for i in range(50):
time.sleep(0.3)
jd_browser.execute_script('window.scrollBy(0,300)', '')
drop_down()
lis = jd_browser.find_elements_by_css_selector('.goods-list-v2 .gl-item')
# print(len(lis))
urls = []
# 获取商品详情页的url
for i in lis:
jd_browser.implicitly_wait(20)
url = i.find_element_by_tag_name('a').get_attribute('href')
urls.append(url)
df = pd.DataFrame(columns=['店铺名称', '品牌', '商品编号', '正式商品名称', '网页商品名称', '商品第一张主图', '京东价', '促销', '优惠券', "累计评价"])
con = pymysql.connect(host='localhost', password='Www.1.com', port=3306, user='root',database='lle_test', charset='utf8')
con.connect()
# 访问每一个详情页的url
for ur in urls:
jd_browser.get(ur)
# 店铺名称
shop_name = jd_browser.find_element_by_xpath('//*[@id="crumb-wrap"]/div/div[2]/div[2]/div[1]/div/a').text
# 品牌
brand = jd_browser.find_element_by_xpath('//*[@id="parameter-brand"]/li').text
# 商品编号
item_number = jd_browser.find_element_by_xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]/li[2]').text
# 正式商品名称
official_trade_name = jd_browser.find_element_by_xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]/li[1]').text
# 网页商品名称
web_product_name = jd_browser.find_element_by_class_name('sku-name').text
# 京东价
jingdong_price = jd_browser.find_element_by_class_name('p-price').text
# 商品第一张主图片
picture = "https:" + jd_browser.find_element_by_xpath('//*[@id="spec-img"]').get_attribute('data-origin')
try:
# # 促销
sales_promotion = jd_browser.find_element_by_xpath('//*[@id="prom"]/div/div').text
# # 优惠券
coupon = "优惠券" + jd_browser.find_element_by_xpath('//*[@id="summary-quan"]/div[2]').text
except selenium.common.exceptions.NoSuchElementException:
sales_promotion = None
coupon = None
# 累计评价
cumulative_evaluation ="累计评价"+jd_browser.find_element_by_css_selector('.itemInfo-wrap .summary-price-wrap .summary-info .count').text
print(shop_name, brand, item_number, official_trade_name, web_product_name, jingdong_price, picture, sales_promotion, coupon ,cumulative_evaluation)
df.loc[len(df.index)] = [shop_name, brand, item_number, official_trade_name, web_product_name, picture,
jingdong_price, cumulative_evaluation] # 将获取到的数据写入到excel中
#
# # 写入到mysql中
sql = f"insert into jd(shop_name, brand, item_number, official_trade_name, web_product_name, jingdong_price, picture_url,sales_promotion,coupon ,cumulative_evaluation) values ('{shop_name}','{brand}','{item_number}','{official_trade_name}','{web_product_name}','{picture}','{jingdong_price}','{sales_promotion}','{coupon}','{cumulative_evaluation}')"
with con.cursor() as cursor:
cursor.execute(sql)
con.commit()
sql2 = "select * from jd"
cursor.execute(sql2)
datas = cursor.fetchall()
# 把数据保存到excel表格中
df.to_excel('京东数据保存.xls', sheet_name="京东数据保存.xls", na_rep="") 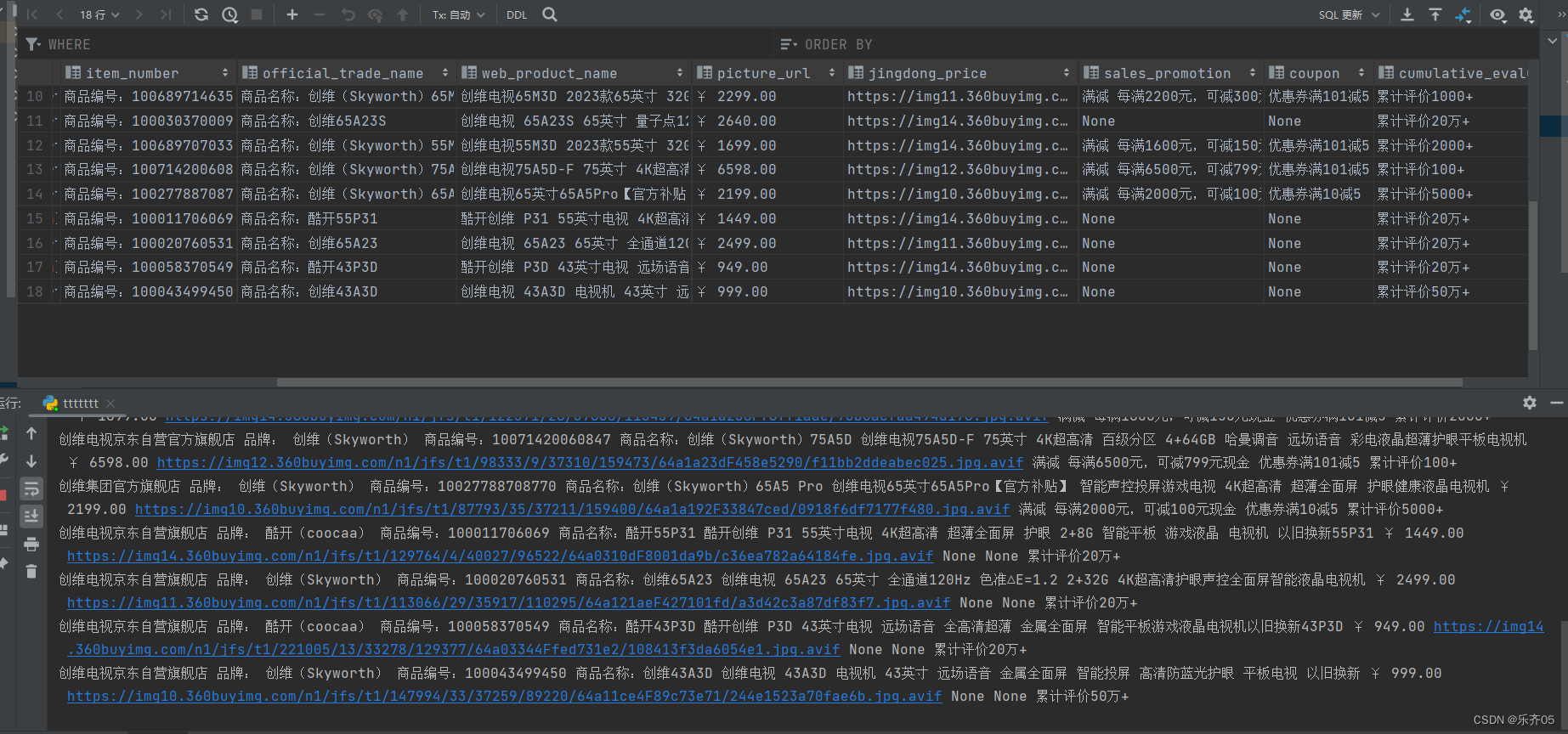















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









